14 May 2025 Simplifying Manual Data Integrations with ODI
Manual files are very common for storing and managing data across multiple business entities; however, as organisations grow, there is an increasing need to migrate these manual files into databases, or to automate the processes that generate them.
In this blog post, we’ll explore some of the typical challenges that are associated with integrating data from manual files into a data warehouse. Using a real business case as an example, we’ll analyse the key issues, present effective solutions, and at the same time demonstrate the power of Oracle technology.
Business Case
Let’s imagine a group of seven business users want to include manual sales data from multiple countries into their current corporate sales reporting model. Each user has to load their own file, and as there is no predefined loading schedule, they’ll submit it as soon as it’s ready.
At first, this might look like a straightforward two-step solution:
- Create a mapping with the files to load and a new target table.
- Incorporate the target table into the already existing sales model.
However, there are a few challenges:
- File and data format inconsistencies among users.
- Data loads and historical data management.
- Data load validation by users.
File and Data Format Inconsistencies Among Users
File and data format inconsistencies among business users are a common challenge, especially if the users operate in different countries. For example, column or decimal separators can change from ‘,’ to ‘.’ and vice versa, which can lead to failed load processes, data loss in the target table, and discrepancies in reports.
To minimise this, we’ll create one or more file templates for all the users: these templates define a uniform file format, including column names, separators, and text delimiters.
In our business case, the templates consist of seven different CSV files, each with its own name, four predefined columns, a semicolon as the field separator, and a dot as the decimal separator.
It’s important to configure a dedicated file and associated datastore for each user, as they will be loading their files independently. Multiple files might be put in the same folder on the same day, and if they share the same filename, Oracle Data Integrator (ODI) will only process one of them. By assigning a unique name and a corresponding datastore to each user’s file in ODI, multiple users can successfully load their data every day:
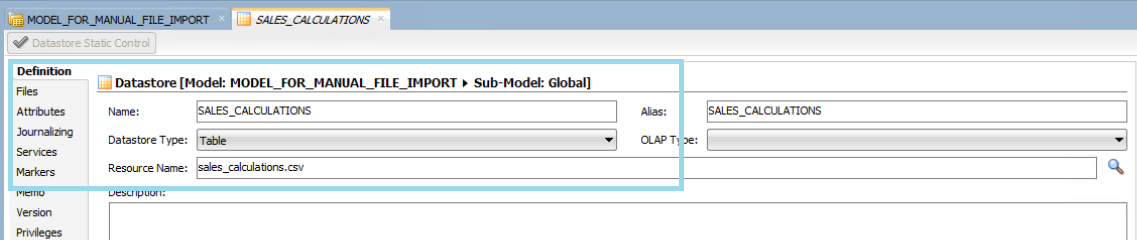
Figure 01: Unique datastore definition in ODI
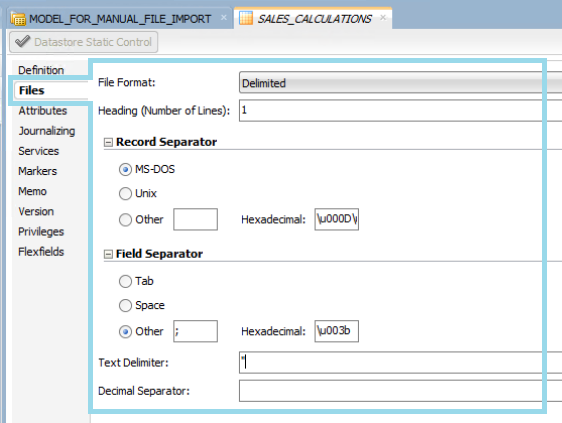
Figure 02: Unique datastore files definition in ODI
Moreover, it’s always good practice to prepare a structured guide for users. This helps to prevent mismatches and potential errors during data integration into the database.
Data Loads and Historical Data Management
Typically, users do not follow a predefined schedule for manual data loads. They often combine new data with existing model records in the same file. To ensure proper data governance, users should be able to track the number of inserted and updated rows and verify the overall accuracy of the data.
To handle this effectively, it is important to manage historical data properly. This enables the correct identification of new records, the detection of rows that need to be updated, and the avoidance of reloading data that already exists.
When it comes to managing historical data, ODI offers multiple Knowledge Modules (KMs) that support storing and tracking data over time. However, when working with a KM, if users attempt to load existing data daily, there are two possible outcomes:
- If the update date field is checked as updatable in ODI, it will be overwritten with the current date during each load. As a result, historical load dates are lost, making it impossible to track data changes over time.
- If the update date field is checked as insert-only, a new row is inserted for each load with the current load date, leading to the daily duplication of records.
There are other ways to approach historical data management, and one effective strategy is to create two date fields in the target table:
- INSERT_DT: Captures when the record was first added.
- UPDATE_DT: Tracks when the record was last modified.
However, simply storing dates is not enough: we also need a way to determine whether a record is new, needs an update, or already exists. A useful approach is to include the target table as part of the ODI mapping and to join it with the incoming file data.
As with any data project, we must keep the solution simple, easy to maintain, and optimised for performance.
Applying This to Our Business Case
A possible implementation involves merging all incoming data from the files into a single branch using the SET component in ODI. This approach is effective because all the files share the same structure, data types, and definitions. If the files contained different formats or data types, additional data cleansing steps, multiple mappings, or separate target tables would be required:
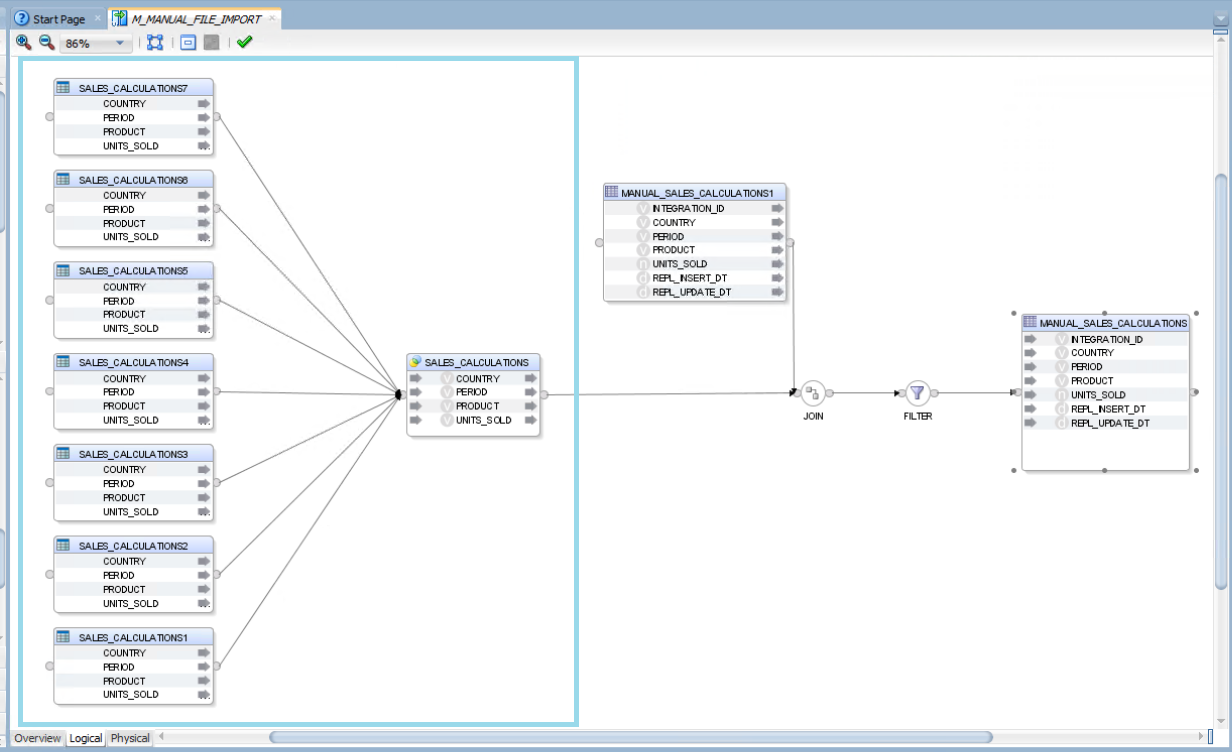
Figure 03: SET component in ODI
Once UPDATE_DT and INSERT_DT are in place, the next step is to join the file data to the target table. By concatenating all columns, excluding the identifier and date fields, we can determine which records are new or have changed.
To enhance performance, the concatenated string can be converted using the ORA_HASH function, which generates a numeric hash value for each unique combination. This reduces processing time whilst preserving comparison accuracy:
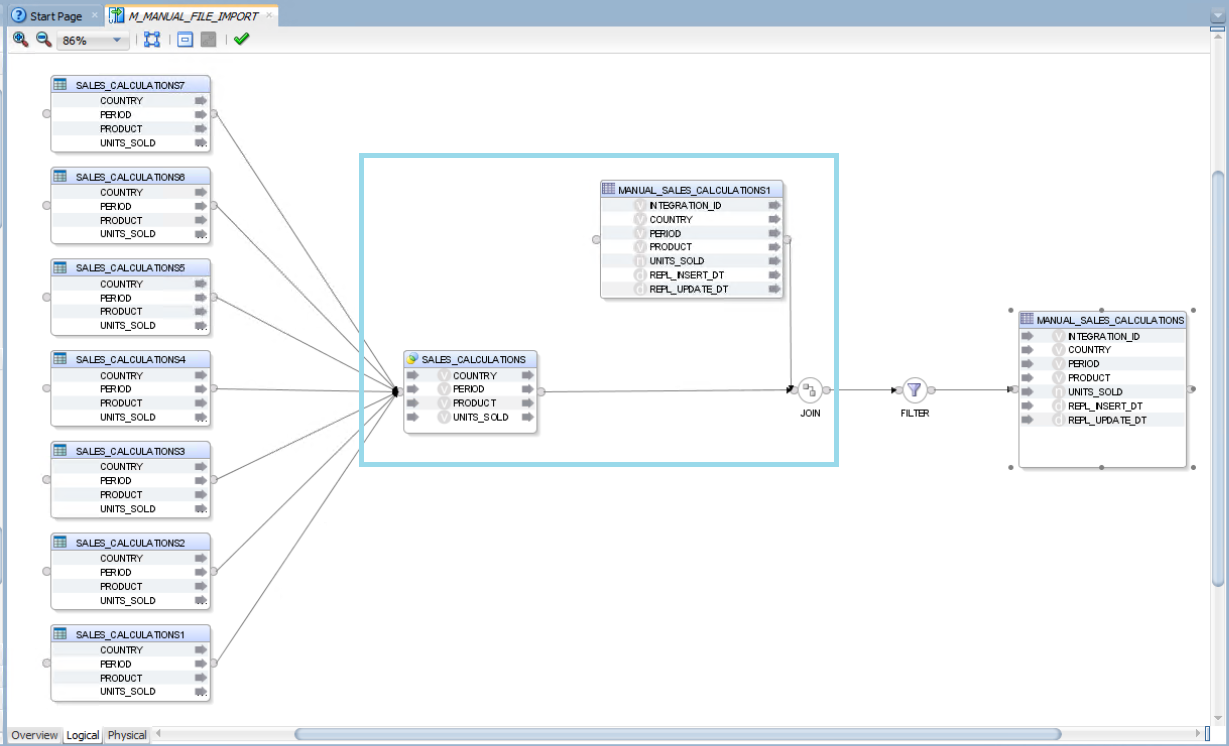
Figure 04: Join target table
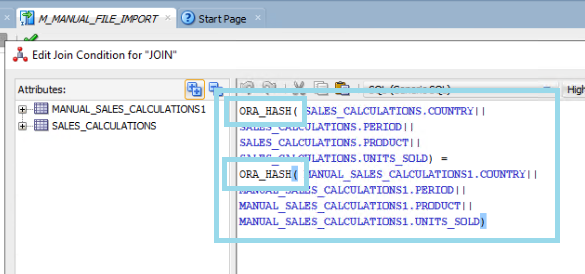
Figure 05: Join detail target table
We can apply a filter after the join to ensure that only the new or updated records are uploaded. The condition must identify which rows do not join with the target table, for instance, when MANUAL_SALES_CALCULATIONS1.INTEGRATION_ID is null.
Finally, we need to define the behaviour of the fields that may be updated in the target table:
- Fields requiring updates should be checked as updatable so that changes are applied.
- The INSERT_DATE field should remain unchanged and checked as insert-only.
- The UPDATE_DT field should be checked as updatable to reflect changes and to maintain data governance.
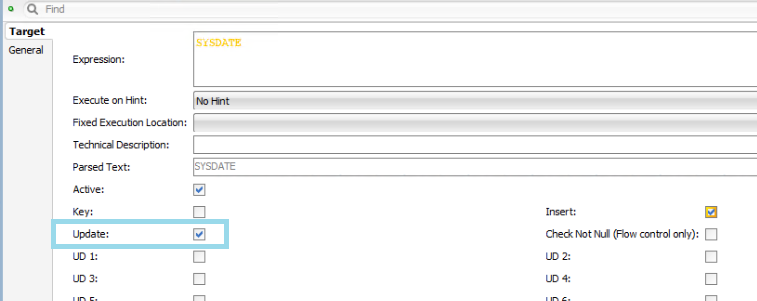
Figure 06: Update option checked
Data Load Validation
With the core solution in place, the next challenge is to ensure that users can verify whether their manual file uploads were successful. As data owners, they are responsible for the integrity and governance of the data. There are several ways users can validate the accuracy of the data load, such as running predefined database queries, reviewing reports with key KPIs, or receiving email notifications.
Email notifications are particularly effective, offering a simple and accessible method to review load status. We recommend implementing a complete ODI solution incorporating procedures and variables, using key fields like UPDATE_DT. The solution consists of:
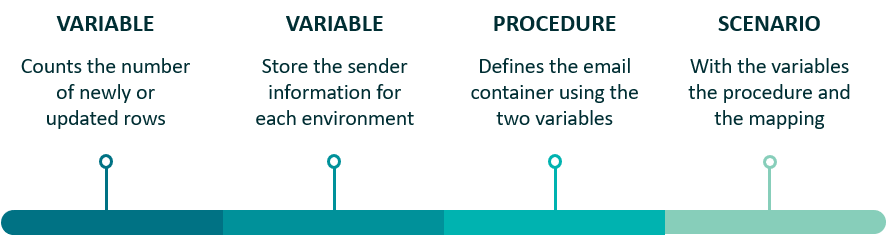
Figure 07: Data load validation process
- Counting the number of newly created or updated rows
It’s important to be able to count the number of rows that have been inserted or updated, and as each user loads data for different countries, a breakdown of the record count by country is really useful.
ODI variables can only store a single value, so the query must be designed to return a single result. A practical approach involves using:
- UPDATE_DT to track updates.
- LISTAGG to concatenate the results into a single row.
- CHR(10) to insert line breaks.
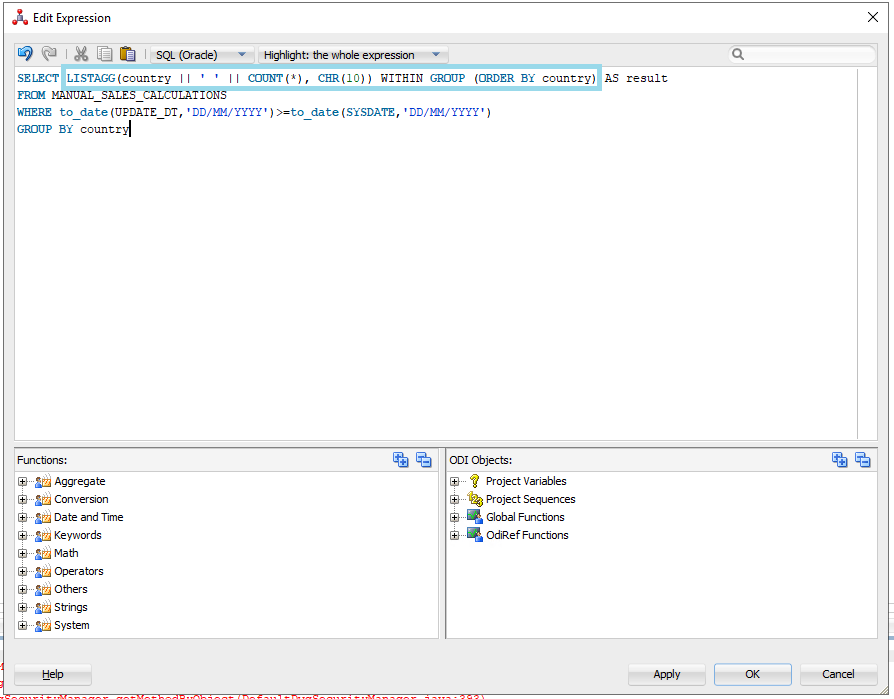
Figure 08: Count number of updated or inserted rows
- Distinguishing environments for email recipients
Users should only receive validation emails in the production environment, whilst developers should receive them in development and testing. One way to achieve this is by creating a variable that identifies the environment and routes emails accordingly.
In an Oracle ecosystem, the SYS_CONTEXT function can retrieve session details like the database name (DB_NAME). By combining SYS_CONTEXT with a CASE WHEN condition, you can differentiate between environments and control the email logic using the OdiSendMail function:
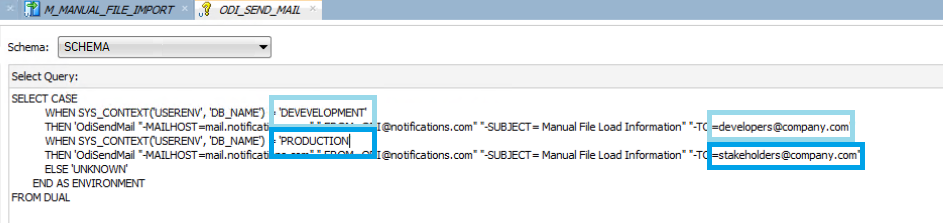
Figure 9: Environment and sender definition
- Composing the email
As a final step, we need to work on the body of the email. For our business case, it should include the two previously created variables, along with a clear and descriptive message to provide context:
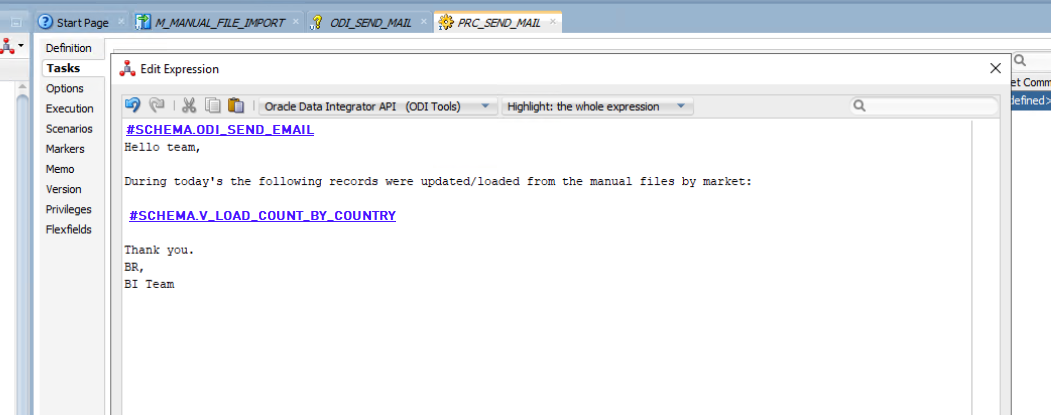
Figure 10: Body email procedure
Here’s an example of the final email generated by our solution:
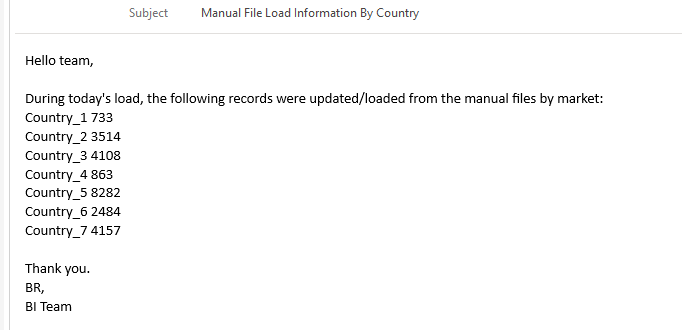
Figure 11: Email result
Conclusions
Integrating manual files into a database presents a range of challenges, from handling file format inconsistencies to managing historical data and enabling user validation. However, with the right strategies and tools, these challenges can be effectively addressed.
This article has outlined a structured approach, using ODI to deliver a clean, efficient, and maintainable solution. Key steps include standardising file formats through templates, designing mappings to track data loads and updates, and implementing user notifications to mitigate data loss or ETL issues.
Looking to streamline your manual data integration processes? Whether you’re tackling ad hoc data loads or scaling organisation-wide automation, our experts can help you build with confidence. Get in touch with us today to discover how we can optimise your Oracle stack!
