18 Mar 2026 Database Connection Pooling: A Guide to Tuning & Performance Optimisation
Every backend developer eventually hits the same wall: testing is quick, then the app slows down, often significantly, under real load. One of the most common causes is overlooked: database connections.
Opening a new connection for every request is expensive. The initial setup, memory allocation, and authentication all add overhead, and that multiplies fast if you’re constantly starting brand-new connections.
Connection pooling solves this by keeping a small set of connections open and ready. Instead of creating a fresh connection, each request borrows one from the pool, uses it, then returns it when it’s done.
That small adjustment has a huge impact: reduced latency, fewer bottlenecks, and smoother scaling. Let’s see what pooling actually does and how to tune it properly.
What is Database Connection Pooling?
Think of a car park with a limited number of spaces. Cars don’t get a new space built for them on arrival. They take an available space, then free it up for the next car when they leave. Connection pooling works the same way: instead of creating a fresh connection for each request, the app takes one from the pool and returns it when it’s finished.
Technically, a pool manages a set of reusable connections so that every request doesn’t have to start from scratch. Once a connection has been established, it can be used repeatedly.
Almost every modern ORM or database driver supports pooling. Tools like SQLAlchemy, JDBC, Prisma, or Node.js’s pg-pool include it, and it’s usually just waiting to be configured properly.
Once enabled, the difference is noticeable immediately: response times drop, and your backend stops struggling under concurrent load.
Source: Digitalocean.com
Why Connection Pooling Matters
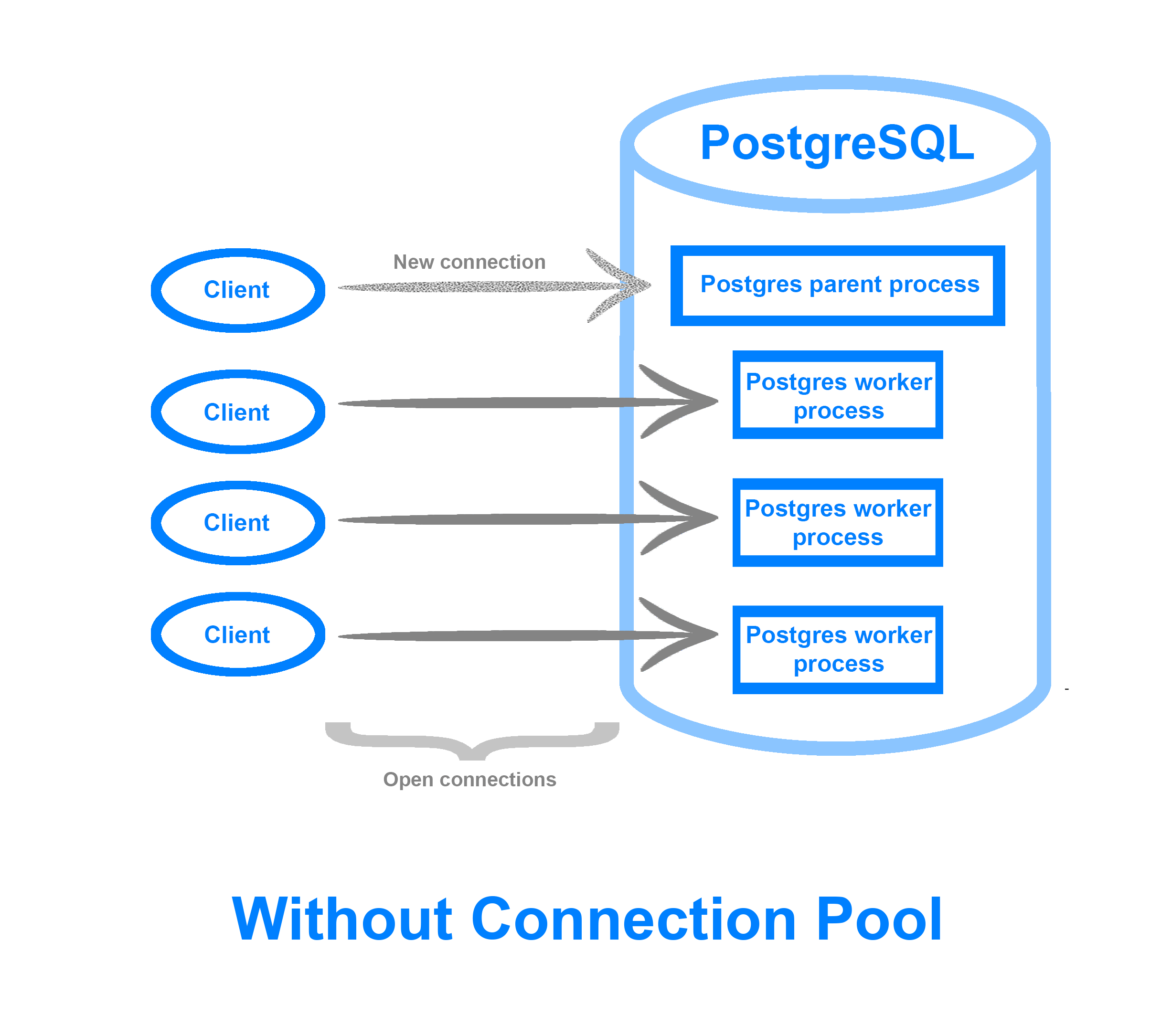
Without pooling, every new request opens a new connection, which is like asking your database to perform hundreds of handshakes every second. Each handshake consumes CPU and memory, so eventually the server runs out of resources or starts rejecting connections.
This is where pooling delivers most of its value. It:
- Reduces latency because connections are ready to use.
- Improves throughput, so more requests are handled in less time.
- Limits resource usage by capping how many open connections exist at once.
- Enhances stability because the database isn’t overloaded with short-lived connections.
- Works well with async frameworks by letting thousands of concurrent tasks share a limited set of live connections efficiently.
Pooling is a scalability mechanism as well as an optimisation; without it, your backend performance ceiling can be extremely low.
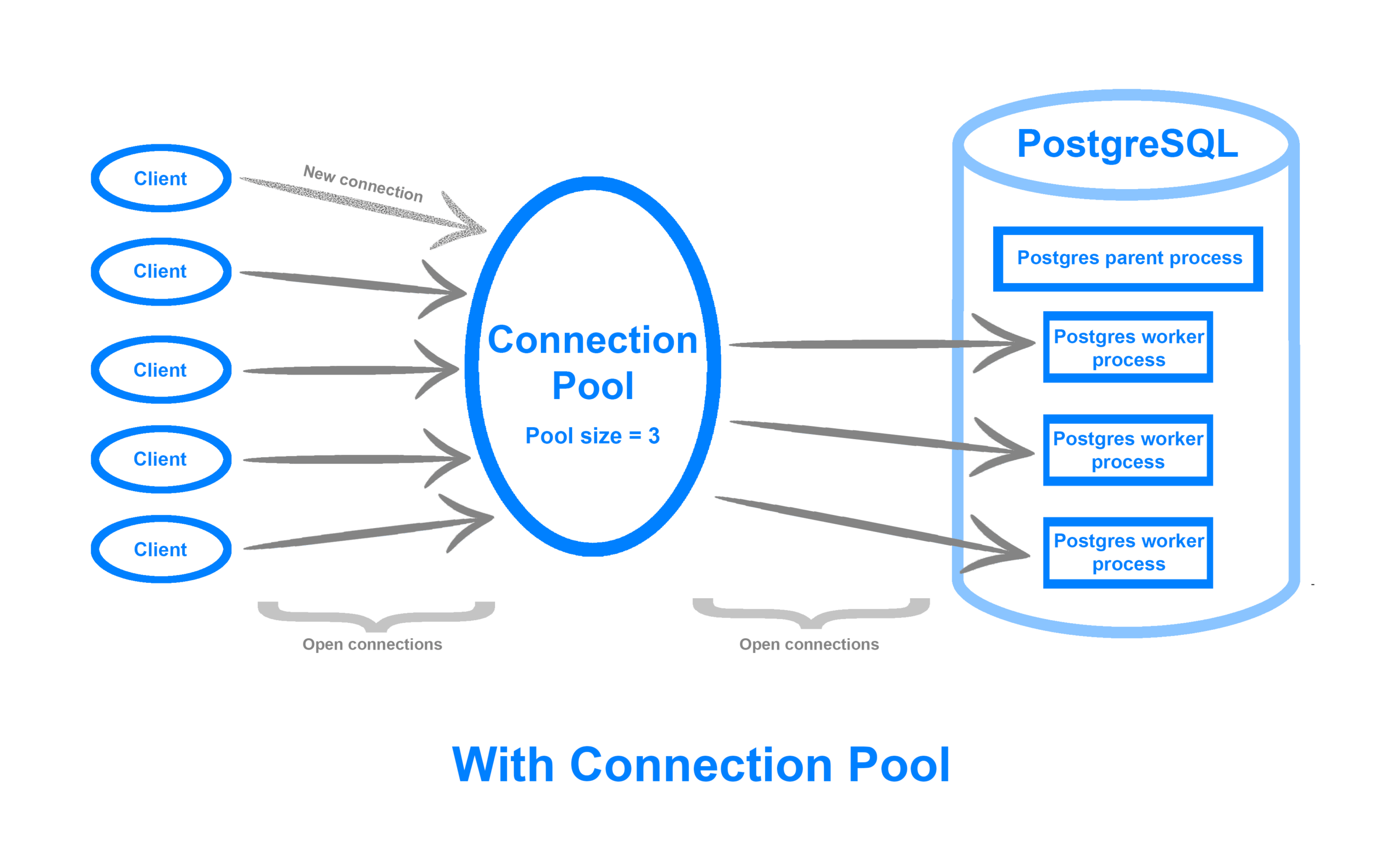
How Connection Pools Actually Work
A connection pool is essentially a leasing system. When a query is submitted, a connection is borrowed from the pool. If all connections are already in use, the request waits until one is available, up to a defined timeout.
Once the query completes, the connection is returned to the pool, reset, and prepared for the next request. Under the hood, pools manage two primary states:
- Active connections: currently in use.
- Idle connections: open and waiting to be reused.
Key configuration parameters determine how this cycle behaves:
- Maximum size: the cap on concurrent connections.
- Minimum size: how many idle connections stay open.
- Timeouts: how long to wait for a connection before failing.
Example: Basic Pool Configuration
Even a small pool is often enough to prevent the database from being overloaded. Here is a minimal example using the Node.js pg library:
const { Pool } = require('pg');
const pool = new Pool({
max: 10 // Maximum number of active connections
idleTimeoutMillis: 30000, // Close idle connections after 30s
connectionTimeoutMillis: 2000 // Wait up to 2s for a free connection
});
It’s simple in principle, but the right balance between these parameters is what separates smooth performance from mysterious slowdowns.
Source: Digitalocean.com
Tuning Connection Pools for Real-World Performance
Connection pooling can be a lifesaver or a source of problems, depending on how it’s tuned. Many teams just flip the switch and think they’re done, but the real performance gains come from careful adjustment.
Here’s where to focus:
- Pool size matters: Start small. A sensible baseline is to set the pool size equal to your CPU core count (or slightly above). Going too high risks saturating the database, whereas going too low means your app will queue requests unnecessarily.
- Timeouts keep things stable: A connectionTimeout (how long to wait for a free connection) prevents requests from waiting indefinitely, whilst an idleTimeout ensures unused connections close instead of lingering and wasting resources.
- Don’t leak connections: Always release connections back to the pool, even on errors. Connection leaks gradually drain the pool until requests start timing out.
- Use prepared statements: Cached prepared statements minimise parsing overhead for repeated queries, making reuse even faster.
- Monitor, test, adjust: There’s no perfect universal configuration. Track metrics such as active connections, queue wait times, and error rates, then load test and iterate.
In short: treat your pool like a living system. Tune it as your traffic patterns evolve.
Async Considerations
In asynchronous frameworks, connection pooling isn’t just helpful, it’s essential.
Frameworks like Node.js or Python’s FastAPI rely on event loops. Without pooling, thousands of concurrent requests could block that loop while waiting for a connection, effectively stalling the entire server.
Pooling avoids this by allowing requests to share a set number of open connections. The loop remains responsive: as soon as one query finishes and a connection is released, the next waiting request can use it.
This is typically handled by async-specific pools (such as asyncpg or aiomysql), which allow the application to wait for a connection without blocking the event loop.
Common Pitfalls to Watch Out For
Pooling helps, but a misconfigured pool can still cause problems. Some of the most frequent mistakes include:
- Oversized pools: More connections aren’t always better. Too many open sessions can exhaust database memory and cause lock contention.
- Undersized pools: Too few connections mean long queues and sluggish response times.
- Long-running queries: One slow query can monopolise a connection and stop other requests from accessing it.
- Unmonitored pools: If you don’t monitor pool health, you won’t detect problems until production starts to slow down.
The answer is straightforward but methodical: monitor, test, and tune setups. Most pool libraries expose metrics directly or can interface with observability tools like Prometheus or New Relic. Use them.
Conclusion
Connection pooling might not sound glamorous, but it’s one of the unsung heroes of backend performance. It ensures that your database, arguably the most critical part of your system, operates efficiently under pressure.
A well-tuned pool can transform a system into one that operates faultlessly even under the most stressful conditions. It increases stability, reduces overhead, and allows you to get more out of your infrastructure without having to pay high scaling fees. Connection pooling is not just a technology decision; it is also an architectural one.
If you want help to tune connection pooling in the context of a real production stack, ClearPeaks can help. Get in touch with us today!
