10 Jun 2026 Beyond SEO: How to Architect Your Website for the Age of AI
The way users search for content online has changed dramatically, and human visitors are no longer the only audience for modern websites. In the past, search engines were used to fetch a list of potentially useful links, but now the number of chatbots and AI-powered search tools that can parse content and deliver responses directly in plain text is growing every day.
This reflects a broader shift in online search: instead of browsing traditional search results, users are increasingly receiving answers from AI agents, which means they may not visit or interact with the original data source at all. Nevertheless, there are some measures we can take when publishing our content to ensure the best possible visibility and performance with search and answer engines.
Managing Crawler Access with robots.txt
Before AI and search-engine crawlers visit your site, they should check for access restrictions defined using certain standards, primarily the public robots.txt file, which implements the Robots Exclusion Protocol, standardised in RFC 9309. It must be available at the root level of your domain and uses plain-text rules for user agents and URL paths to indicate which parts of the site crawlers may or may not access. If no restrictions are defined, crawlers are permitted to access all publicly available content.
Nowadays, there are two types of AI-related bots/crawlers:
- Scrapers: Bots that scrape content to train models to gain knowledge.
- Searchers: Bots that browse live to retrieve answers for users working with chatbots.
Many AI companies use different crawlers for different purposes, allowing site owners to control crawler access more precisely. For example, in our robots.txt file we could explicitly disallow OpenAI’s “GPTBot” (user-agent string reserved by OpenAI) from accessing our whole site for model-training purposes, whilst still allowing access to “OAI-SearchBot” (another crawler’s user-agent that acts on behalf of users) for live browsing and retrieving responses:
User-agent: GPTBot Disallow: / User-agent: OAI-SearchBot Allow: /
Figure 1: Sample robots.txt declaration
There are legitimate reasons for disallowing crawlers from accessing certain parts of your site, such as protecting intellectual property (IP) or reducing the risk of specific content being retrieved or reused by AI systems. However, only well-behaved bots, mainly those operated by recognised companies, are likely to honour the rules defined in robots.txt, whilst malicious bots may ignore them, so it is important not to depend solely on this mechanism to protect your content from automated access.
The Skeleton: Semantic and Accessible HTML
Since content-driven AI models mainly read and process HTML markup, they do not interpret visual layouts in the same way as humans do. This means that the HTML source should be well structured and follow good practice in order to provide crawlers with as much context as possible. This is closely related to improving accessibility for screen readers and other assistive technologies, as we have already seen in previous blog posts.
The use of semantic HTML elements is one of the main ways to provide context for content and enrich its meaning. Some examples include:
Semantic HTML structures | ||
|---|---|---|
Preferred elements | Suitable uses | |
| Lists | <ul>, <li> | Enumerating sets of elements |
| Landmark elements | <header>, <nav>, <aside>, <footer> | Indicating main structural elements of the page |
| Content-rich sections | <article>, <details>, <section> | Wrapping related content into sensible parts |
| Miscellaneous elements | <summary>, <time>, <figure> | Detailing specific bits of content with specific purposes |
Figure 2: Table of preferred semantic HTML elements and their suitable uses
You can read more about semantic HTML standards in the MDN Web Docs Semantic HTML module.
The Universal Translator: Structured Data (schema.org)
One of the most important aspects of making your site understandable to AI crawlers and conventional search-engine crawlers is to provide relevant structured data. This data can be provided in different ways, although the most common method is to embed a block of JSON-LD (JSON for Linked Data) inside a <script> tag in the page’s HTML source:
<script type="application/ld+json">
{
"@context": "https://json-ld.org/contexts/person.jsonld",
"@id": "http://dbpedia.org/resource/John_Lennon",
"name": "John Lennon",
"born": "1940-10-09",
"spouse": [
"http://dbpedia.org/resource/Yoko_Ono",
"http://dbpedia.org/resource/Cynthia_Lennon"
]
}
</script>
Figure 3: Sample JSON-LD definition. Source: json-ld.org
Since this <script> tag doesn’t affect the page’s visual layout, JSON-LD is generally considered the easiest structured data format to implement and maintain. By contrast, alternatives such as Microdata and RDFa rely on inline attributes to HTML elements which can break during layout changes.
Schema.org is an open community specification founded by Google, Microsoft, Yahoo, and Yandex (the world’s major operators of search engines) that provides a shared vocabulary for structured data on the web. Individual schema types are organised in a hierarchy from which they inherit properties. At the top of the main hierarchy is Thing, which includes generic properties such as description, image, and name.
Let’s look at some of the most commonly used schema types:
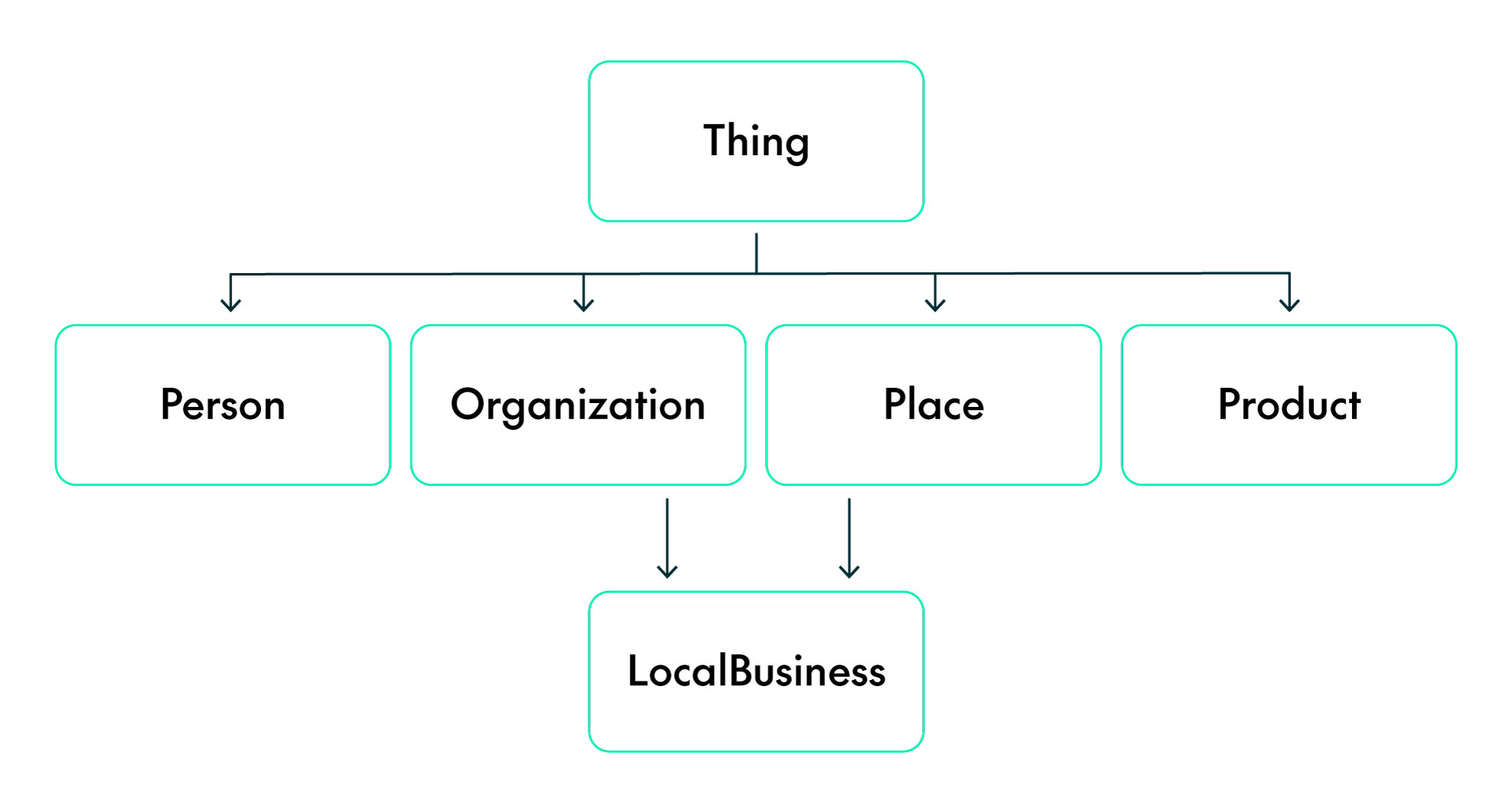
Figure 4: Hierarchical representation of some of the most common schema.org schemas
| Schema | Property source | |
|---|---|---|
| Person | Inherited from | Thing |
| Specific to | birthDate, children, deathDate, email, familyName, gender | |
| Organization | Inherited from | Thing |
| Specific to | address, alumni, founder, foundingDate, parentOrganization | |
| LocalBusiness | Inherited from | Organization, Place |
| Specific to | currenciesAccepted, openingHours, paymentAccepted, priceRange | |
| Product | Inherited from | Thing |
| Specific to | model, productionDate, releaseDate, review, size, slogan |
Figure 5: Table showing some of the most common schema.org schema properties
Strategically, having site pages marked up with complete structured data helps search engines to provide richer details when returning your site as a result, whilst also making it easier for AI systems to extract relevant and detailed key information.
Performance and Mechanics
Just as a site’s performance can affect its rankings in search engines, AI crawlers have limited time and resources, often referred to as crawl budget, to parse and analyse each page. As a result, performance issues may affect how completely they can process a page. These issues are often linked to traditional performance bottlenecks, such as excessive client-side rendering, slow-loading resources, and render-blocking requests.
If a crawler encounters these bottlenecks, it could time out or abandon the page before the core content has fully loaded, meaning that some content may not be properly extracted, indexed, or made available for AI-generated answers.
Text Density
Since LLM-based systems operate with token limits, text density becomes important once content is extracted, chunked, retrieved, or used to generate answers. Filling a page with unnecessary conversational padding can dilute its information density, making it harder for AI systems to identify clear answers. To avoid this, many writers use techniques that improve text density and make key information more explicit and accessible:
- BLUF (Bottom Line Up Front): Start with the main conclusion or key message. This helps crawlers and AI systems to capture the core point quickly.
- Question headings: Use headings based on the questions users are likely to ask. This aligns the content with search intent and makes it easier for AI systems to identify relevant answers.
- Reduce vague references: Limit pronouns and demonstratives such as “it”, “this”, or “they” where possible. This reduces ambiguity and makes the text easier to understand when read out of context.
- Atomic content units: Write content blocks that can stand alone and be understood without relying heavily on previous paragraphs. This is especially useful for Retrieval-Augmented Generation (RAG) systems, where content is often stored and retrieved in separate chunks.
Conclusion
The latest developments in technology and AI are redefining the way users interact with and consume online content. New AI systems increasingly analyse web content and search for answers on behalf of users, making it essential for organisations to consider how their websites are understood by these tools.
Enriching your site with structured data, clear content, and good performance practices not only benefits users but also strengthens your presence in this evolving search landscape. If your organisation wants to adapt to this new environment, ClearPeaks can support the modernisation process. Get in touch with us to plan your next steps!
