23 Jun 2026 Building the Data Foundation for Enterprise AI
AI is moving faster than we ever imagined. Organisations are exploring what it can do in forecasting, optimisation, virtual assistants, on-demand BI, agentic workflows, and internal knowledge. The ambition is real, market investment is rising, and the use cases are valuable.
Source: Gartner Forecasts Worldwide AI Spending to Grow 47% in 2026
But AI needs a strong data foundation. Organisations come to us with a clear objective: they want AI. However, when we begin our initial diagnosis, the conversation changes. Before discussing models, agents, or prompts, we need to ask whether the data foundation is actually in place, and very often the answer is no.
That doesn’t mean that their plans are unworkable; it means that the first step is not what they expected. In many cases, we need to go back to square one and help the business to set up the data platform, pipelines, governance, infrastructure, and operating model before AI can deliver at scale. Fortunately, the client doesn’t have to wait until their wider data environment is up and running before they start seeing some value from AI. There are quick wins that can be delivered whilst the wider foundation is being built: focused pilots, productivity tools, internal knowledge assistants, workflow automations, or analytics enhancements. The key is to be clear about the difference between a useful short-term AI win and a scalable enterprise AI capability. The first can often be delivered quickly; the second needs a stronger build if it is going to be reliable, auditable, and reusable.
There are various factors at play: Gartner states that, by the end of 2025, at least 50% of generative AI projects had been abandoned after the proof-of-concept phase due to poor data quality, inadequate risk controls, escalating costs, or unclear business value. Their 2026 research also shows that organisations with successful AI initiatives invest up to four times more, as a percentage of revenue, in foundational areas such as data quality, governance, AI-ready people, and change management. This matches what we’re seeing in the market: AI success depends on much more than choosing a model. It depends on whether the organisation’s infrastructure is ready to support AI systems with reliable, governed, accessible, and meaningful data.
Why a Strong Data Foundation Matters
Over the last 25 years, BI, analytics, data warehousing, cloud platforms, and modern data engineering have changed the way businesses operate, helping to standardise processes, reduce manual work, and scale operations.
Yet many organisations still have work to do. Some need a proper data platform, some lack the software solutions they need, whilst others depend on manual processes, disconnected systems, or Excel spreadsheets. And now AI is increasing the pressure, because the cost of inaction is greater. In the past, a weak data foundation limited reporting, analytics, and operational visibility, but today it also limits the organisation’s ability to capture the advantages that AI can offer. Without the foundation, the company doesn’t simply miss out on the benefits of having a data platform, but the additional value that AI could generate as well: better forecasts, faster decisions, automated insights, intelligent processes, and new services; such as document summarisation tools, knowledge assistants for employees, etc.
This is why an AI project can surface problems that were already there. An organisation may start with a clear AI vision, but once we look at the data, we find that it’s incomplete, inconsistent, poorly governed, or not available through reliable pipelines. The result is now familiar: the AI discovery session becomes, in part, a data project.
This isn’t failure; in fact, it’s often the most useful discovery the initial AI assessment can produce. It shows what needs to be fixed before AI becomes a full production capability. The point is simple: you cannot capitalise on enterprise AI if your data is not ready, your digital processes are not mature, and your governance model is not strong enough to support the outputs.
Getting Started: Readiness Assessments
The first step in any serious AI initiative should be a readiness assessment to avoid building an AI solution that will break under real operating conditions.
At ClearPeaks, the first question we ask is about the business problem. What is the organisation trying to improve? What decisions, processes, or user experiences should AI support? Is the expected value clear? Is AI really the right solution, or would a more traditional analytics, automation, or software approach be better? AI shouldn’t be used because it’s fashionable, but because there’s a clear link between this approach and the objective.
Once the use case is defined, the next question is readiness. In our experience, more than half of our initial AI conversations reveal that substantial work first needs to be done on the data layer: basics such as setting up parts of the platform, building pipelines, connecting source systems, improving data quality, or defining governance processes. In many cases the AI project can go ahead in parallel with the data foundation work; sometimes the scope has to be adjusted.
Our evaluation covers these areas:
- The business problem and expected value.
- The suitability of AI for the use case.
- The availability and quality of the required data.
- The maturity of the data platform and pipelines.
- The level of governance, security, and compliance required.
- The operating model for maintaining the solution.
- The ability of users to understand, validate, and act on AI outputs.
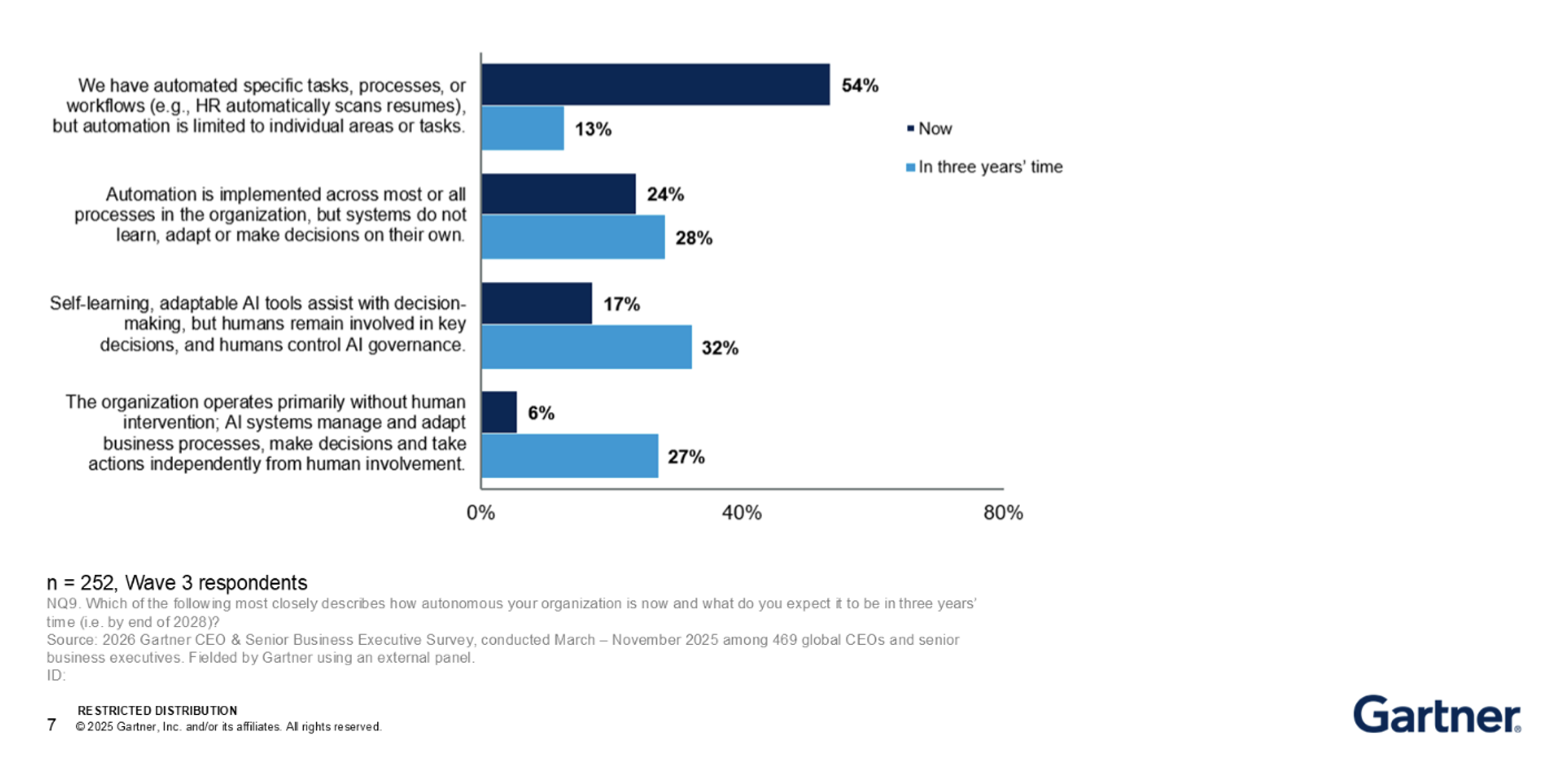
Gartner’s 2026 research supports the same conclusion: AI readiness is not simply a question of having clean data in the traditional reporting sense. AI success requires high-quality, trusted, and context-rich data that is accessible to both humans and AI agents, as well as technologies, platforms, and architectures capable of supporting specific AI-ready data requirements. They also identify context, including semantics and metadata, as mission-critical infrastructure for data and analytics, and stress that AI agents need governed, contextual access to the right data. In other words, readiness depends on the use case, and this is why the assessment has to be practical.
Setting Up the Foundation for Successful Enterprise AI
Once the gaps are clear, the next challenge is to build the foundation without turning the whole thing into a lengthy programme before any value is delivered. In practice, this means connecting AI ambition with data platform execution. For example, imagine that an organisation wants to build a forecasting solution. The readiness assessment shows that the historical data exists, but is spread across several systems, with inconsistent definitions and no reliable pipeline. In a case like this, the AI project should include the creation of a trusted data flow, agreed business definitions, quality rules, and monitoring. The first AI use case then becomes a driver for improving the wider data foundation.
Another organisation may want a natural language assistant for BI. That sounds like a straightforward AI project, but it also requires a semantic layer, governed metrics, access controls, clear data lineage, and the ability to audit generated queries. Without those elements, the assistant may be impressive in a demo but risky in production.
A solid enterprise AI foundation normally includes:
A modern data platform
AI needs data that can be accessed, processed, and served. Depending on the organisation, this may involve a cloud data platform, lakehouse architecture, a data warehouse, a streaming layer, or a hybrid system. The exact technology stack will vary, but the principle remains the same: the platform must support analytics, AI development, and production deployment.
Reliable data pipelines
Enterprise AI cannot depend on manual extracts and local files: pipelines need to move data from source systems into analytical environments in a repeatable, monitorable, and maintainable way.
Data quality and governance
The organisation needs to know whether the data is complete, consistent, timely, accurate, and fit for its intended use. Data quality rules, ownership, stewardship, metadata, lineage, and documentation all become part of the AI foundation.
Digital process maturity
Sometimes the problem is not only the data platform; the processes that generate the data may also be weak. If a key business process is still managed through manual workarounds, unmanaged spreadsheets, or disconnected tools, the AI solution will inherit those weaknesses. Digital maturity matters because AI depends on the quality of the processes behind the data.
An operating model
Enterprise AI is not just a technical deployment. It requires collaboration between business teams, data engineers, data scientists, analysts, software engineers, governance teams, security teams, and end users. Someone has to own the data, someone has to maintain the pipelines, someone has to monitor the solution, and someone has to decide when an AI-generated answer is good enough and when it needs human review.
This is why AI projects often become broader change management programmes.
Source: Gartner
Guardrails and Hallucinations
The old expression “garbage in, garbage out” still applies. But AI adds a dangerous twist: it can produce garbage that sounds convincing. A traditional report with bad data may look incomplete or unusual, whilst a generative AI answer can be fluent, confident, and totally wrong.
This is why enterprise AI needs guardrails, mechanisms that help ensure AI systems operate within defined business, security, and compliance boundaries. Even though there’ll always be some risks – hallucinations can still happen. Models have improved, especially with more advanced reasoning capabilities, but AI outputs need to be auditable, testable, and accountable.
For research-based use cases, auditability means more than showing a general list of sources. The AI should link conclusions to specific documents, passages, or quotes, and if the AI assistant claims that a report supports a conclusion, users should be able to inspect the original evidence. “Almost the same” is not good enough when the output is used for key reports.
For BI use cases, auditability means understanding where the answer came from. If an AI assistant generates an SQL query or retrieves data from a semantic layer, the organisation should be able to inspect the query, check the data source, and validate the logic. Once again, this is especially important for high-impact decisions.
We also need to test before deployment. Teams can define common questions, expected outputs, acceptable tolerances, and regression tests. If an agent generates queries, those queries should be assessed; if an assistant produces explanations, those explanations should be reviewed against known answers and source material.
Here we can employ model-based reviews: one model can be used to assess the output of another, preferably using a different provider or model family, helping to identify inconsistencies, weak reasoning, or unsupported claims. Of course, this should complement human validation, never replace it.
The final safeguard is training and responsibility. Users must know how to interpret and work with AI-generated answers. In some cases, an indication of what to expect is enough: whether a number should be around 50% or 75%, whether a trend is rising or falling, or whether the output seems reasonable from a business perspective. However, when the result can influence an important decision, precision is crucial, and the answer must be checked by someone with the appropriate technical knowledge or business understanding.
The point is not to make users afraid of AI, but to train them to use it properly. AI can support faster decisions, but it should not remove judgement, validation, or responsibility.
Conclusion
The companies and organisations that succeed with AI will not necessarily be the ones that run the most pilots or choose the most fashionable tools; they will be the ones that connect AI ambition with data reality. As we’ve seen in this article, a strong AI strategy starts with the data foundation, digital infrastructure, governance model, business alignment, and operating discipline.
The practical approach we recommend is not to stop all AI activity until the data foundation is perfect, but to identify quick wins, assess readiness honestly, prioritise the right use cases, build what’s missing incrementally, and deploy AI with the right guardrails from day one.
AI is a powerful value multiplier, but only if the organisation is ready to benefit from it. Short-term AI wins can build momentum, prove value, and help teams to learn. A stronger base is what allows those wins to become scalable enterprise capabilities rather than isolated experiments.
Here at ClearPeaks, we help organisations move from AI ambition to AI execution. Whether your immediate need is a readiness assessment, a modern data platform, or production-ready solutions, the objective is the same: an AI deployment that is useful, auditable, and scalable. Get in touch with our dedicated team to see how we can build the right foundation for your enterprise AI.
