01 Feb 2024 How to Choose Your Data Platform – Part 1
In the ever-evolving landscape of data management, choosing the right data platform technology stack is a crucial step for businesses aiming to fully harness the power of their data. Most organisations now consider the cloud to be the best place for their data platforms, thanks to the flexibility and scalability offered. With numerous options on the market, including like AWS, Azure, GCP and Oracle Cloud, as well as more specialised products like Cloudera, Snowflake and Databricks, the decision-making process can be daunting, and in this mini-series we’ll throw some light on how to best make that decision.
Here at ClearPeaks we are experts on all these technologies, so don’t hesitate to contact us for further guidance if you are deciding which is the best way to go for your organisation. We also recommend you check our webinar series «Journey to the Cloud», where we run through all the above-mentioned technologies, talk about real-life projects that are using them, and present best practices and recommendations.
Data Platform Architecture Evolution
Let’s start at the beginning. Where do data platforms come from? How have they evolved and how will they continue to evolve? Let’s take a look at the diagram below, loosely inspired by this image Databricks used in this blog of theirs.
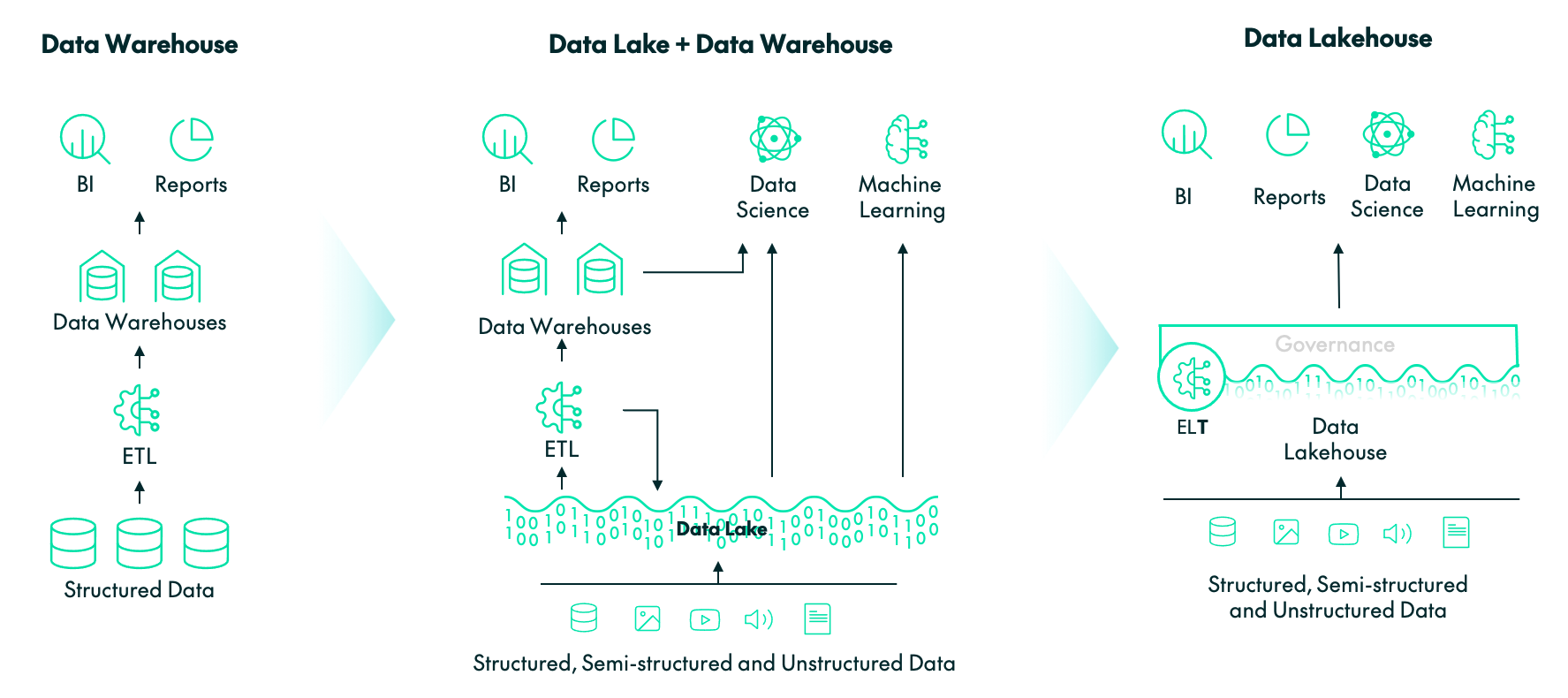
We can see three data platform architectures: the data warehouse, the data lake plus data warehouse, and the data lakehouse. We are not going to go into the details of each of them because there is already plenty of material out there covering them, like the Databricks blog we just referenced. Please note that although the above diagram might lead you to think that data warehouses are no longer in fashion, in reality they are still used a lot, and in some scenarios we would still recommend them.
The diagram represents the evolution of data platforms over the last few decades; however, these platforms have not stopped evolving and they will continue to do so. In the last couple of years, data platform vendors have started using new terms to talk about their proposed platform architecture, now offering even more features than the data lakehouse.
In this blog post and the next, we’re going to focus on the architecture and the technical aspects and features of these platforms, not on the data ownership and governance model (centralised vs de-centralised, i.e. whether to go for a Data Mesh or not; check out our previous blog post for more information on this).
Data Fabric
One of the terms vendors have started using recently is “data fabric” (or variations on it). However, as often happens with new terms, each vendor has a slightly different understanding of what a data fabric is. In a previous blog post, we discussed the data fabric architecture, and now we’ll summarise that below:
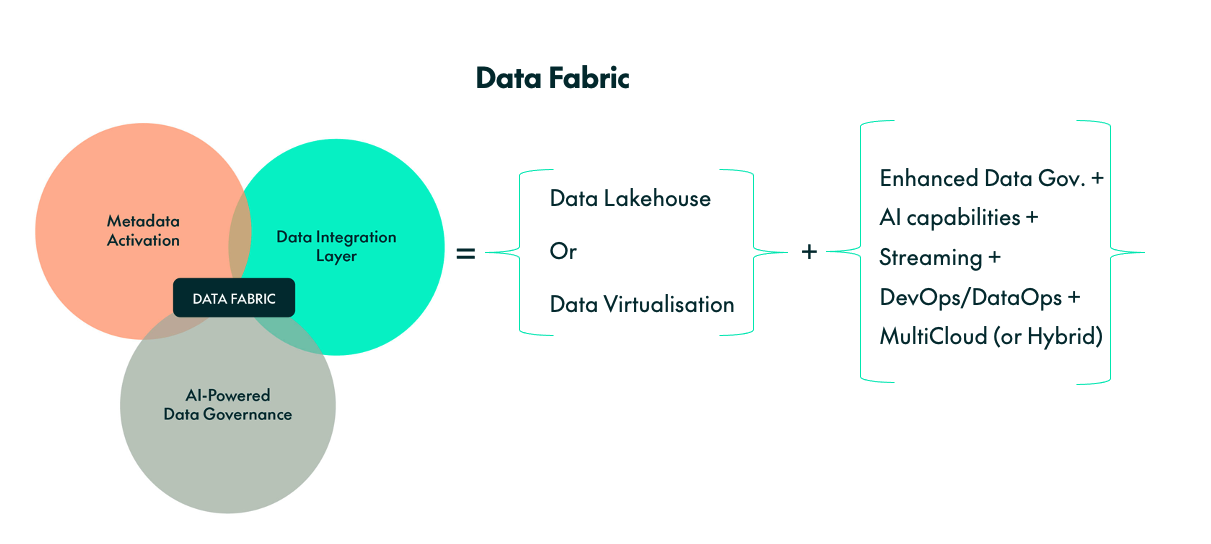
A data fabric is essentially a data lakehouse or visualisation layer, augmented with AI, streaming, and advanced data governance capabilities. These enhancements surpass traditional data cataloguing by incorporating AI and metadata activation. Ideally, it includes DevOps/DataOps, data lineage, data quality mechanisms, and supports multi-cloud or hybrid (on-prem and cloud) deployments.
Enterprise Data Platform
In addition to a data fabric, there is another term that is also seen a lot when describing modern data platforms – Enterprise Data Platform (or slight variations on it). As with data fabric, different vendors use the term to describe slightly different things. At ClearPeaks we have been using this term and also «Big Data Platform» for a while now, and the proposed architecture is shown below:

As you can see, there’s quite an overlap between a data fabric and the Enterprise Data Platform. A data fabric puts more focus on Governance and AI enhancements, whilst an Enterprise Data Platform also includes the presentation layer, from standard reporting and dashboarding to executive and custom experiences (check out our Observation Deck).
Choosing Your Data Platform Technology
Whether you’re implementing a data fabric or an enterprise data platform, with either centralised or decentralised ownership and governance, let’s call it a ‘data platform’ for the sake of simplicity. Choosing the right technology stack can be challenging, so we’ve conducted a base assessment that first identifies the key aspects that a data platform should offer, and then evaluates how different technology stacks perform across these aspects.
In this first instalment of our mini-series, we’ll unveil the first part of our base assessment, focusing on the essential aspects a data platform must encompass. In the second part, we’ll present some tech vendors suitable for an implementation. However, we won’t be sharing the second part of the assessment, examining how each tech vendor aligns with these aspects: this is to prevent any potential misguidance, as the optimal choice for an organisation is heavily influenced by its unique requirements. That being said, we’d be happy to help you! Leveraging our base assessment, we offer a customised assessment for your organisation, tailored to your specific needs, guiding you towards the right decision. Contact us for more information!
Aspects of a Data Platform
Below you can find the twenty aspects that a data platform must be able to cover and that we used in our base assessment:
- Data Ingestion: How the platform can bring in data from various sources, including both real-time ingestion and batch ingestion.
- Batch Data Engineering: The ability to process large volumes of data in batches in a scalable and simple way like SQL, Python, or even graphical user interfaces.
- Streaming: Real-time data processing capabilities including caching mechanisms for events (queue systems) and complex event processing via easy-to-use interfaces (SQL or even graphical).
- Data Store Unification: The ability to unify how and where data layers are stored. Does the platform need to use different internal technologies to store the data depending on its layer (raw vs curated; bronze vs silver vs gold; etc.), or is all the data stored and handled in the same way?
- Orchestration: Managing and coordinating data workflows seamlessly.
- Semantic Modelling: Creating meaningful relationships between different data entities so that end consumers can interact with the data in a simple and understandable way.
- BI Query Performance Optimisation: How the platform optimises query performance without or with minimal data engineering. Are mechanisms such as database table indexing, partitioning, or bucketing automatically taken care of by the underlying engine?
- Data Visualisation: The tools and capabilities to present data in a visually compelling manner, including reports and interactive dashboards.
- AI Capabilities: The integration of artificial intelligence and machine learning services, including the ability to create ML models and deploy them (via APIs), or to interact with existing models like Large Language Models.
- DevOps: Support for collaborative and automated software development processes applied to both data engineering and warehousing (DataOps) and data science (MLOps).
- Ease of Use: User-friendly interfaces and intuitive workflows.
- Ease of Administration: Simplifying the management and maintenance of the platform.
- Access Controls: Robust security measures for access not only to data itself but also to the various entities in a data platform (data pipelines, compute engines, etc.). This is especially relevant with decentralised ownership.
- Data Governance – Catalogue: The ability to create and manage a comprehensive data catalogue, as well as other entities like data pipelines.
- Data Governance – Lineage: Automatically tracking and documenting the origins and transformations of data within the platform; enabling smart navigation through this metadata.
- Data Governance – Data Quality: Automatically ensuring data accuracy and reliability via the creation and automated execution of rules or checks via easy-to-use interfaces.
- Multi-Cloud and Hybrid: Support for multi-cloud and hybrid cloud and on-prem architectures.
- Openness: The extent to which the platform supports and promotes open-source technologies and interoperability.
- Robustness: The maturity level of the underlying technology and its components.
- Price: Cost-effectiveness and transparent pricing.
Coming Next
In this blog post, we’ve explored the evolution of data platform architectures at a high level, tracing the journey from data warehouses to the current trends of data fabrics and enterprise data platforms. We’ve also introduced our base assessment, designed to assist organisations in selecting the most suitable technology for their particular needs, and shared our list of the twenty essential aspects that a data platform must cover. In our next blog post, we will showcase various tech vendors and their solutions for building cloud data platforms, focusing on how they address these twenty aspects. Stay tuned for more insights, and drop us a line if there’s anything we can help you with!
