03 Jun 2026 An Agentic Ingestion Framework in Databricks
Organisations now have access to an ever-growing number of data sources, and being able to ingest multiple data sources rapidly is critical to maximising the value they extract from their data. Because ad hoc ingestion requires a great deal of effort and is slow, many organisations have started to implement ingestion frameworks to streamline their ingestion processes.
Whilst these frameworks are effective at simplifying and speeding up ingestion, the process still depends on the data engineering and platform teams that control these frameworks to manage the individual ingestion steps and triggers. As a result, reliance on these teams can eventually become a bottleneck as new data sources appear at an ever-increasing rate.
Automation is a logical solution to these problems. Business teams can carry out the whole ingestion process without relying heavily on data engineering and platform teams, whilst still applying best practices that improve ingestion efficiency and reliability. An AI agent built on an existing data ingestion framework can help to provide these capabilities and serve as a knowledge base where business users can ask questions about metadata related to the tables being ingested without having to rely on other teams. In this blog post, we’ll show you how we implemented an agentic ingestion solution on top of an existing data ingestion framework in Databricks and we’ll also explore the current Databricks capabilities available for developing this type of solution.
Ingestion Framework
For this blog post, we worked on an existing ingestion framework that had not previously incorporated AI before we added our agentic ingestion solution. We used Databricks Declarative Automation Bundles (formerly known as Databricks Asset Bundles) to deploy the initial ingestion framework across the development and production environments. For each environment, we had a pipeline that ingested data from the source into the destination in Databricks.
The framework included two tables: a log table that stored the execution logs of pipeline runs, and a metadata-driven control table that stored the configurations to be run when triggering pipeline runs. These configurations included the destination catalog and schema to load the table into, the load type, which could be full or incremental, a watermark column for incremental loads, and a column indicating whether the configuration was active or inactive, allowing the pipeline to determine which control-table rows to execute in each run.
The following diagram is a visual representation of the framework:
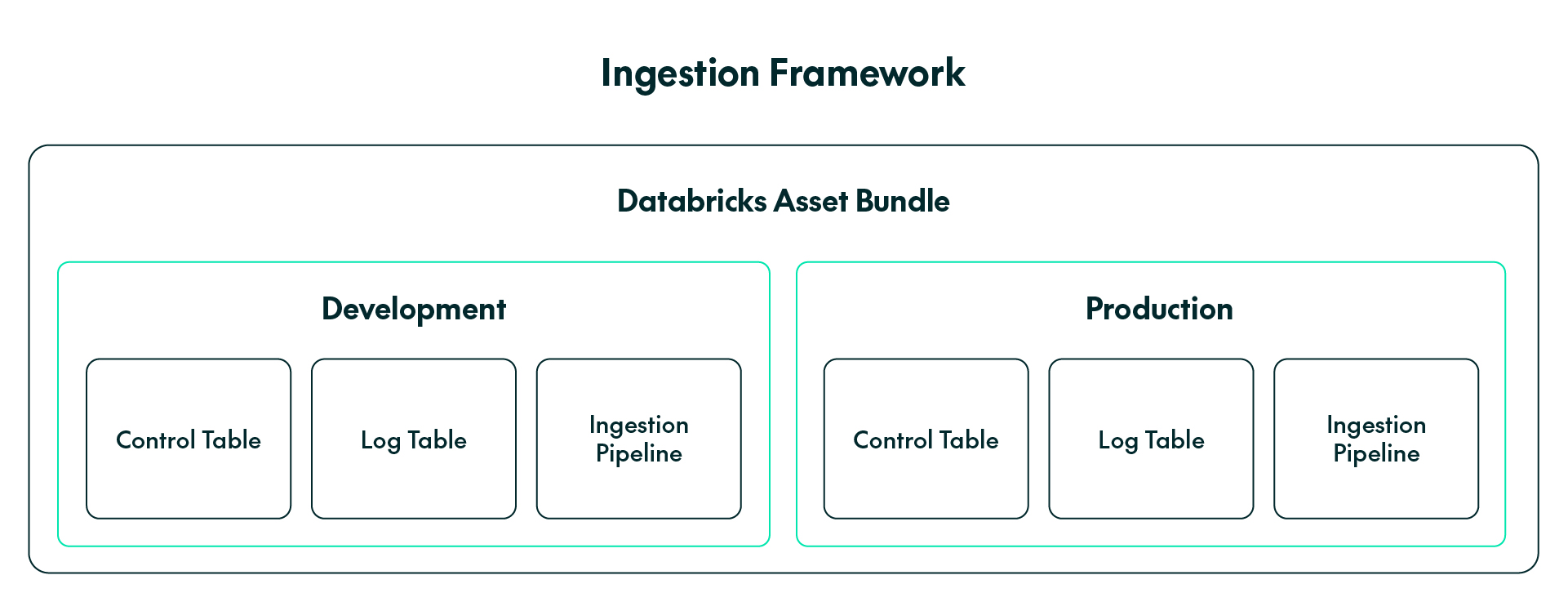
Figure 1: The ingestion framework
AI Integration into the Framework
As we explained in the introduction, our goal with this AI agent integration was to explore to what extent we could improve the ingestion process, eliminate the bottlenecks threatening the effectiveness of existing ingestion frameworks, and examine the native Databricks capabilities available to do so.
We wanted our agent to answer questions about several areas of the framework and interact with it without reasoning about the actual data in the tables being processed. Some of the questions we wanted the agent to answer were:
- Discovery: What tables are currently configured for ingestion in incremental mode?
- Ingestion status: What was the status of the most recent pipeline run?
- Incremental loads: What was the last processed watermark for a given table?
- Failure troubleshooting: Why did the most recent run of the ingestion pipeline fail?
- Performance: Which tables take the longest to ingest on average?
- Control-log relationship: What was the last run status for each active configuration?
Apart from answering questions, we also wanted the agent to interact with the framework by performing the following actions:
- Activating and deactivating rows in the control table by changing the value of the is_active
- Adding new rows to the control table by providing the agent with the required metadata fields.
- Triggering an ingestion pipeline run for the active rows in the control table.
The following figure shows these actions and how they interact with the framework:
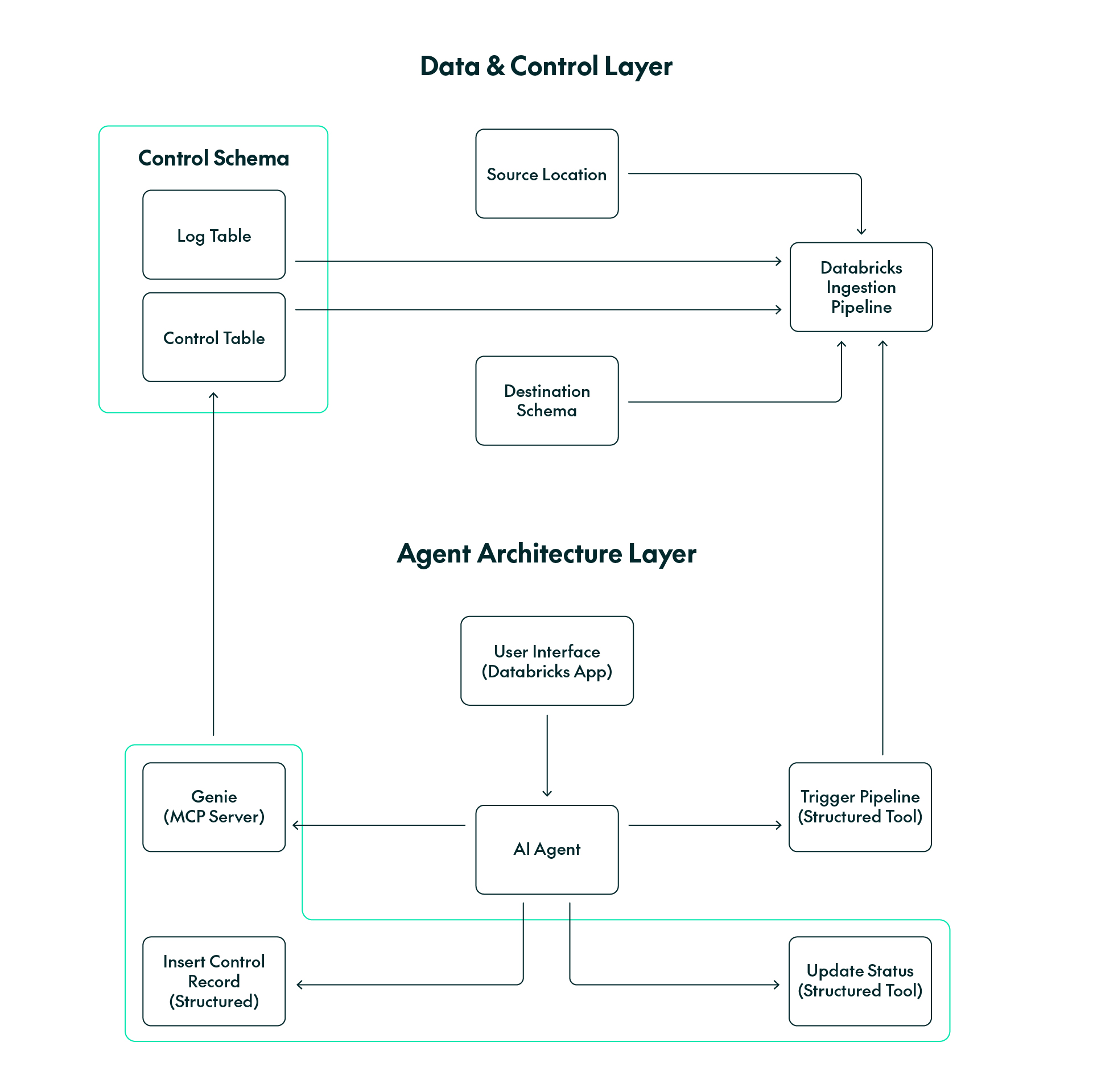
Figure 2: How the AI agent interacts with the ingestion framework
To start, we used a template provided in the Databricks documentation for the main agent code, which uses managed MCP servers. We provided a system prompt to the agent explaining each of the capabilities mentioned above, which questions to answer, and which questions were out of scope. For each capability, the agent was instructed to ask the user for explicit permission before executing anything.
Implementing the question-answering capability was straightforward, as the Genie Space makes it easy to interact with data contained in tables. We gave the Genie Space the necessary context to interact with the control and log tables, ran benchmarks to determine the accuracy of the answers, and declared it as an MCP server in the agent code.
For the remaining actions, we tried to create them as Unity Catalog functions and declare them as MCP servers in the agent code. However, we ran into problems because each action needed to interact with the control table, either through the SDK or an API. This required access to either the Spark session or to authentication tokens, which was not feasible with MCP servers because they do not have access to the session used by the agent.
Because of this, we decided to use LangChain tools based on StructuredTool, which act as wrappers for Python functions and run in the same Python process as the agent. This provided direct access to the required functionality without the need to manage credentials separately.
Having developed the core agent logic, we focused on making the agent available to the end users who would interact with it. To do this, we exposed the agent through a serving endpoint and then created an interface with Databricks Apps, where the agent is displayed as a chatbot.
This enabled users to interact with the data ingestion framework directly, without having to rely on data engineering and platform teams. At the same time, it ensured that any changes made by users followed the best practices defined for the agent, and that the agent would not act without explicit human approval.
Promotion to Production
Having integrated the AI agent into the existing ingestion framework in the development environment, the final step was to decide how to promote the agent-generated changes from the development control table to the production control table.
After developing the agent and its capabilities in development, it became clear that its role was strictly to help users to make changes. For this reason, it made no sense to deploy the agent in production, where it would not be used to apply changes directly and where the non-deterministic nature of AI agents could lead to inconsistent outcomes across environments. Neither of these risks would be acceptable in a production environment.
To mitigate these risks, we designed a Git-based custom process for promoting changes to production. This allowed us to push changes made in development in a deterministic way and to add the necessary validations.
We also added a new capability to the agent. Users can request the promotion of a set of tables to production, and the agent will create a JSON payload containing the changes to be pushed, as shown in the example below:
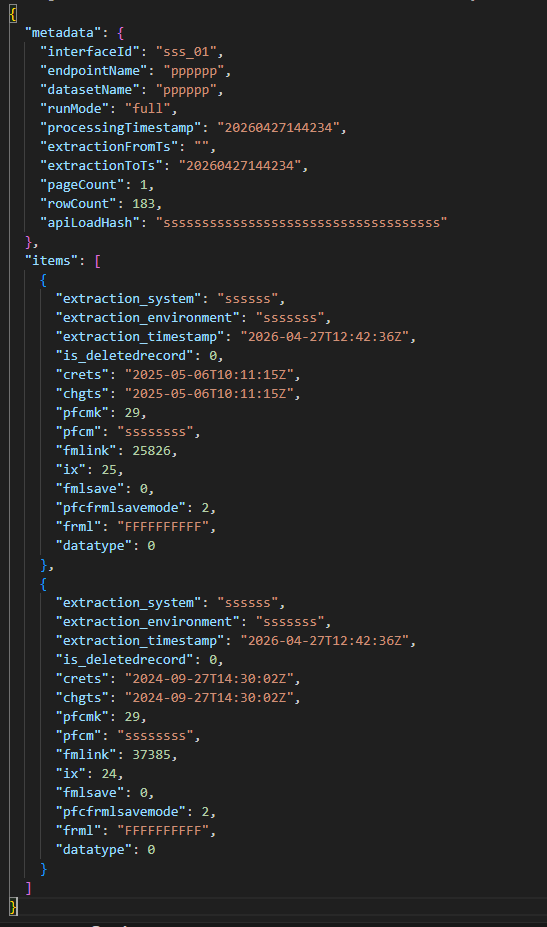
Figure 3: Example JSON payload when deploying to production
The agent then creates a pull request to the production branch with the payload file and an automatically generated description of the changes to be pushed, ensuring that data security best practices are followed and enabling the team to retain control over the promotion process. Once the pull request has been approved, a CI/CD pipeline is triggered. This pipeline performs data validations, merges the changes into the production control table, and, if successful, triggers the execution of the ingestion pipeline in production. The following image shows an overview of the CI/CD pipeline:
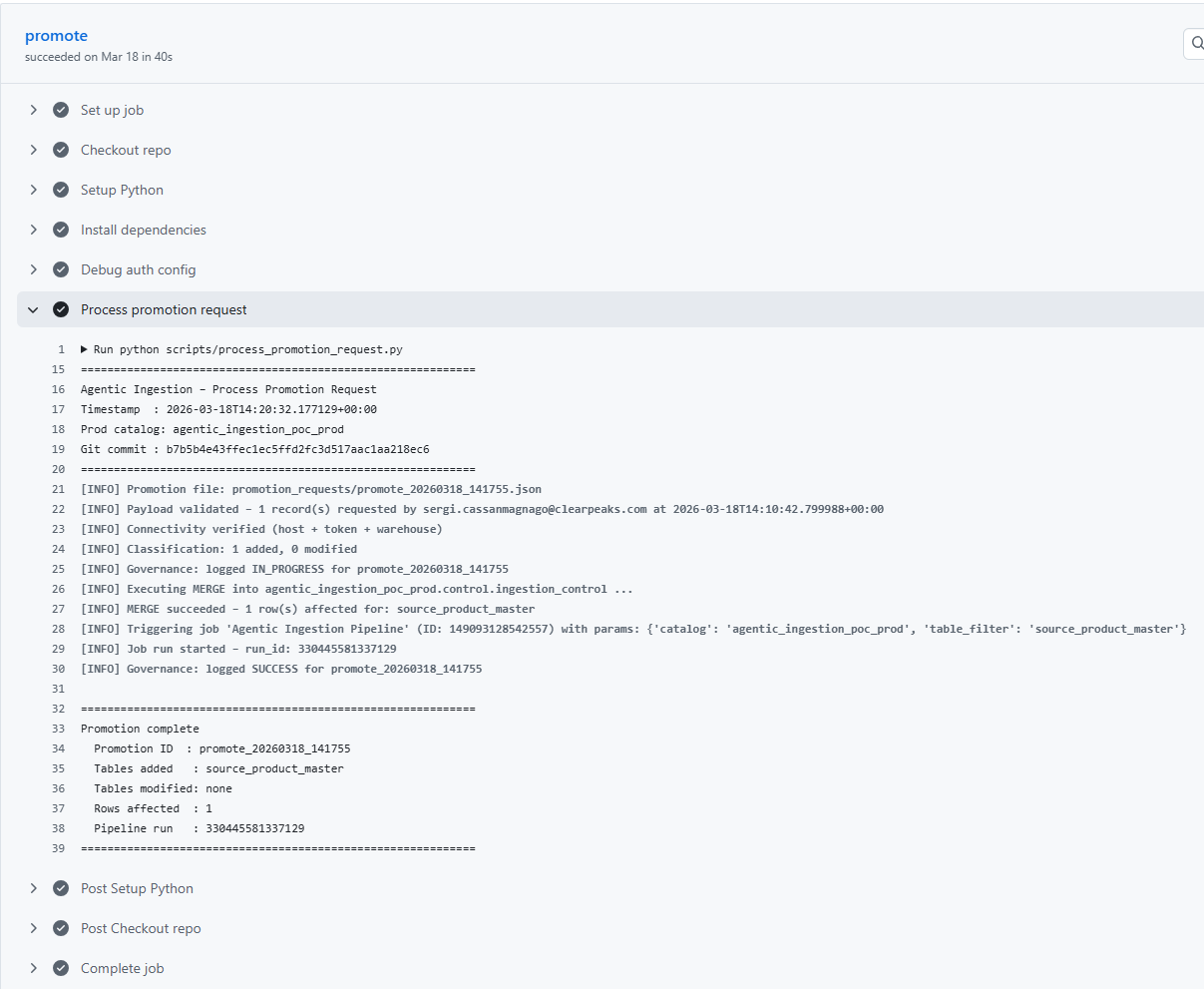
Figure 4: Sample CI/CD pipeline execution for promotion to production
The following diagram shows the promotion-to-production solution described above:
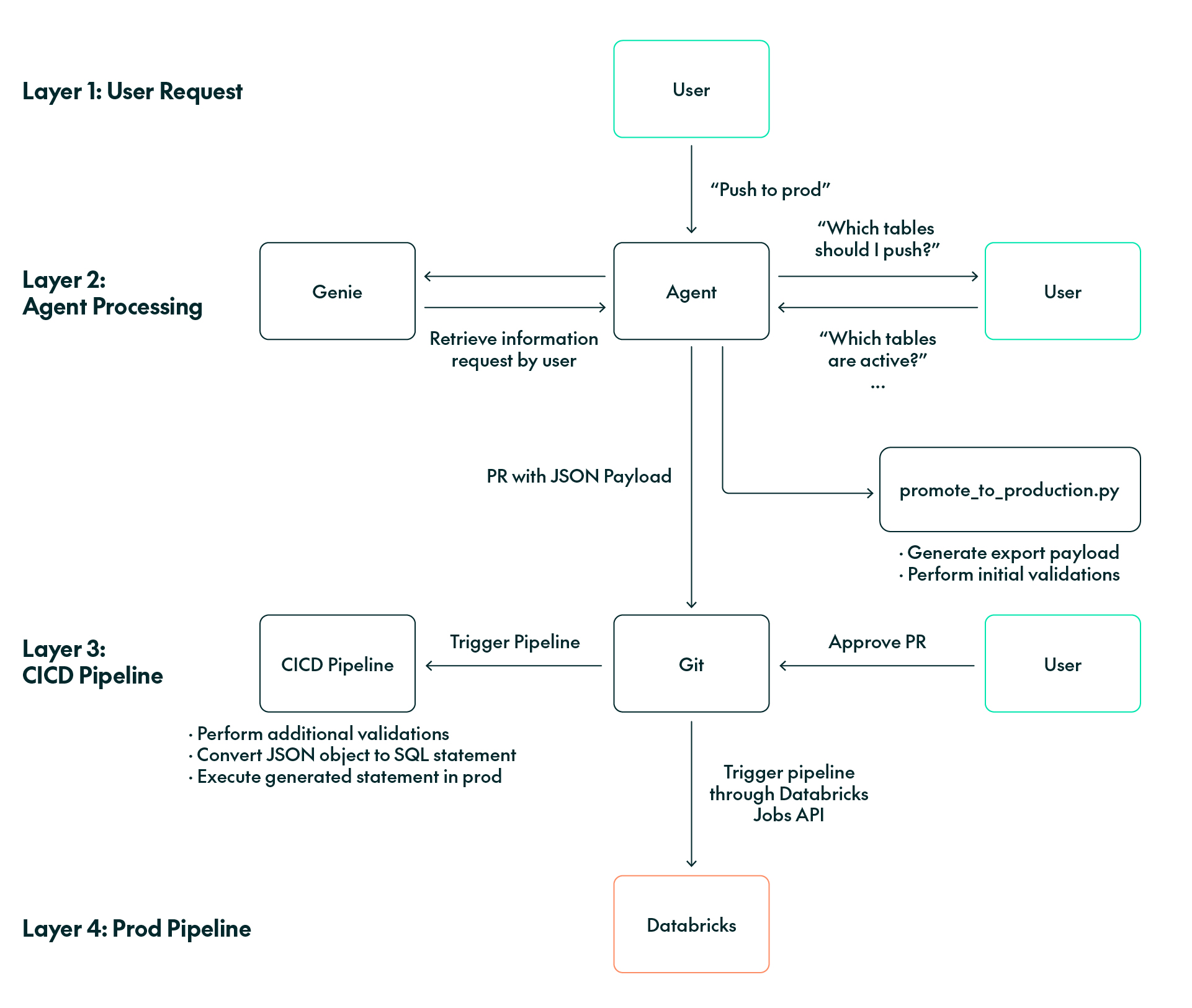
Figure 5: Promotion-to-production workflow
Conclusions
Having developed a full agentic ingestion solution in Databricks covering the data ingestion lifecycle, we determined that the agent and its components worked as expected in the development environment. Genie answered questions effectively and could be used natively as an MCP server; the agent correctly redirected questions to it. The other features we developed worked well, although they could not be declared as MCP servers with Unity Catalog functions as we initially intended because of the Spark context limitations mentioned above, so we had to use LangChain tools instead.
When creating the production environment, we realised that agents interacting with these environments should not perform activities beyond reading. Agents with write permissions should always remain in lower environments and never have access to production.
Finally, Databricks continues to expand its native capabilities for developing agents, with no-code tools like Agent Bricks enabling simpler agent creation. However, more complex solutions like the one we developed, using LangChain tools, are not currently supported in Agent Bricks, and components such as promotion to production still require custom implementations.
While building components that may soon become obsolete may seem like a wasted effort, we found that integrating agentic capabilities into data ingestion can still provide significant benefits, especially when a lack of automation is already affecting an organisation’s ability to ingest new data sources efficiently. It can also help to prepare for future integration with native Databricks agentic capabilities, making that integration smoother when those capabilities become available.
Having completed this agentic ingestion solution, we are now looking for ways to accelerate data engineering by applying AI to the next phase of the data lifecycle: processing the data after it has been successfully ingested. Our aim is to explore how the agent could help to develop ETL processes based on the ingested data.
If you have any questions about integrating AI into your organisation, don’t hesitate to contact us. We’ll be more than happy to help you to unlock the potential of your data!
