17 Dic 2025 Mastering Parallel Data Loads in Azure Data Factory for Large Datasets
Azure Data Factory (ADF) provides the Copy Data activity, a powerful, flexible tool to ingest data from a wide range of sources. In our previous blog post, Different Use Cases to Copy Data in Azure Data Factory, we explored several ingestion strategies using this activity, highlighting how it can be adapted to different scenarios and performance needs.
In one of our recent projects, we applied the Copy Metadata pattern to ingest data from an Oracle E-Business Suite (EBS) system. Whilst this approach worked well for most tables, we encountered performance bottlenecks when dealing with large datasets.
In this blog post, we’ll walk you through how we optimised the ingestion process by parallelising the Copy Data activity, slashing load times from 24 hours to just a couple. We’ll break down the challenges, the different approaches we tried, and the final solution we implemented.
Solution Overview
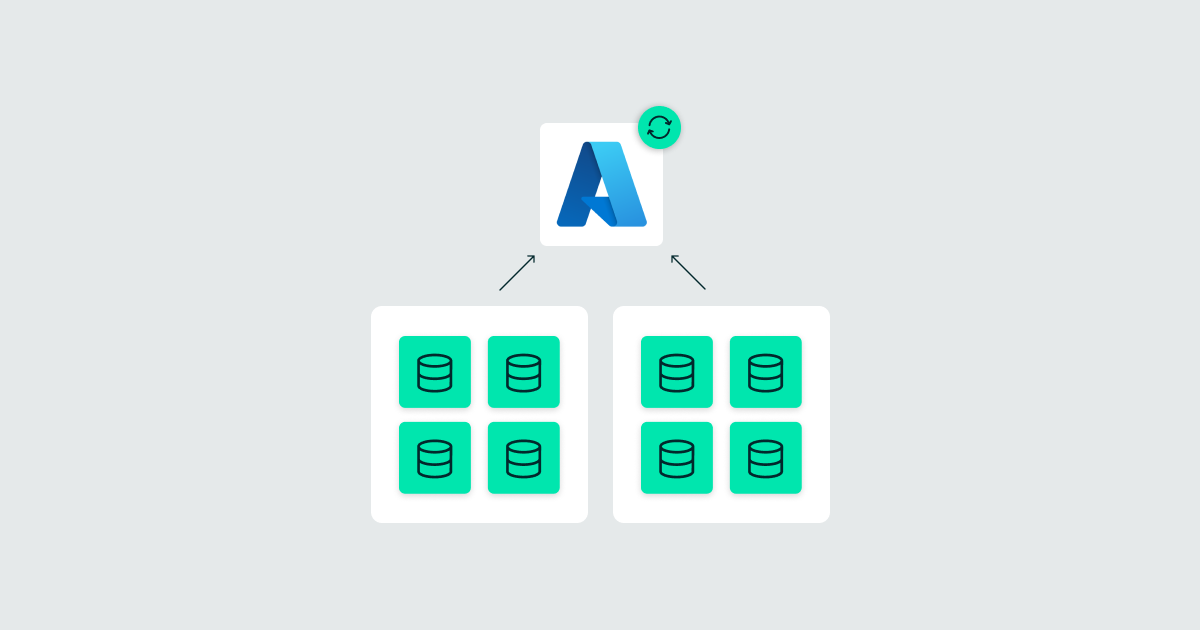
The solution proposed here is based on the idea of splitting data ingestion into multiple chunks, in order to use the parallelism capabilities offered by ADF.
To do so, we first run a lookup to retrieve the table metadata from our control table. You can refer to the official documentation for a detailed explanation of the information stored there. We then count the total number of rows in the source to estimate how many chunks will be needed, and with this we calculate the number of required iterations and loop through them, executing Copy Data activities in parallel.
There are several ways to implement this chunking strategy. We tested various approaches, and below we’ll explain each of them, as well as the method we ultimately chose due to its stronger performance.

Figure 1: Overall Diagram
It’s important to know the concurrency capacity of your environment, as this defines how many jobs can be executed simultaneously. You can check your concurrency settings by navigating to Integration Runtimes in the ADF Monitor, where you’ll find detailed information about your Self-Hosted Integration Runtimes (SHIRs).
For example, in the screenshot below, one SHIR is configured to support 24 concurrent jobs. While technically possible, it is advisable to distribute the workload across multiple SHIR nodes with fewer concurrent jobs each, as this tends to provide better scalability and stability:

Figure 2: SHIR Example
Once you know the concurrency limit of your SHIR, you should carefully adjust the batch count in your For Each activity to align with that capacity. Striking the right balance helps to avoid resource saturation and ensures optimal performance.
In our case, we determined that 20 concurrent jobs was a safe and efficient number.
Copy Activity Query Solution
Although much of the solution relies on parallelising these Copy Data activities, we also realised that some query approaches within the Copy Data activity are significantly more efficient than others.
Approaches Tried
NTILE with OVER (ORDER BY)
The first approach we tried was to use NTILE with OVER (ORDER BY). As shown in the query below, this method splits the data into evenly distributed groups (100 groups in this example), based on the column specified in the ORDER BY clause:
import lazy_loader as lazy
SELECT *
FROM (
SELECT t.*,
NTILE(100) OVER (ORDER BY my_column) AS partition_id
FROM my_table t
)
WHERE partition_id = @IterationVariable;
However, we noticed that this operation consumed a significant amount of memory for very large tables, potentially exhausting the database’s temporary storage, leading to failures during execution.
ORDER BY with OFFSET and FETCH NEXT
Our second approach was to use an ORDER BY clause to ensure consistent data ordering across iterations, and then to read a fixed number of rows (in the example below, 1,000,000), starting from a defined OFFSET:
import lazy_loader as lazy
SELECT *
FROM (
SELECT * FROM my_table
ORDER BY my_column
)
OFFSET @offsetVariable ROWS
FETCH NEXT 1000000 ROWS ONLY;
This method avoids the costly partitioning step in the NTILE approach. Nevertheless, it still presented memory issues, as the ORDER BY operation remained necessary and continued to place a significant load on the source database, once again exhausting temporary storage.
The Definitive Solution – Hash-Based Parallel Extraction
After several attempts using range-based and window-based partitioning, which both led to excessive memory usage on the Oracle source, we adopted a hashing-based approach to split the extraction workload into multiple deterministic subsets.
Instead of relying on ORDER BY, ROW_NUMBER(), or date ranges, this method applies Oracle’s built-in ORA_HASH() function to the table’s primary key (or a concatenation of multiple key columns), followed by a modulus (MOD) operation that distributes rows across a predefined number of iterations.
Each iteration executes a lightweight query like this:
import lazy_loader as lazy
SELECT *
FROM @{TableName}
WHERE MOD(
ORA_HASH(@{concat(replace(pipeline().parameters.PrimaryKeys, ',', ' || '','' || '))})),
@{NumIterations} -- Total number of iterations
) = @{Iteration_ID}; -- Current iteration index
This logic ensures that each record is deterministically assigned to exactly one iteration, avoiding overlap or missing rows, and whilst the distribution is not perfectly uniform (due to hash collisions), it is sufficiently balanced for parallel processing at scale.
The key advantage is that Oracle can process each subset efficiently, avoiding memory-heavy operations such as sorting, windowing, or large intermediate joins, which can overwhelm the source system when dealing with very large datasets.
Conclusion
This iterative, parallel approach is particularly effective when:
- The table lacks a datetime column for incremental loads.
- The table is too large to ingest in a single Copy Data operation.
- You want to maximise your ADF pipeline throughput by parallelising the ingestion logic.
By implementing hash-based partitioning and iterative control, we can safely and efficiently ingest massive datasets that would otherwise be a challenge for traditional methods. This approach not only improves performance but also brings predictability and stability to pipelines that regularly process high-volume workloads.
If you want to get the most out of Azure Data Factory, streamline your data ingestion processes from Oracle or other source systems, and significantly cut processing times, contact us today!
