15 Apr 2019 Cloud Analytics on Azure: Databricks vs HDInsight vs Data Lake Analytics
2019 is proving to be an exceptional year for Microsoft: for the 12th consecutive year they have been positioned as Leaders in Gartner’s Magic Quadrant for Analytics and BI Platforms:
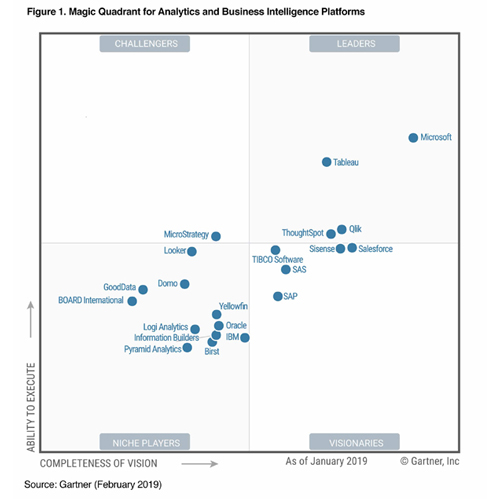
As a Microsoft Gold Partner, and having delivered many projects using the Azure stack, it’s easy to see why: as Cloud technologies have become key players in BI and Big Data, Microsoft has worked wonders to create Azure, a platform that exploits the main benefits of Cloud (agility, reliability and cost) and helps all kinds of enterprise to achieve their maximum potential thanks to its flexibility.
In What can Cloud do for BI and Big Data?, we explored the different Cloud service models and how they compare to an on-premise deployment. In the Azure ecosystem, there are three main PaaS (Platform as a Service) technologies that focus on BI and Big Data Analytics:
- Azure Data Lake Analytics (ADLA)
- HDInsight
- Databricks
Deciding which to use can be tricky as they behave differently and each offers something over the others, depending on a series of factors.
At ClearPeaks, having worked with all three in diverse ETL systems and having got to know their ins and outs, we aim to offer a guide that can help you choose the platform that best adapts to your needs and helps you to obtain value from your data as quickly as possible.
Let’s review them one by one:
1. Azure Data Lake Analytics
Azure Data Lake is an on-demand scalable cloud-based storage and analytics service. It can be divided in two connected services, Azure Data Lake Store (ADLS) and Azure Data Lake Analytics (ADLA). ADLS is a cloud-based file system which allows the storage of any type of data with any structure, making it ideal for the analysis and processing of unstructured data.
Azure Data Lake Analytics is a parallelly-distributed job platform which allows the execution of U-SQL scripts on Cloud. The syntax is based on SQL with a twist of C#, a general-purpose programming language first released by Microsoft in 2001.
The general idea of ADLA is based on the following schema:
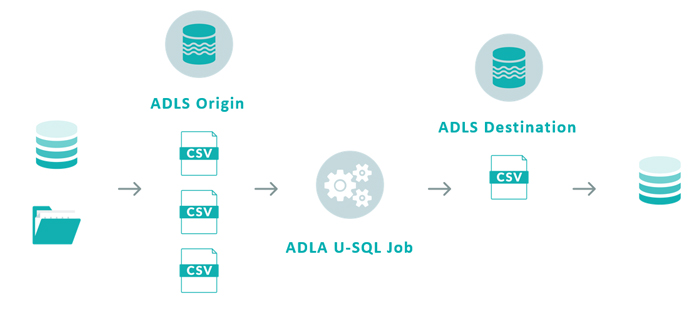
Text files from different sources are stored in Azure Data Lake Store and are joined, manipulated and processed in Azure Data Lake Analytics. The results of the operation are dumped into another location in Azure Data Lake Store.
ADLA jobs can only read and write information from and to Azure Data Lake Store. Connections to other endpoints must be complemented with a data-orchestration service such as Data Factory.
2. HDInsight
Azure HDInsight is a cloud service that allows cost-effective data processing using open-source frameworks such as Hadoop, Spark, Hive, Storm, and Kafka, among others.
Using Apache Sqoop, we can import and export data to and from a multitude of sources, but the native file system that HDInsight uses is either Azure Data Lake Store or Azure Blob Storage.
Of all Azure’s cloud-based ETL technologies, HDInsight is the closest to an IaaS, since there is some amount of cluster management involved. Billing is on a per-minute basis, but activities can be scheduled on demand using Data Factory, even though this limits the use of storage to Blob Storage.
3. Databricks
Azure Databricks is the latest Azure offering for data engineering and data science. Databricks’ greatest strengths are its zero-management cloud solution and the collaborative, interactive environment it provides in the form of notebooks.
Databricks is powered by Apache Spark and offers an API layer where a wide span of analytic-based languages can be used to work as comfortably as possible with your data: R, SQL, Python, Scala and Java. The Spark ecosystem also offers a variety of perks such as Streaming, MLib, and GraphX.
Data can be gathered from a variety of sources, such as Blob Storage, ADLS, and from ODBC databases using Sqoop.
4. Azure ETL showdown
Let’s look at a full comparison of the three services to see where each one excels:
| ADLA | HDInsight | Databricks | |
| Pricing | Per Job | Per Cluster Time | Per Cluster Time (VM cost + DBU processing time) |
| Engine | Azure Data Lake Analytics | Apache Hive or Apache Spark | Apache Spark, optimized for Databricks since founders were creators of Spark |
| Default Environment | Azure Portal, Visual Studio | Ambari (HortonWorks), Zeppelin if using Spark | Databricks Notebooks, RStudio for Databricks |
| De Facto Language | U-SQL, (Microsoft) | HiveQL, open source | R, Python, Scala, Java, SQL, mostly open-source languages |
| Integration with Data Factory | Yes, to run U-SQL | Yes, to run MapReduce jobs, Pig, and Spark scripts | Yes, to run notebooks, or Spark scripts (Scala, Python) |
| Scalability | Easy, based on Analytics Units | Not scalable, requires cluster shutdown to resize | Easy to change machines and allows autoscaling |
| Testing | Tedious, each query is a paid script execution, and always generates output file (Not interactive) | Easy, Ambari allows interactive query execution (if Hive). If using Spark, Zeppelin | Very easy, notebook functionality is extremely flexible |
| Setup and managing | Very easy as computing is detached from user | Complex, we must decide cluster types and sizes | Easy, Databricks offers two main types of services and clusters can be modified with ease |
| Sources | Only ADLS | Wide variety, ADLS, Blob and databases with sqoop | Wide variety, ADLS, Blob, flat files in cluster and databases with sqoop |
| Migratability | Hard, every U-SQL script must be translated | Easy as long as new platform supports MapReduce or Spark | Easy as long as new platform supports Spark |
| Learning curve | Steep, as developers need knowledge of U-SQL and C# | Flexible as long as developers know basic SQL | Very flexible as almost all analytic-based languages are supported |
| Reporting services | Power BI | Tableau, Power BI (if using Spark), Qlik | Tableau, open-source packages such as ggplot2, matplotlib, bokeh, etc. |
5. Use case in all three platforms
Now, let’s execute the same functionality in the three platforms with similar processing powers to see how they stack up against each other regarding duration and pricing:
In this case, let’s imagine we have some HR data gathered from different sources that we want to analyse. On the one hand, we have a .CSV containing information about a list of employees, some of their characteristics, the employee source and their corresponding performance score.
On the other hand, from another source, we’ve gathered a .CSV that tells us how much we’ve invested in recruiting for each platform (Glassdoor, Careerbuilder, Website banner ads, etc).
Our goal is to build a fact table that aggregates employees and allows us to draw insights from their performance and their source, to pursue better recruitment investments.
5.1. ADLA:
In ADLA, we start off by storing our files in ADLS:
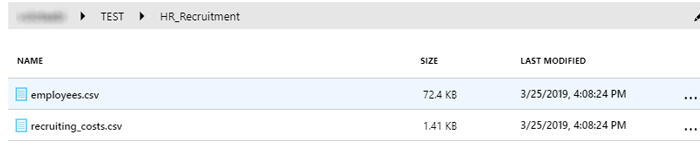
We then proceed to write the U-SQL script that will process the data in the Azure portal:
DECLARE @employee_file string = "/TEST/HR_Recruitment/employees.csv"; DECLARE @costs_file string = "/TEST/HR_Recruitment/recruiting_costs.csv"; DECLARE @fact_output string = "/TEST/HR_Recruitment/output/fact.csv"; // Input rowset extractions and column definition @input_employee = EXTRACT [Employee Name] string ,[Employee Number] string ,[State] string ,[Zip] string ,[DOB] DateTime ,[Age] int ,[Sex] string ,[MaritalDesc] string ,[CitizenDesc] string ,[Hispanic/Latino] string ,[RaceDesc] string ,[Date of Hire] DateTime ,[Date of Termination] DateTime? ,[Reason For Term] string ,[Employment Status] string ,[Department] string ,[Position] string ,[Pay Rate] float ,[Manager Name] string ,[Employee Source] string ,[Performance Score] string FROM @employee_file USING Extractors.Csv(skipFirstNRows:1); @input_costs = EXTRACT [Employee Source] string ,[January] int ,[February] int ,[March] int ,[April] int ,[May] int ,[June] int ,[July] int ,[August] int ,[September] int ,[October] int ,[November] int ,[December] int ,[Total] int FROM @costs_file USING Extractors.Csv(skipFirstNRows:1); // We now grab the info we actually need and join by employee source: @employee_performance = SELECT [Employee Number] AS emp_id, [Employee Source] AS emp_source, [Performance Score] AS performance_score FROM @input_employee; @recruitment_costs = SELECT [Employee Source] AS emp_source, [Total] AS total_cost FROM @input_costs; @fact_performance_recruitment_costs = SELECT ep.performance_score, rc.emp_source, rc.total_cost FROM @employee_performance AS ep INNER JOIN @recruitment_costs AS rc ON rc.emp_source == ep.emp_source; @fact_performance_recruitment_costs = SELECT performance_score, emp_source, total_cost, COUNT(1) AS total_employees FROM @fact_performance_recruitment_costs GROUP BY performance_score, emp_source, total_cost; // Output the file to ADLS OUTPUT @fact_performance_recruitment_costs TO @fact_output USING Outputters.Csv(outputHeader:true,quoting:true);
After running, we can monitor how this job was executed and how much it cost in the Azure Portal for ADLA:
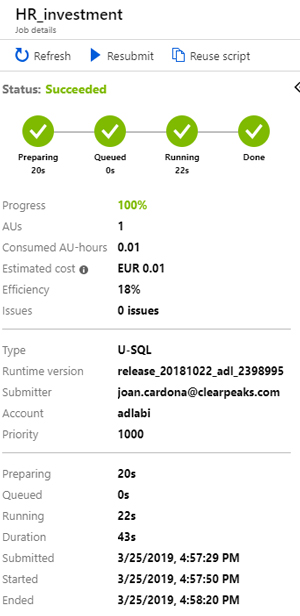
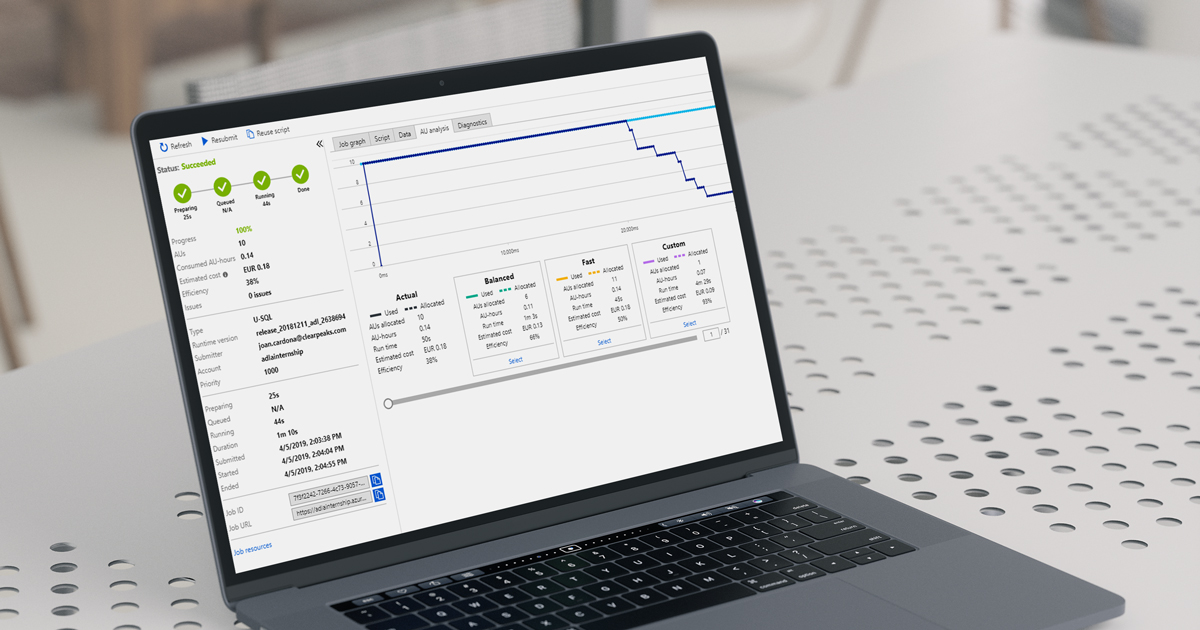
As we can see, the total duration was 43 seconds and it had an approximate cost of 0.01€.
The ADLA Service offers a neat functionality that tells us the efficiency of any job after running it, so we know if it’s worth augmenting or reducing the AUs of the job (the computing power).
Here we can see another job with 1 allocated AU: it recommends increasing the AUs for the job, so it runs 85.74% faster, but it also costs more.
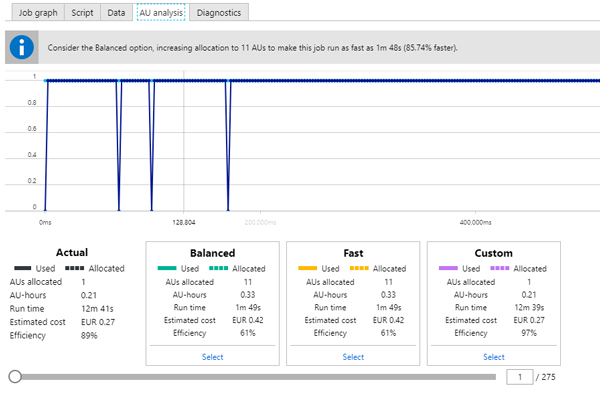
It’s worth considering, but in cases like this, higher speed is unnecessary, and we prefer the reduced costs.
5.2. HDInsight:
In this case, we store the same files in ADLS and execute a HiveQL script with the same functionality as before:
CREATE TABLE IF NOT EXISTS hr_recruitment_employees
(
EmployeeName varchar(500)
,EmployeeNumber varchar(500)
,State varchar(50)
,Zip varchar(500)
,DOB varchar(500)
,Age int
,Sex varchar(50)
,MaritalDesc varchar(50)
,CitizenDesc varchar(50)
,Hispanic_Latino varchar(50)
,RaceDesc varchar(50)
,DateofHire varchar(50)
,DateofTermination varchar(50)
,ReasonForTerm varchar(50)
,EmploymentStatus varchar(50)
,Department varchar(50)
,Position varchar(50)
,PayRate float
,ManagerName varchar(50)
,EmployeeSource varchar(50)
,PerformanceScore varchar(50)
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
"separatorChar" = ",",
"quoteChar" = "\"" --"
)
STORED AS TEXTFILE LOCATION 'adl://cphdinsight.azuredatalakestore.net/TEST/HR_Recruitment/HDI/input_employees'
tblproperties ("skip.header.line.count"="1");
CREATE TABLE IF NOT EXISTS hr_recruitment_costs
(
EmployeeSource string
,January int
,February int
,March int
,April int
,May int
,June int
,July int
,August int
,September int
,October int
,November int
,December int
,Total int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
"separatorChar" = ",",
"quoteChar" = "\"" --"
)
STORED AS TEXTFILE LOCATION 'adl://cphdinsight.azuredatalakestore.net/TEST/HR_Recruitment/HDI/input_costs'
tblproperties ("skip.header.line.count"="1");
CREATE TABLE fact_perf_recruitment_costs AS
select
PerformanceScore,
EmployeeSource,
Total,
count(1) as TotalEmployees
from
(select
ep.PerformanceScore,
rc.EmployeeSource,
rc.Total
from hr_recruitment_employees ep
inner join hr_recruitment_costs rc
on ep.EmployeeSource = rc.EmployeeSource) joined_rc
group by
PerformanceScore,
EmployeeSource,
Total;
In this case the duration of the creation of the two temporary tables and their join to generate the fact took approximately 16 seconds:

Taking into account the Azure VMs we’re using (2 D13v2 as heads and 2 D12v2 as workers), following the pricing information (https://azure.microsoft.com/en-au/pricing/details/hdinsight/) this activity cost approximately 0.00042 €, but as HDInsight is not an on-demand service, we should remember that per-job pricings are not as meaningful as they were in ADLA.
Another important thing to mention is that we are running Hive in HDInsight. As Hive is based on MapReduce, small and quick processing activities like this are not its strength, but it shines in situations where data volumes are much bigger and cluster configurations are optimized for the type of jobs they must execute.
5.3. Databricks:
Finally, after loading data from ADLS using a Mount point, we execute a notebook to obtain a table which can be accessed by anyone with credentials to use the cluster and its interactive notebooks:
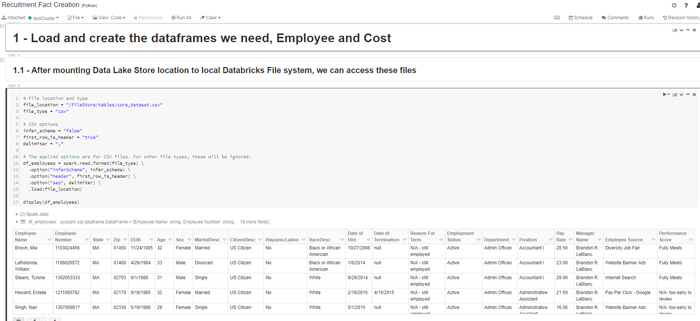
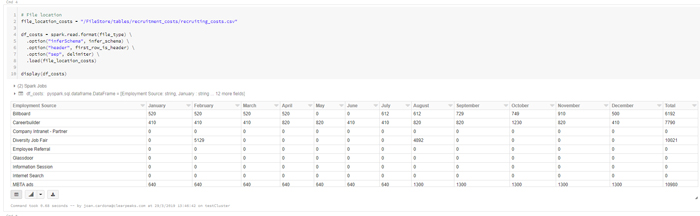
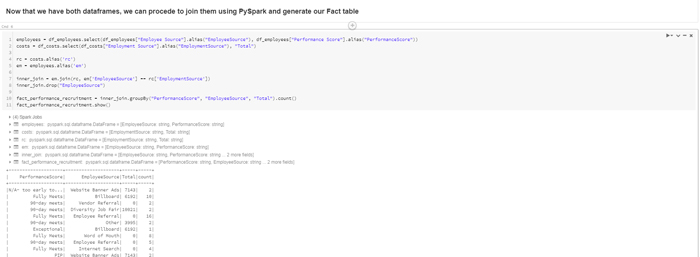
We finally save it as a table to be accessed by anyone who needs it, and queries can be launched at it using SQL, to make it easier for users who know one but not the other:
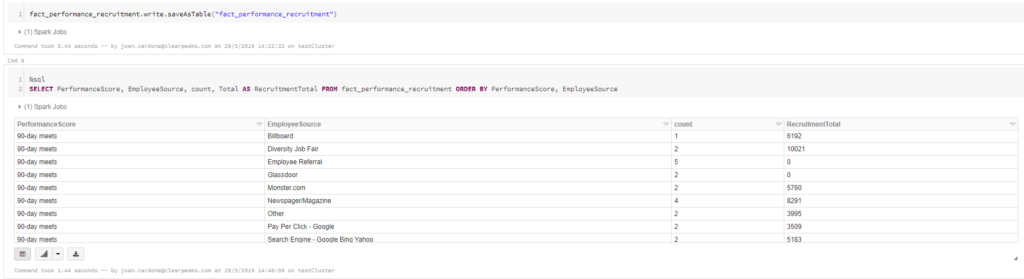
Having these final fact tables, plus the ease of running a quick analysis in our notebook, we can answer questions like “Where are we, as a company, getting our better performers and how much are we spending on those platforms?” This can help companies detect steep spending without many returns so as to avoid them, or invest more money where the better performers come from:
Using Pandas and Matplotlib inside the notebook, we can sketch the answer to this question and draw our corresponding insights:
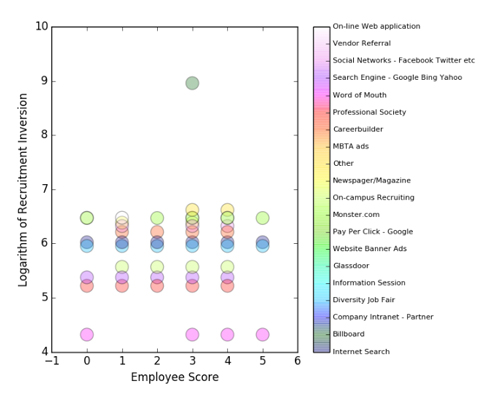
It seems balanced, but we can see that too much has been spent on Billboard advertising for just one recruit whose performance is only middling.
In this case, the VMs we’re using are 3 Standard_D3_v2, and the notebook took a total of approximately 5 seconds, which in pricing information reflects a total of 0.00048 €. In this case, however, Spark is optimized for these types of job, and bearing in mind that the creators of Spark built Databricks, there’s reason to believe it would be more optimized than other Spark platforms.
6. Big Data Situations
Until now we’ve seen how these systems deal with reasonably small datasets. To fully unleash their potential, we will proceed to study how they react to a much bigger file with the same schema and comment on their behaviour. The employee file size is now 9.5 GB, but the script will be the same.
6.1. ADLA:
When executing the ADLA job, these are the results we obtain:
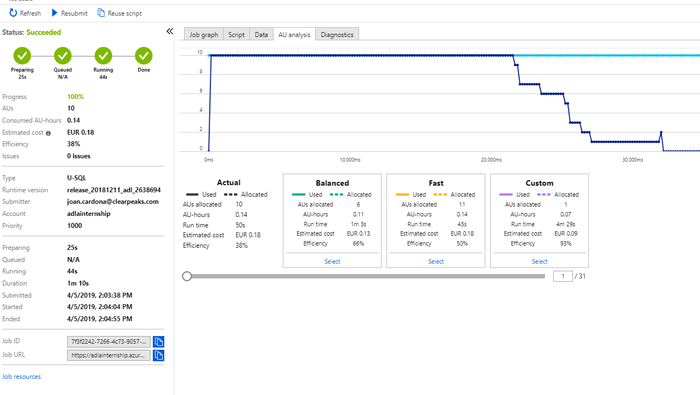
In this case, we allocated 10 AUs for the job, but we see that the AU analysis gives us a more balanced option of 6 AUs that takes a little longer but is also cheaper. The total cost was 0.18€ just for this one job.
6.2. HDInsight:
In HDInsight we execute the same query with the larger dataset in the same configuration we used before to compare pricings (which are based on cluster times) and we achieve the following Query Execution Summary:
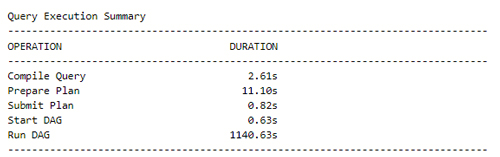
In this case the query took approximately 20 minutes. According to the pricings of the cluster configuration we are using, this corresponds to an estimated cost of 0.63 €. In this case it’s clear we should use a more powerful cluster configuration in order to balance out the time of execution; if we had to run a lot of tasks like this, each would need to take much less than 20 minutes. This is a good example of when scaling becomes tedious: since we now know that this cluster is not appropriate for our use case, we must eliminate the cluster and create a new one and see if it’s what we’re looking for. We can also see that it’s about 4 times more expensive than the ADLA job, as well as not showing us what an appropriate cluster configuration would be.
6.3. Databricks:
In the Databricks service, we create a cluster with the same characteristics as before, but now we upload the larger dataset to observe how it behaves compared to the other services:

As we can see, the whole process took approximately 7 minutes, more than twice as fast as HDInsight with a similar cluster configuration. In this case, the job cost approximately 0.04€, a lot less than HDInsight. This is a good example of how Spark jobs can generally run faster than Hive queries.
Conclusion
As we have seen, each of the platforms works best in different types of situation: ADLA is especially powerful when we do not want to allocate any amount of time to administrating a cluster, and when ETLs are well defined and are not subject to many changes over time. It also helps if developers are familiar with C# to get the full potential of U-SQL.
On the other hand, HDInsight has always been very reliable when we know the workloads and the cluster sizes we’ll need to run them. Scaling in this case is tedious, are machines must be deleted and activated iteratively until we find the right choice. Using Hive is a perk, as its being open source and very similar to SQL allows us to get straight down to developing without further training. By using Hive, we take full advantage of MapReduce power, which shines in situations where there are huge amounts of data.
And finally, Databricks seems an ideal choice when the notebook interactive experience is a must, when data engineers and data scientists must work together to get insights from data and adapt smoothly to different situations, as scalability is extremely easy. Another perk of using Databricks is its speed, thanks to Spark.
If you’d like to know more about the questions raised in this brief article, please don’t hesitate to contact us here at ClearPeaks – we´ll be glad to help!