
20 Mar 2019 The new Cloudera Data Platform
This year we were at the DataWorks Summit in Barcelona, and if you are already following ClearPeaks then you will know that we are quite active in this summit. First, we hosted a meetup to review the tools to maximize development efficiency in Cloudera clusters. Second, we delivered a talk in which we detailed the Big Data Cloud journey we took with one of our customers.
As a Silver Cloudera partner, we were also part of the Cloudera Partner Accelerator prior to the DataWorks Summit. For ClearPeaks this partner event was very exciting for a couple of special reasons (as well as the usual reasons to attend such events): our HQ is in the city, so it is nice to play local for a change, and also this was one of the first partner events after the Cloudera – Hortonworks merger so we, like many other partners, were looking for a lot of answers to a lot of questions, and I am happy to say that we got a fair amount of answers, some of them quite juicy!
In this blog post we will cover some of the interesting things we extracted from this partner event. There are new developments and changes in many areas of the new Cloudera company and its products (just in case you did not know, the company resulting of the merger is called Cloudera).
The most fascinating things we discovered were about the technical roadmap of the new Cloudera product. Before this meeting we were wondering what would happen to CDH and HDP, the old products of the legacy companies. Would both be maintained? Would they merge into CDH version 7? The answer is that they will merge into a new product called Cloudera Data Platform (whose first release will presumably be version 1.0.0). While we wait for the new CDP, the recommendation for new deployments is, in general, to install CDH in either version 5.15 or 6.2 (coming in few weeks), since the upgrade to the new CDP from these versions will be much easier (and also direct migration will be possible from 5.15 to CDP without intermediate migration to 6). There may be some cases where it is recommended to go with HDP, depending on the type of workloads that you want to tackle. For more details on which way to go, do not hesitate to contact us.
From a technical point of view, the first development was the release of Cloudera Data Flow (CDF), essentially the rebranding of the legacy Hortonworks Data Flow (HDF), and it includes NiFi, MiNiFi, Edge Flow Manager, etc. To paraphrase Cloudera representatives, CDF is a scalable, real-time data platform that collects, curates and analyses data so customers gain key insights for immediate actionable intelligence.
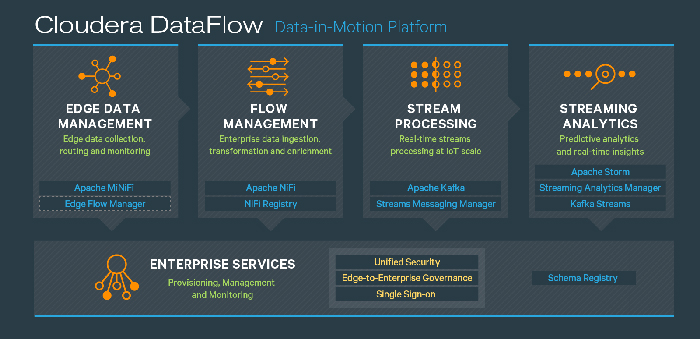
CDF is open source and it comes with 280 pre-built processors and 3 streaming analytic engines. It is something that was missing in the legacy Cloudera, so it makes a lot of sense that this is the very first thing to be integrated, and it will be available in later releases of CDH, even before the actual first release of CDP.
We also learned what services will ship on the new CDP, and what will happen to some of the services we love and use today. First, Cloudera Manager will be the tool to manage the new CDP in detriment of Ambari. We are very happy with this decision since we believe Cloudera Manager is richer in functionality when compared to Ambari. Another interesting point of the technical merger is what will happen to Impala and Hive LLAP. Will one of them disappear? Will they merge? The answer is that both will be there, and depending on the use case, one or the other will be recommended. In scenarios where the caching and ACID capabilities of Hive-LLAP are needed, we will recommend that tool, for example in cases where the set of analytical queries that are executed are always the same, but in scenarios where the analytical queries are free-form and we cannot pre-define a set, we would go for an Impala approach.
Another interesting change is in security. Ranger will be pushed in detriment of Sentry, but some of the features from Sentry will be integrated in later Ranger versions. Phoenix, the service that brings SQL to Hbase, will be integrated in CDH (later this year) and will be a full citizen of the upcoming CDP. Additionally, Cloudera Data Science Workbench is now certified to work on HDP.
For readers used to CDH, we also found other additions that will be incorporated, such as Workload Experience Manager (WXM) to detect workload performance issues (for example “Why is my Impala query slow?”), Metron for cyber security, migration tools such as Navigator Optimizer (to see which queries on the source systems are the most demanding), etc.
There was also discussion on how the technical merger affects Cloudera Data Warehouse (CDW) and we can clearly see that with the addition of Druid, Hive-LLAP, Ranger and Hive on Tez on the set of tools that comprise Cloudera Data Warehouse, the whole product is now much more complete; we even got some tips on which legacy distro to use (while waiting for CDP), depending on the dominant workload when tackling CDW solutions. For more details, talk to us!
But as we mentioned earlier, what we liked most about the event were the details we learned about the new CDP.
1. Cloudera Data Platform
The new CDP distribution will get the best of the existing CDH and HDP plus some very interesting new additions. Following the HDP approach, the CDP distribution will eventually be fully open source (though it may be a while until we get there). CDP will be a very complete platform able to tackle applications from Edge to AI, i.e. in the five different analytic workloads: Data Flow & Streaming, Data Engineering, Data Warehousing (both on structured but also un-structured and semi-structured), Operational Database and AI & Machine Learning.
So, Cloudera with its CDP, will be a one-stop for all analytics workloads in a unified data architecture, offering the possibility of deployment on hybrid and multi-cloud environments, which is the type of environments that large companies in the world are moving towards (by the way, most of them are Cloudera customers).

We also learned what we will find in the new (and last) releases of CDH and HDP. In CDH, the addition of Cloudera Data Flow, Phoenix and Metro. And in HDP, the addition of CDSW and Cloudera Search.
On top of the changes we already discussed, CDP will have a new interaction model. One will be able to give to each application an instance of the cluster (with a different version and configuration of CDP). For example, for our Data Warehouse app (DW-X) we may have a distro-X which may be a different version compared to the distro used for the streaming application. This will bring greater agility in creating our applications.
CDP will also represent:
- A new computing mode very much focussed on containerization, for greater efficiency.
- A new management framework based on a unified control plane (Altus DataPlane), with unified data management on top of the already existing Shared Data eXperience (SDX), for greater scale.
- A new form factor for the cloud. CDP will be available as a public cloud service on Azure and AWS and will be tightly integrated with cloud storage and compute services, simplifying operations.
- New portability and migration tools for a hybrid world.
- A new development model with faster and more recent updates, for faster execution and integration of changes.
However, we still need to wait a few months for the first release of CDP. If in the meantime you have any questions about what to expect from it or about how to migrate, or you have any other Big Data & AI needs, do not hesitate to contact us. We will be happy to help you!
