06 Jun 2018 ODI 11g Repository metadata: Tips and tricks
Oracle Data Integrator (ODI) is a complete ELT tool with many functionalities that allow developments at all levels of complexity. It can accommodate everything from the simplest extraction and data replications to the most complex logic. However, its abstract design and intricate usability can slow down development, debugging, and maintenance activities, especially in large projects with many components and a big development team involved.
Following naming conventions and best practices, while maintaining complete documentation, can help with navigating throughout this ocean of objects and folders; however, in this article, we will cover a more technical navigation approach: directly querying the ODI (11g) repository to retrieve the metadata of the different ODI objects (models, interfaces, scenarios and load plans). All these objects and more are stored in an SQL schema, so if the proper tables and join conditions are known, a lot of information can easily be extracted.
We’ll be covering some examples that can be used to analyze several ODI objects at a glance, which speed up development and troubleshooting tasks. It is structured in three different sections (ODI components). We’ll go from a simple query of the main repository table to a more complex and useful one:
- Models, datastores and columns
- Interfaces
- Scenarios
WARNING! The below queries have to be executed against the ODI repository database schema. Hence, it is important to be extremely careful with the executions, especially with the update statements. Any inconsistency in the tables might corrupt the ODI objects or even the whole environment. You must replicate the below at your own risk. Do all the necessary backups and precautions, and make sure to fully understand the code below before executing it.
1. Models, datastores and columns
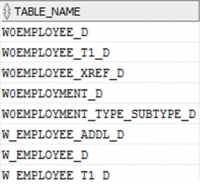
Let’s start with a simple query. We would like to have the list of ODI tables (stored in SNP_TABLE) that have a given name pattern:
select T.TABLE_NAME from SNP_TABLE T where 1=1 and T.TABLE_NAME like 'W%EMP%D' order by T.TABLE_NAME;
With some proper joins we can have a list of Models (SNP_MODEL), Sub-Models (SNP_SUB_MODEL) and Tables with the corresponding parent folders (SNP_MOD_FOLDER) and last user/date details:
select distinct --* MF.I_MOD_FOLDER, MF.MOD_FOLDER_NAME, M.I_MOD, M.MOD_NAME, M.LSCHEMA_NAME, M.LAST_DATE MOD_LAST_DATE, M.LAST_USER MOD_LAST_USER, SM.I_SMOD, SM.SMOD_NAME, SM.LAST_DATE SMOD_LAST_DATE, SM.LAST_USER SMOD_LAST_USER, T.I_TABLE, T.TABLE_NAME, T.LAST_DATE TAB_LAST_DATE, T.LAST_USER TAB_LAST_USER from SNP_MODEL M -- PARENT FOLDER left outer join SNP_MOD_FOLDER MF on M.I_MOD_FOLDER = MF.I_MOD_FOLDER -- MODEL left outer join SNP_SUB_MODEL SM on M.I_MOD = SM.I_MOD -- SUB-MODEL left outer join SNP_TABLE T on SM.I_MOD = T.I_MOD and SM.I_SMOD = T.I_SUB_MODEL -- TABLE where 1=1 --and MF.MOD_FOLDER_NAME like '%' --and M.MOD_NAME like '%' --and SM.SMOD_NAME like '%' --and T.TABLE_NAME like '%' order by MF.MOD_FOLDER_NAME, M.MOD_NAME, SM.SMOD_NAME, T.TABLE_NAME;

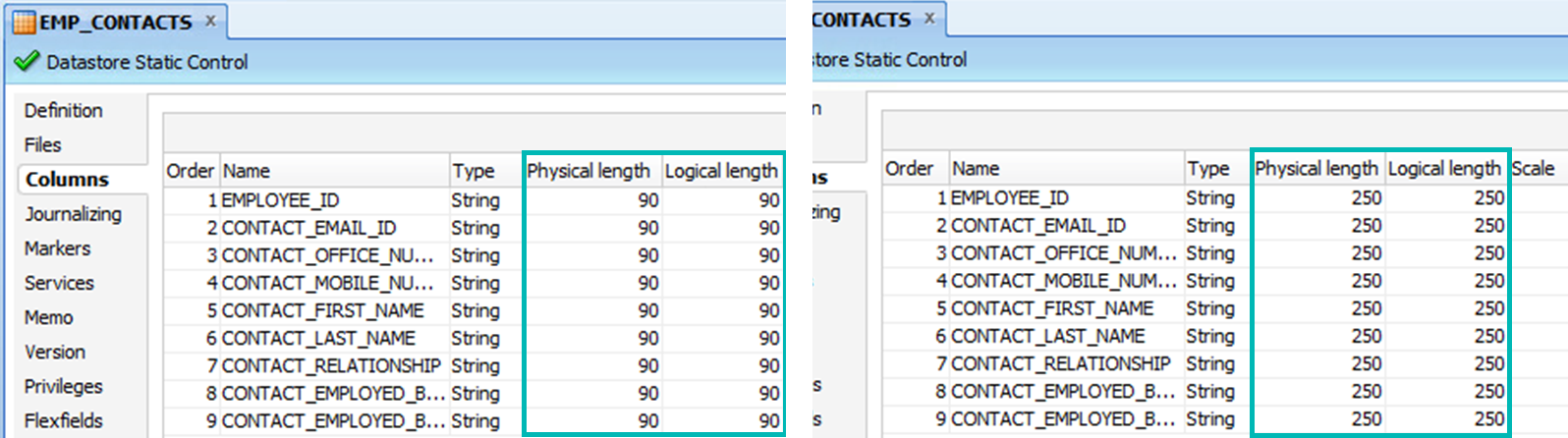
More useful is being able to check (and even update) the properties of the table columns (SNP_COL). For instance, we might want to update the default Physical and Logical lengths of some datastore columns corresponding to flat files in order to avoid truncating the data when loading it. Instead of opening and editing each of them one by one, the query below can be used:
select * from SNP_COL
--update SNP_COL set LONGC = 250 , BYTES = 250
where I_COL in (
select C.I_COL
from SNP_MODEL M
inner join SNP_TABLE T on T.I_MOD = M.I_MOD
inner join SNP_COL C on C.I_TABLE = T.I_TABLE
where 1=1
--and MOD_NAME like 'mod_name'
and T.TABLE_NAME like 'EMP_CONTACTS'
--and SOURCE_DT = 'STRING'
);
commit;
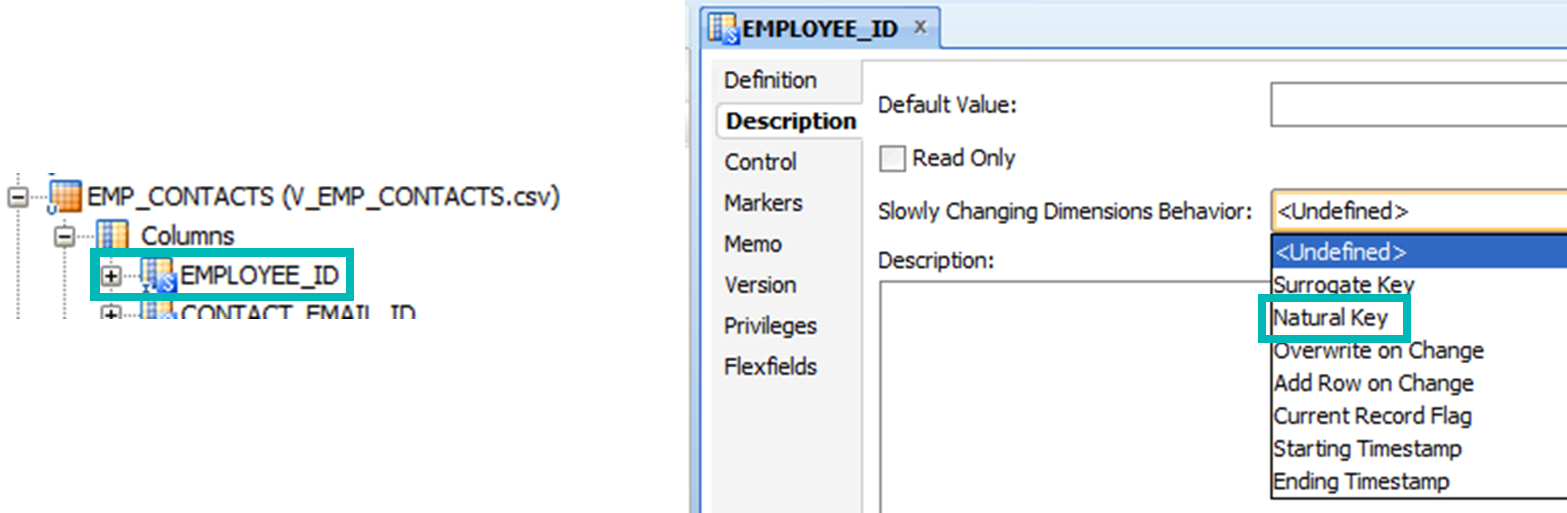
Another interesting use is reviewing/configuring the Slowly Changing Dimensions behavior of the columns of a table, which can be achieved by properly filtering by the desired tables and columns. For instance, the below query can configure the EMPLOYEE_ID column of EMP_CONTACTS as a Natural Key:
select * from SNP_COL
--update SNP_COL set SCD_COL_TYPE = 'NK'
where I_COL in (
select C.I_COL
-- T.TABLE_NAME, C.COL_NAME, C.I_COL, C.SCD_COL_TYPE
from SNP_COL C
inner join SNP_TABLE T on C.I_TABLE = T.I_TABLE
where 1=1
and T.TABLE_NAME = 'EMP_CONTACTS'
and COL_NAME = 'EMPLOYEE_ID'
--and SCD_COL_TYPE <> 'IR'
);
commit;
This is the relation between the different SCD behavior options and the codes to be considered in the query:
- SK: Surrogate Key
- NK: Natural Key
- OC: Overwrite on Change
- IR: Add (Insert) Row on Change
- CR: Current Record Flag
- ST: Starting Timestamp
- ET: Ending Timestamp
2. Interfaces
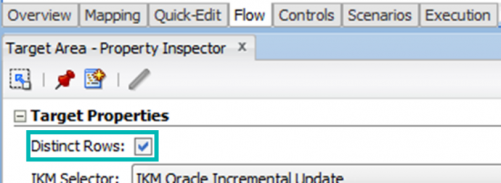
Now we can start by retrieving the list of interfaces (SNP_POP) that satisfy a given condition, such as a filter on the Name, and the Distinct Rows checkbox selected:
Select * from SNP_POP where 1=1 and POP_NAME like '%SDE%' and DISTINCT_ROWS <> 0 order by POP_NAME;
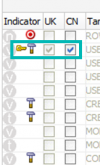
For the target columns of the interfaces (SNP_POP_COL), we can use the query below to check the ones that are specified as Keys or that have Check Not Null option enabled:
select P.POP_NAME, PC.COL_NAME, PC.IND_KEY_UPD, PC.CHECK_NOT_NULL from SNP_POP P inner join SNP_POP_COL PC on P.I_POP = PC.I_POP where 1=1 and (PC.IND_KEY_UPD = 1 or PC.CHECK_NOT_NULL = 1) order by P.POP_NAME, PC.COL_NAME;

We can also analyze the knowledge modules (SNP_TRT) used in the interfaces (for Load, Integration and Control):
select P.POP_NAME, LKM.TRT_NAME LKM, IKM.TRT_NAME IKM, CKM.TRT_NAME CKM from SNP_SRC_SET SRC inner join SNP_DATA_SET D on D.I_DATA_SET = SRC.I_DATA_SET inner join SNP_POP P on P.I_POP = D.I_POP inner join SNP_TRT LKM on LKM.I_TRT = SRC.I_TRT_KLM inner join SNP_TRT IKM on IKM.I_TRT = P.I_TRT_KIM inner join SNP_TRT CKM on CKM.I_TRT = P.I_TRT_KCM where 1=1 and P.POP_NAME like '%SDE%' --and LKM.TRT_NAME like '%' --and IKM.TRT_NAME like '%' --and CKM.TRT_NAME like '%' order by P.POP_NAME;

Much more powerful is the query below, as it shows the actual target mappings of the interfaces. This is really useful for performing data lineage of the final tables, or to look for particular expressions across all interfaces.
select P.POP_NAME, P.TABLE_NAME TARGET_TABLE, PC.COL_NAME TARGET_COLUMN, TXT.STRING_ELT from SNP_POP P inner join SNP_POP_COL PC on P.I_POP = PC.I_POP inner join SNP_POP_MAPPING PM on PC.I_POP_COL = PM.I_POP_COL inner join SNP_TXT_CROSSR TXT on PM.I_TXT_MAP = TXT.I_TXT where 1=1 and TXT.STRING_POS = 0 and P.POP_NAME LIKE '%SDE%' and TXT.STRING_ELT not like '%#%' order by P.POP_NAME, P.TABLE_NAME, PC.COL_NAME, TXT.STRING_ELT;

3. Scenarios
Another interesting table is the one containing the list of scenarios (SNP_SCEN):
select * from SNP_SCEN where 1=1 and SCEN_NAME like '%SDE%' order by SCEN_NAME;
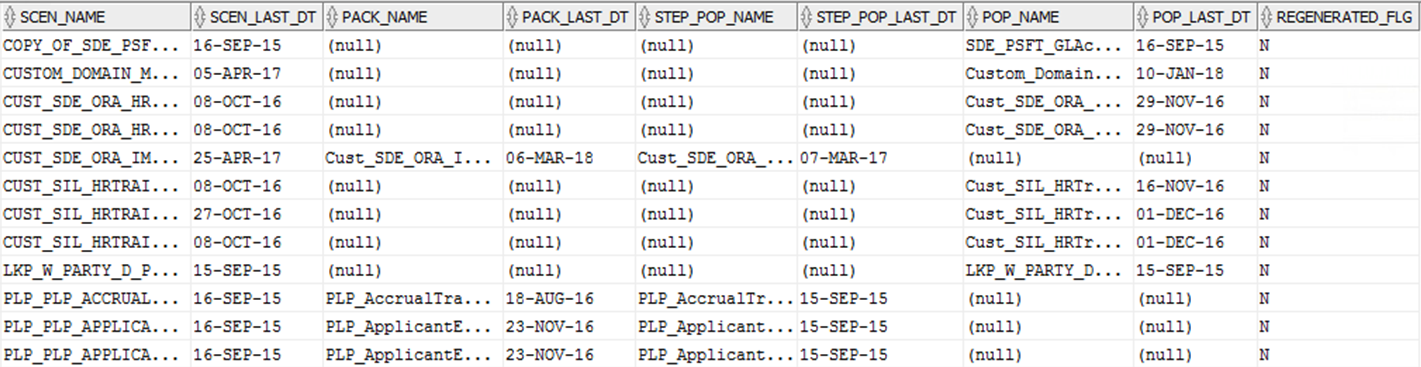
Sometimes it might be useful to confirm whether some scenarios have been regenerated after the corresponding packages/steps/interfaces (SNP_PACKAGE, SNP_STEP) have been modified. This can be achieved by comparing the last modification dates of the objects, as shown below:
select *
from (
select distinct
SCEN.SCEN_NAME, SCEN.LAST_DATE SCEN_LAST_DT,
PACK.PACK_NAME, PACK.LAST_DATE PACK_LAST_DT,
STPOP.POP_NAME STEP_POP_NAME, STPOP.LAST_DATE STEP_POP_LAST_DT,
POP.POP_NAME, POP.LAST_DATE POP_LAST_DT,
case when (
SCEN.LAST_DATE > coalesce(PACK.LAST_DATE, to_date('20000101','yyyymmdd')) and
SCEN.LAST_DATE > coalesce(STPOP.LAST_DATE, to_date('20000101','yyyymmdd')) and
SCEN.LAST_DATE > coalesce(POP.LAST_DATE, to_date('20000101','yyyymmdd'))
) then 'Y' else 'N' end REGENERATED_FLG
from SNP_SCEN SCEN
left outer join SNP_PACKAGE PACK on SCEN.I_PACKAGE = PACK.I_PACKAGE
left outer join SNP_STEP STEP on PACK.I_PACKAGE = STEP.I_PACKAGE
left outer join SNP_POP STPOP on STEP.I_POP = STPOP.I_POP
left outer join SNP_POP POP on SCEN.I_POP = POP.I_POP
where 1=1
and (STEP.I_POP is not null or SCEN.I_POP is not null)
)
where 1=1
and REGENERATED_FLG = 'N'
order by SCEN_NAME, PACK_NAME, STEP_POP_NAME, POP_NAME;
Conclusion
Even if the ODI repository schema is not intended to be queried that way, knowing some of these queries and relations becomes really helpful. There is no official documentation about the ODI metadata model, so building the queries requires some effort and time, but if we have a library of useful queries, we can easily adapt them to any situation of ETL development and administration. It allows us to have a better understanding of the ODI repository components, look for configuration consistencies across similar elements, and even perform major updates on different sets of objects with just a couple of queries.
At the end, direct queries to the ODI Repository metadata helps us be more efficient when dealing with a lot of ODI components and have a more consistent ETL solution.
Stay tuned to our blog, as we might be posting more useful ODI tricks, or other BI related topics!