
09 Aug 2017 Real Time Business Intelligence with Oracle Technologies
Introduction
In our previous blog article we discussed the necessity of real time solutions for Business Intelligence (BI) platforms and presented a user case with Microsoft Technologies (namely Azure and Power BI). In this case, we are analysing the same scenario, but we instead propose a design using Oracle Cloud and Oracle On Premise technologies.
We recommend going through the previous blog article to understand completely the scenario under analysis and its requirements.
1. Oracle Technologies for Real Time BI
Oracle offers both in cloud and on-premises solutions, focusing on Big Data. These solutions can be used for a variety of Big Data applications, including real-time streaming analytics.
1.1. Oracle Cloud Services
From all the services offered on Oracle Cloud, the following suit the needs of a real-time BI application:
| • | Oracle Event Hub Service. This service provides a managed Apache Kafka cluster, where we can easily assign resources and create topics using the web interface. |
| • | Oracle Big Data Compute Edition Service (OBDCE). This service provides a managed Big Data cluster with most of the Apache Hadoop/Spark stack elements, where the resource management and execution of tasks is also managed from the web interface. |
Both the Event Hub and the OBDCE services are part of the PaaS offerings of Oracle Cloud, which means that the whole hardware and software infrastructure behind them is managed by Oracle. The key benefit is that, even though we are using standard open source technologies, we don’t have to worry about resource provisioning, software updates, connectivity, etc. With this, the developers can focus on building the solutions, without losing time on administrative tasks. Another important point is that the connectivity between services on the cloud can be configured very easily using the web console, which ensures a reliable and safe path for the data.
1.2. On Premise Technologies
In addition to the cloud solution, a similar environment can be built on premises. For this we are using the Oracle Big Data Appliance. The Big Data Appliance consists, generally speaking, of the following components:
| • | Hardware: Several server nodes and other accessory elements for networking, power, etc. The configuration can be a starter rack with 6 nodes to a full rack with 18 nodes. Multi-rack configurations allow for an even larger number of nodes. |
| • | Software: All the components of the Cloudera Distribution for Hadoop (CDH) and additional components from Oracle like Oracle Database, Oracle NoSQL Database, Oracle Spatial and Graph, Oracle R Enterprise, Oracle Connectors, etc. |
For the purpose of our Real Time project, the required components are Kafka and Spark, as we will see later. Both are part of CDH and key elements of the standard open source real-time analytics scenario. In this case, all the components will be available in the same cluster. It is also important to know that, for demo projects like this, Oracle offers a Big Data Lite virtual machine, that contains most of the components of the Big Data Appliance. c. Real-Time Visualization At the time of writing this article, there is no BI tool from Oracle (OBIEE, DV) that allows visualization of real-time data. To tackle this, we decided to build a custom front-end that could be used both as a standalone web application or as one integrated into OBIEE. The key technologies we are using for this purpose are:
| • | Flask, which is a lightweight web framework for Python. |
| • | SocketIO, which is a framework based on WebSockets for real-time web applications using asynchronous communication. |
| • | ChartJS, which is a JavaScript library for building charts. |
2. Solution Design and Development
The architectural design for the solutions is shown in the figure below and explained throughout the rest of this section:
 |
Figure 1: Realtime BI solution design diagram, using both cloud and on premise Oracle technologies |
2.1. On Premise Source System
The on-premises source system part of the solution simulates a real-time operational system using a public data feed provided by Network Rail. The data from the feed is processed and inserted into a PostgreSQL database. An event monitor script listens for notifications sent from the database and forwards them to the real-time processing queue (Kafka), either located on Oracle Cloud or on the Oracle Big Data Appliance. For more details on this part of the solution, please, refer to the previous article using Microsoft Technologies. The design is exactly the same in this case, except that, in this solution, the Event Monitor sends the events to a Kafka queue (cloud or on premises), instead of sending them to an Azure Event Hub.
2.2. Oracle Cloud and Oracle Big Data Appliance
As explained in previous sections and shown in the diagram above, the Oracle solution for real-time stream processing can be developed both in the Oracle Cloud and using the Oracle Big Data Appliance. Both solutions are similar, as the underlying technologies are Kafka for event queueing and Spark Streaming for event processing. Apache Kafka is a message queueing system where Producers and Consumers can send and receive messages from the different queues, respectively. Each queue is called Topic, and there can be many of them per Kafka Broker (or node). The Topics can be optionally split into Partitions, which means that the messages will be distributed among them. Kafka uses Zookeper for configuration and managing tasks. In our scenario, we are using a simple configuration with just a single Kafka Broker, three Topics, each of them with a single partition. The process works as follows:
| • | The Event Monitor sends the events received from the database to Topic 1. |
| • | Spark Streaming consumes the messages from Topic 1, processes them and sends the results to Topics 2 and 3. |
| • | In the Flask Web Server a couple of Kafka Consumers are listening to Topics 2 and 3, and forwarding them to the web application. |
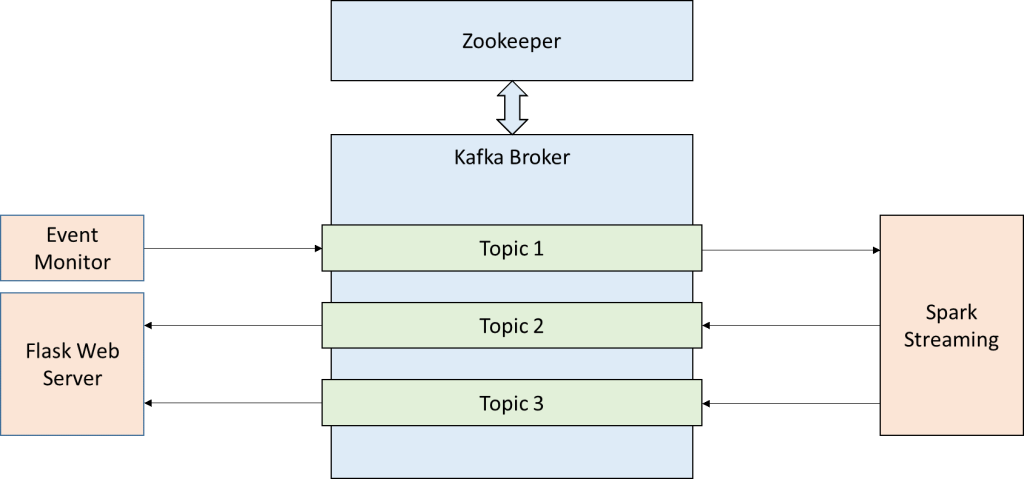 |
Figure 2: Interaction between main components of the solution and the different Kafka topics |
Spark Streaming is one of the multiple tools of the Apache Spark stack, built on top of the Spark Core. Basically, it converts a continuous stream of messages (called DStream) into a batched stream using a specific time window. Each batch is treated as a normal Spark RDD (Resilient Distributed Dataset), which is the basic unit of data in Spark. The Spark Core can apply most of the available operations to process this RDDs of the batched stream.
 |
Figure 3: Spark Streaming processing workflow |
In our scenario, Spark Streaming is being used to aggregate the input data and to calculate averages of the PPM metric by timestamp and by operator. The process to calculate these averages requires few operations, as shown in the Python code snippet below:
# Create Kafka consumer (using Spark Streaming API)
consumer = KafkaUtils.createDirectStream(streamingContext,
[topicIn],
{"metadata.broker.list": kafkaBroker})
# Create Kafka Producer (using Kafka for Python API)
producer = KafkaProducer(bootstrap_servers=brokers,
value_serializer=lambda v: json.dumps(v).encode('utf-8'))
# Consume the input topic
# Calculate average by timestamp
# Produce to the output topic
ppmAvg = consumer.map(lambda x: json.loads(x[1]))
.map(lambda x: (x[u'timestamp'], float(x[u'ppm']))
.reduceByKey(lambda a, b: (a+b)/2)\
.transform(lambda rdd: rdd.sortByKey())\
.foreachRDD(lambda rdd: sendkafka(producer, topicOut, rdd))
From this sample code, we can see that the RDD processing is similar to Spark Core, with operations such as map, reduceByKey and transform. The main difference in Spark Streaming is that we can use the foreachRDD operation, which executes the specified function for each of the processed batches. It is also important to know that, at the time of writing this article, the Spark Streaming API in Python does not offer the option to create a Kafka Producer. Therefore, we are using the Kafka for Python library to create it and send the processed messages.
Together with the average by timestamp shown above, we are also generating an average by operator. As we have two sets of processed data, Spark needs to send the data to two separate Kafka Topics (2 and 3). One key problem with Spark Streaming is that it does not allow data processing in Event Time. This basically means that we can’t synchronize the windowing applied by Spark to create the batches to the timestamps of the source events. Therefore, as shown in the diagram below, this can lead to the events of different source timestamps being mixed in with the aggregates created by Spark.
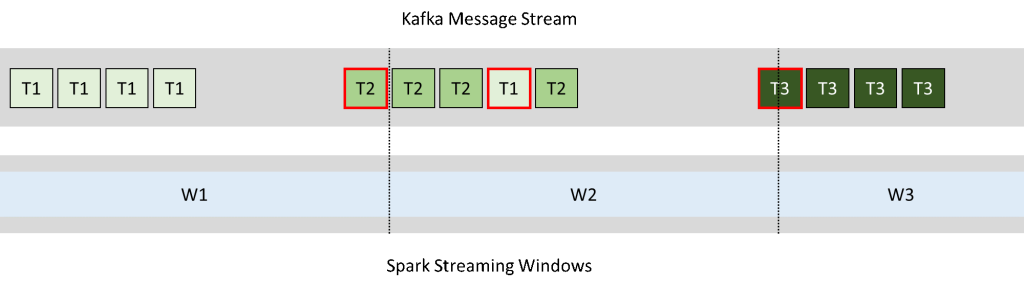 |
Figure 4: Misalignment between Kafka and Spark Streaming windows causes events to be processed inside the incorrect time window |
In fact, in our scenario, we have events that are timestamped in the source, but we were not able to align the Spark Streaming batching process to this time. There are some possible solutions for this issue, namely:
| • | Spark Streaming with Updates.This is a workaround, were we can tell Spark Streaming to update the results of a batch with data coming in a “future” processing window. We tested this approach but, unfortunately, it lead to compatibility errors with Kafka and we couldn’t go ahead with it. |
| • | Spark Structured Streaming.This is a separate tool of the stack built on top of Spark SQL, which is meant to solve the problem with Event Time processing. Unfortunately, at the time of writing this article, it is still only available in “alpha” version as part of Spark 2.X. Again, we were able to test this experimental feature but couldn’t get it to properly work with Kafka. |
| • | Other streaming processing tools.There are other existing tools in the Big Data ecosystem that can work with Event Time. Kafka itself has a Streams API that can be used for simple data processing. There is also Storm and others. |
2.3. On Premise BI System
As introduced earlier, Oracle standard BI solutions don’t offer the possibility to connect to real-time sources. Therefore, we decided to build our own custom platform and integrate it with OBIEE. The key component of this part of the solution is the real-time messaging between the web server and the browser provided by SocketIO. In this library, the client requests the server to start a session. If the server accepts, a continuous stream of bidirectional messages is opened (in our case the messages are unidirectional, from the server to the client). Both the client and the server react to the received messages. Finally, either the client or the server can close the connection (in our system the client closes the connection when the browser is closed).
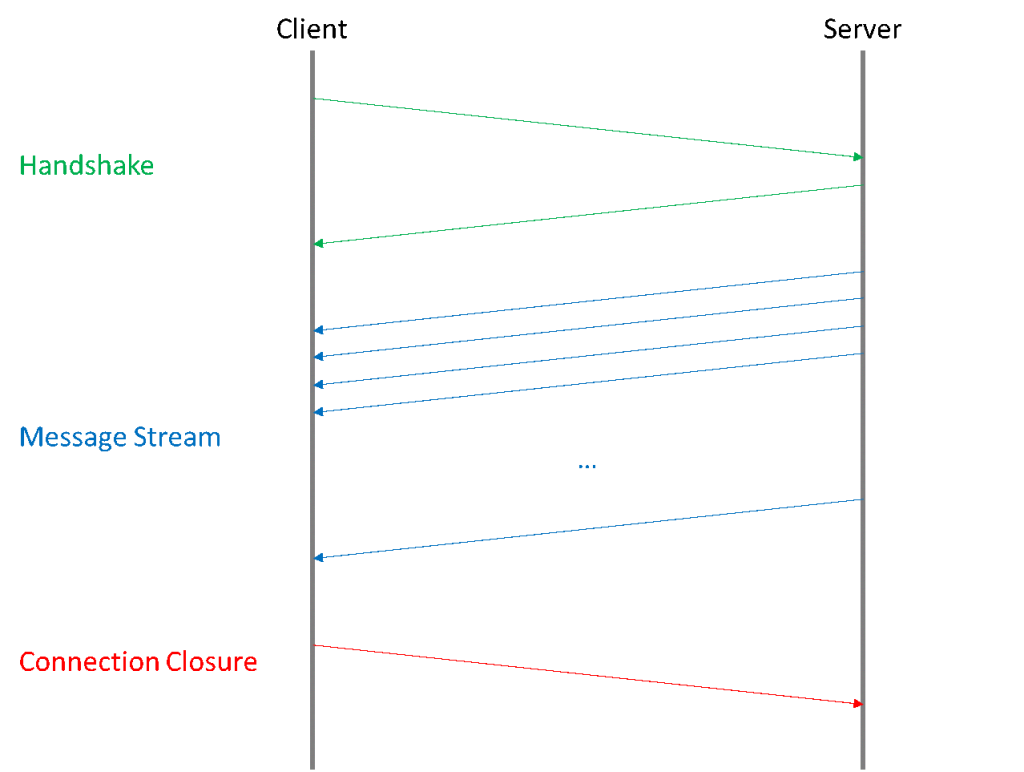 |
Figure 5: Continuous bidirectional communication channel using SocketIO |
Although the message channel is bidirectional, only the server is sending messages to the clients. What it does is consume the events coming from the Kafka Topics populated by Spark Streaming and forwards them, with a slight manipulation, to a SocketIO namespace using two different named channels.
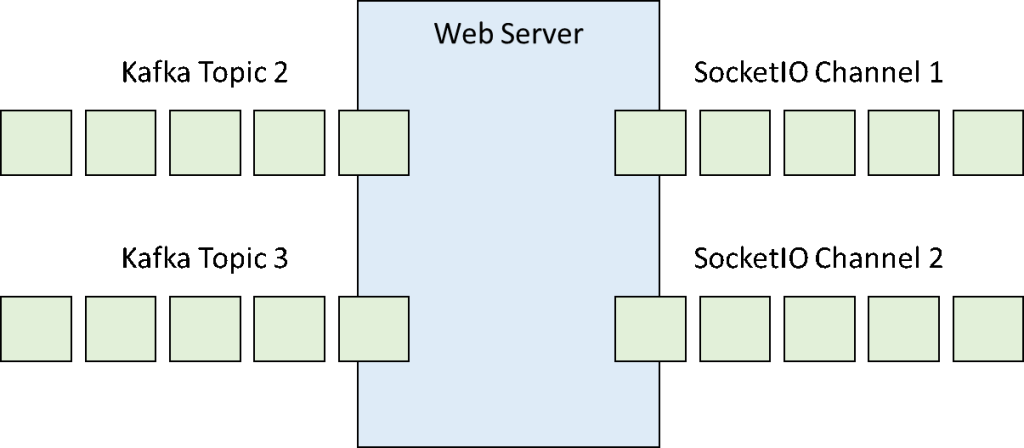 |
Figure 6: The web server sends the messages received from the Kafka topics to the SocketIO channels |
# Create a SocketIO object using the Flask-SocketIO add-in for Flask
socketio = SocketIO(app, async_mode=async_mode)
# Create a Kafka Consumer using PyKafka
client = KafkaClient(hosts=kafka_host, zookeeper_hosts=zookeeper_host)
topic = client.topics[kafka_topic]
consumer = topic.get_simple_consumer(consumer_group=kafka_consumer_group,
auto_offset_reset=OffsetType.LATEST,
auto_commit_enable=True,
auto_commit_interval_ms=1000,
auto_start=False)
# Start the Consumer, monitor the input
# and send the received data through the SocketIO channel
consumer.start()
while True:
socketio.sleep(0.1)
message = consumer.consume(block=False)
if message is not None:
data = json.loads(message.value.decode('utf-8'))
socketio.emit(channel,
{'key': data[0], 'value': data[1]}, namespace=namespace)
On the client side we have two possibilities to display the data, a standalone website served by the same web server or a set of custom analysis developed in OBIEE. In both cases, the key elements are the SocketIO and ChartJS JavaScript libraries. The first one establishes the connection with the server and the second one is used to create the charts. The SocketIO object is configured so that anytime it receives a message from any of the channels, it will update the data of the chart and ask ChartJS to refresh it accordingly. The required code in Javascript is shown in the following snippet:
# Create the socket using the JavaScript SocketIO client library
socket = io(location.protocol + '//'
+ document.domain + ':'
+ location.port
+ namespace);
# Create an event listener for the “realtime_data01” channel
# and update the corresponding charts
socket.on('realtime_data01', function(msg) {
if (lineChart.data.labels.length > 20) {
lineChart.data.labels.shift();
lineChart.data.datasets[0].data.shift();
}
lineChart.data.labels.push(msg.key);
lineChart.data.datasets[0].data.push(msg.value);
lineChart.update();
});
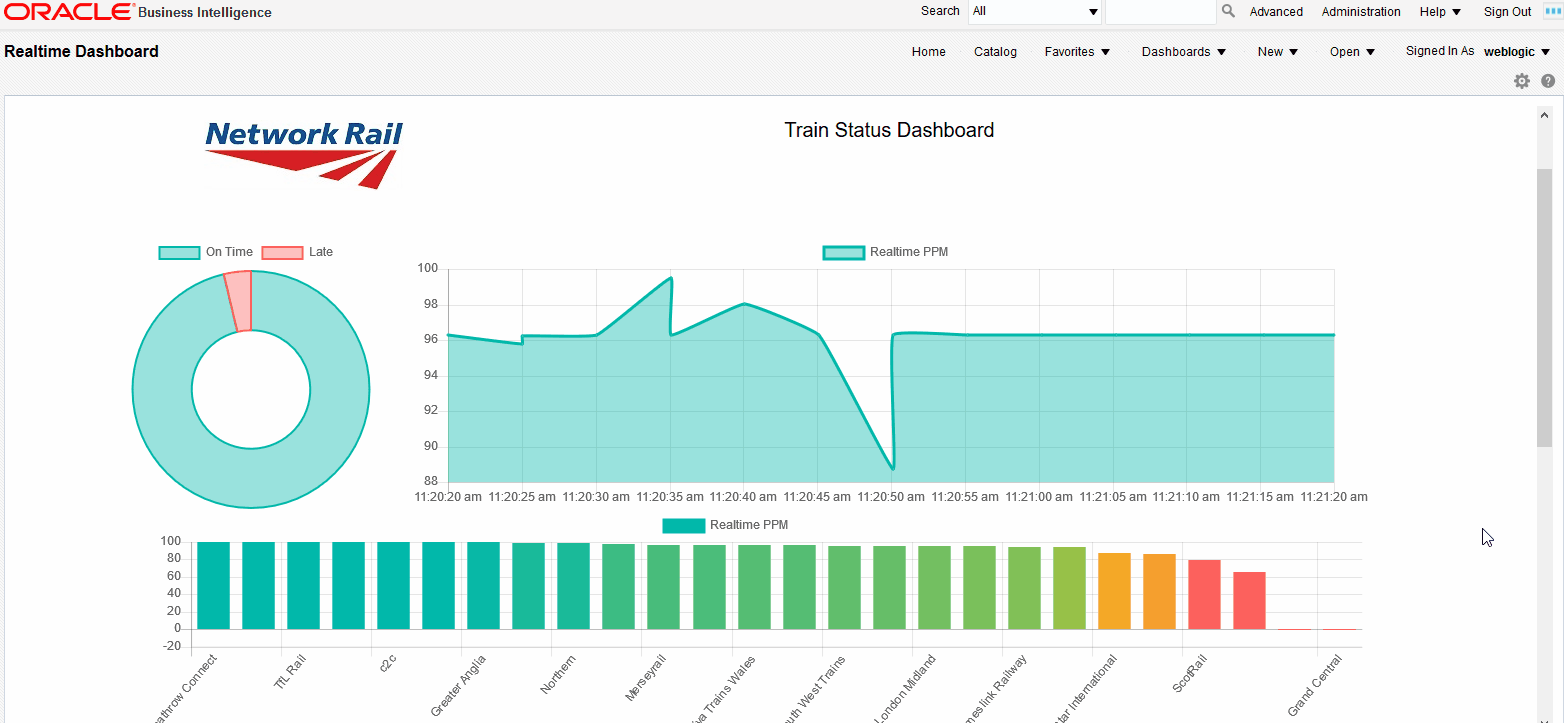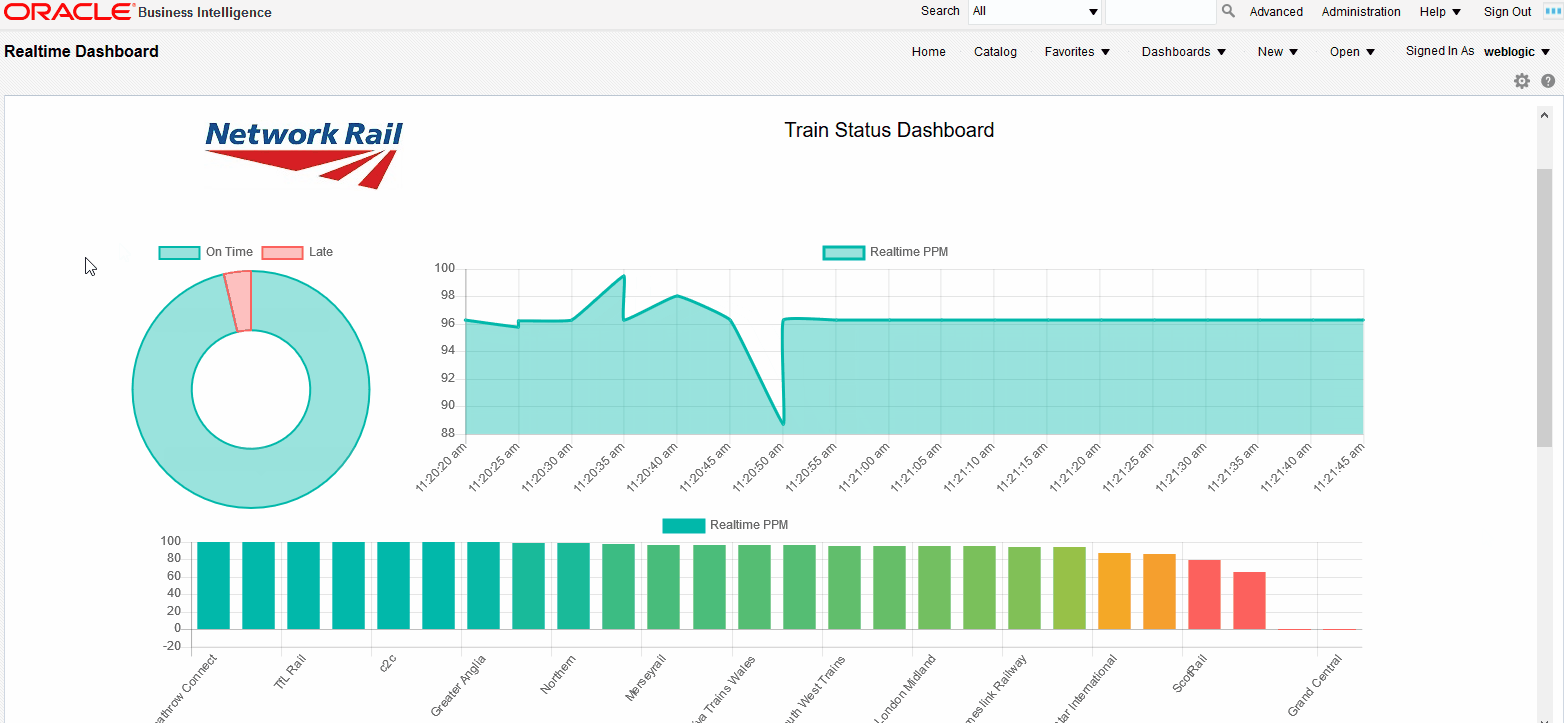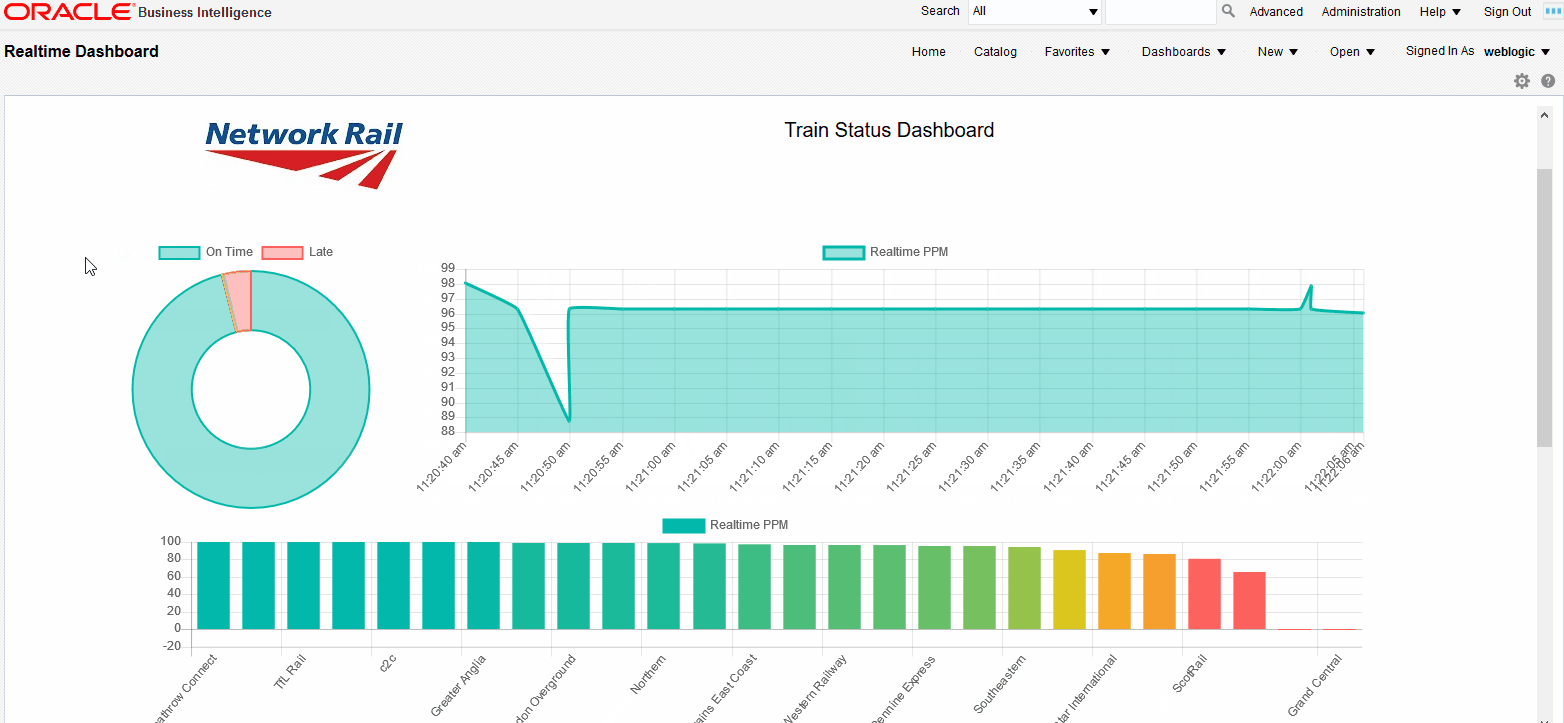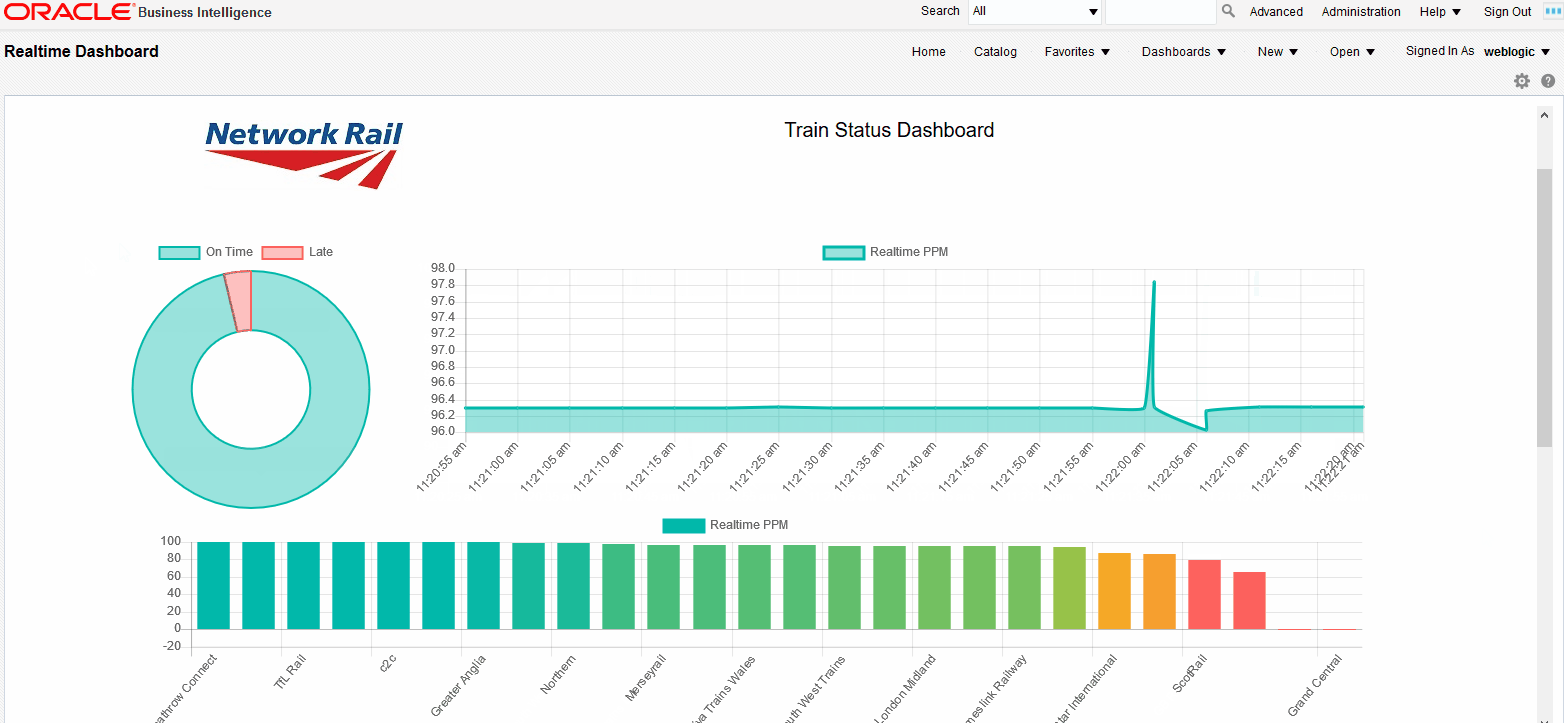
Here, we are asking the socket object to update the values of the lineChart object, shift the values if required and update the chart when a new message is received in the realtime_data01 channel. The result will be a set of charts updating automatically as soon as the new data is sent through the socket:
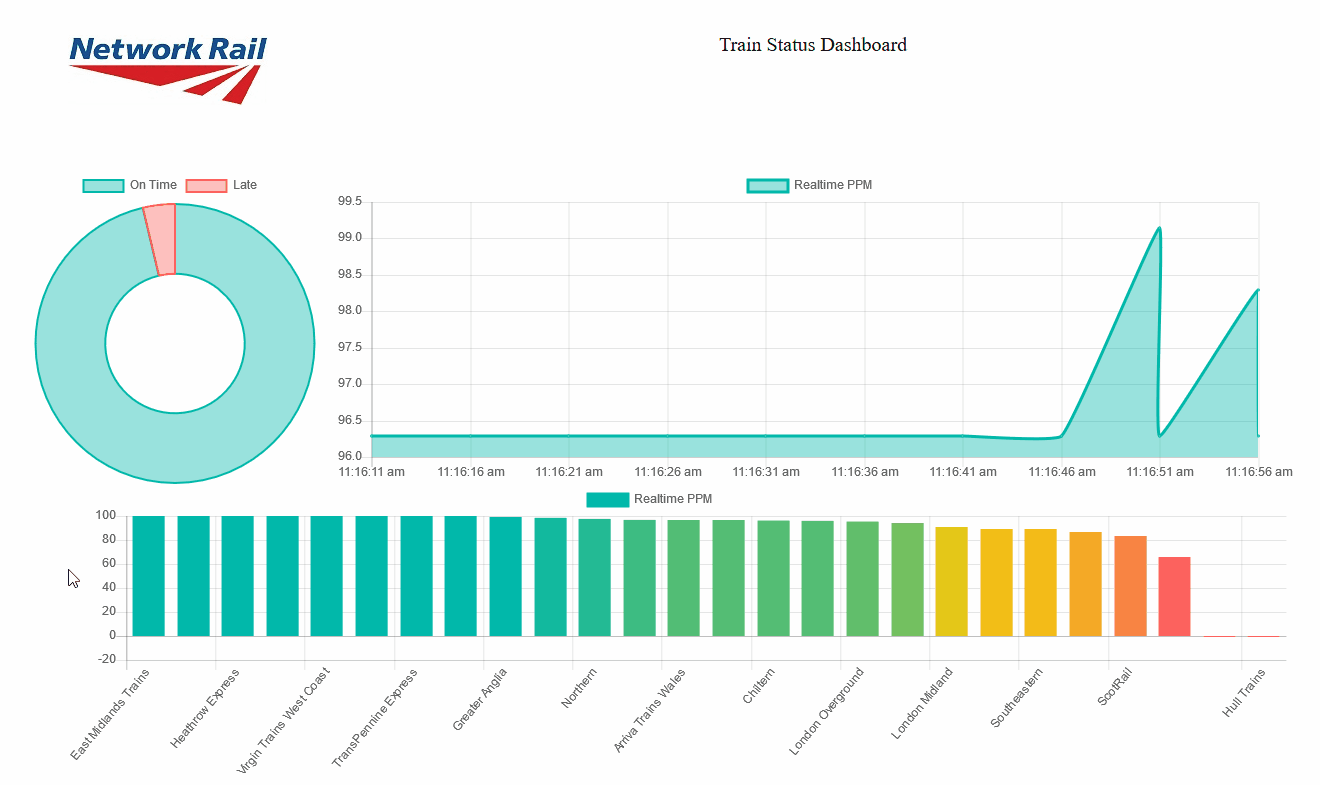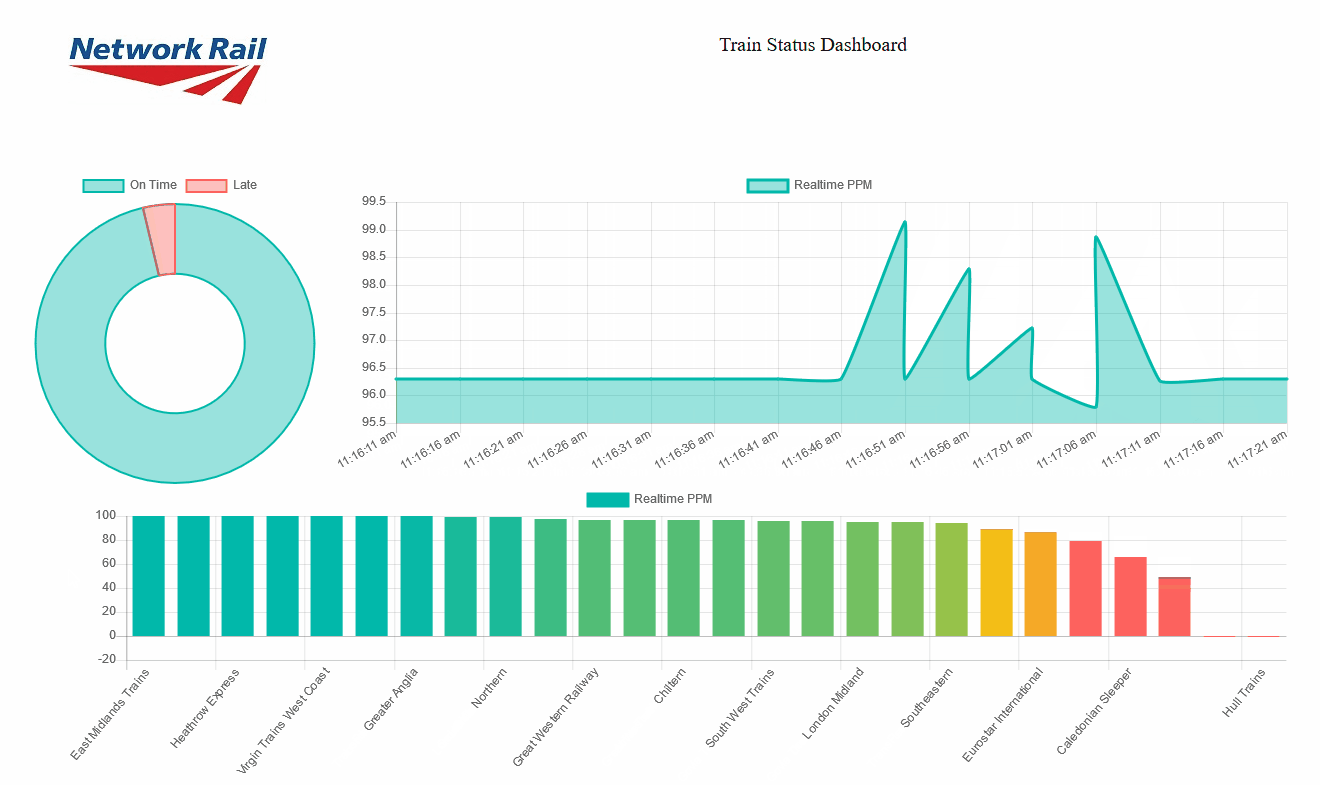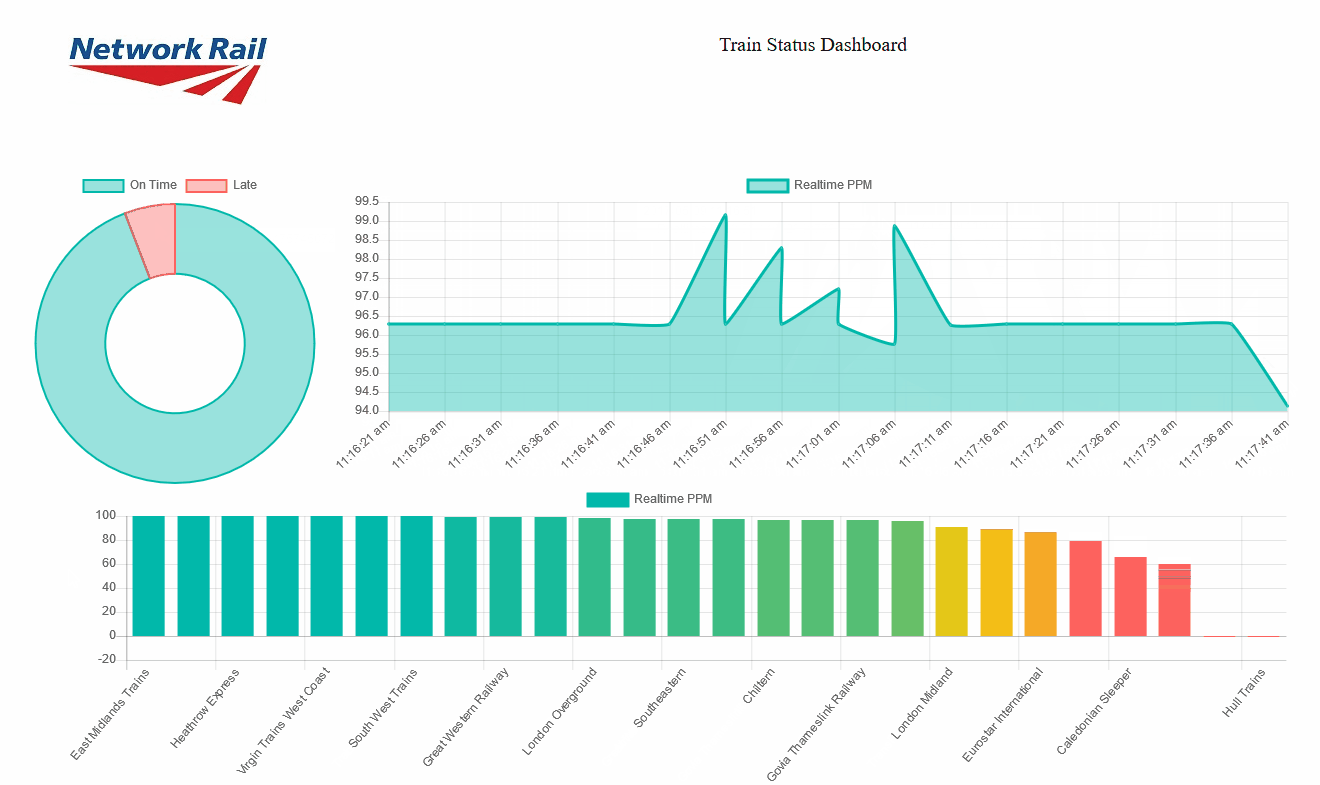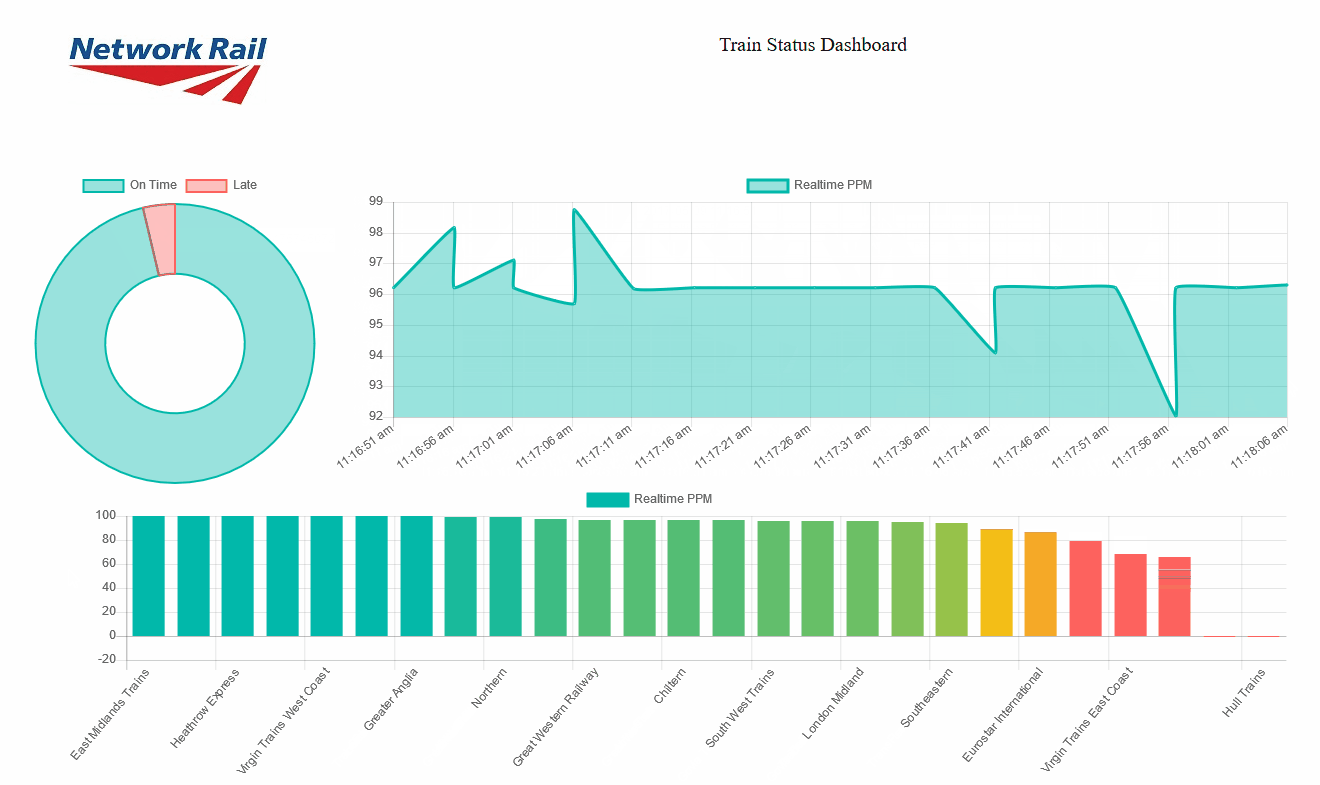 |
Figure 7: Streaming tiles showing real time data coming from Stream Analytics |
Moreover, using dummy analysis with static text visualizations, we can embed the HTML and JavaScript into a normal OBIEE dashboard. In the example below, we can see exactly the same visualisations as in the standalone web. However, we will always be able to combine these real time visualisations with normal RPD-based OBIEE analyses.
Figure 8: Real-time visualizations embedded into an OBIEE dashboard |
3. Scenario Analysis and Conclusions
Based on our experience developing this solution with Oracle technologies for Real Time BI scenario, we have identified the following benefits, as well as areas for future improvement:
Advantageous features:
| • | Oracle solutions for Big Data are available both in the Cloud and On Premise, suiting perfectly to different companies and scenarios. |
| • | The Oracle Big Data stack is based on open source standard software, which makes it really easy to develop solutions and to find guidance. |
| • | Kafka topics are really easy to create and configure in a matter of minutes. |
| • | Spark Streaming leverages all the processing power of Spark to real time streams, thus allowing for very sophisticated analytics in a few lines of code. |
| • | SocketIO allows creating bidirectional channels between web servers and applications and suits very well the needs of a real time application. |
| • | The web based front end is very flexible as it can be served standalone or integrated into other tools as OBIEE. |
Areas for improvement:
| • | The Oracle Big Data stack comes with a plethora of components pre-installed, which can be unnecessary in many applications. |
| • | Spark Streaming windowing is not ready yet for event time processing, which makes it flawed for some real-time applications. Other solutions from the Spark stack are still not yet completely ready for production environments. |
| • | Oracle standard BI solutions do not offer real-time visualisation solutions. |
Click here if you would like to receive more information about the Real Time BI Services we offer!
Authors: Iñigo Hernáez, Oscar Martinez