
30 Sep 2021 A Comparative Analysis of the Dask and Ray Libraries
Nowadays data analysis is one of the most important fields in the business world, full of enormous amounts of data to be analysed in order to extract conclusions and gain insights. As we are dealing with so much data, it is impossible to look at it manually, so analysis is commonly carried out with Machine Learning techniques.
The computational resources available are main bottleneck here, as we need large amounts of memory and lots of operations must be computed. Data analysis researchers are now focused on using computer resources in the most efficient way possible. The two libraries we are going to talk about, Dask and Ray, were developed to analyse huge datasets using clusters of machines more efficiently.
When working with data processing, Python is the most widely used language and lots of useful libraries were developed with it, such as NumPy, Pandas, and Matplot, among others. The main problem with these libraries is that they were implemented to be used with smaller datasets on a single machine. They are not optimised for large datasets and machine clusters, the most common working environment these days. This is where these new libraries come into their own, using all the functions implemented in Pandas, but optimised for larger datasets and greater computing resources.
1. Main Differences
As the resource optimisation problem is holding back research in AI, a lot of effort is being invested and many new libraries have come out. Two of the most popular are Dask and Ray, which have different use cases; but in the end their main point is the same, to change the way data is stored and how the Python code is run, so the use of resources is optimised.
Dask was implemented as a Pandas equivalent, with the difference that instead of having the dataset in a Pandas DataFrame, we will have a Dask DataFrame composed of a set of Pandas DataFrames. In this way, it will be easier to efficiently run code with a cluster of machines and exploit the parallel computation.
Ray, on the other hand, is more a tool for general purposes, not only for data processing. It wraps a Python function and with its own environment initialised, the function is run in a more efficient way. Ray is not an equivalent for any data processing library, so it can be used with other libraries such as Pandas or Dask. It takes all the resources available and parallelises as many tasks as possible, so all the cores are being used.
2. Data Wrangling Comparison
Applying data wrangling techniques to these libraries can be a bit different from using Pandas. As explained, the Dask library is a Pandas equivalent, so we can find all the most used functions from Pandas. The main difference in terms of code is that when calling a function, we must add .compute() at the end of the call to evaluate the function. In the case of Ray, we can either use it with Pandas or with Dask, among other options. As mentioned, Ray wraps Python code to run it efficiently, so if the code is meant to process data, it can contain Pandas or Dask functions.
To compare these two libraries, we tested them with two different datasets to see how they worked in each case, but neither of the datasets were large enough to appreciate an optimisation of these simple functions. We used a small dataset with 395 entries and 33 features with college student information, and a larger dataset with 385,704 entries and 18 features with air quality measurements from Beijing.
First, we compared the runtimes of loading the dataset from the CSV file to the DataFrame:
Students Dataset | Air Quality Dataset | |
|---|---|---|
Pandas | 0.007536 s | 0.189201 s |
Dask | 0.0098337 s | 0.592946 s |
With this first test we also saw that for the Students Dataset (395 entries) just one DataFrame was created for both libraries, but in the case of the Air Quality Dataset (385,704 entries) the Dask DataFrame was composed of 11 Pandas DataFrames. Ray was not used in this step as it does not have its own data storage format.
Then we computed the mean value of one of the features:
Students Dataset | Air Quality Dataset | |
|---|---|---|
Pandas | 0.000770 s | 0.001774 s |
Dask | 0.044706 s | 0.675001 s |
Ray [Pandas] | 0.044782 s | 0.010370 s |
Ray [Dask] | 0.012071 s | 0.010577 s |
Another test was to delete duplicate entries, due to the greater computational complexity:
Students Dataset | Air Quality Dataset | |
|---|---|---|
Pandas | 0.014652 s | 0.434019 s |
Dask | 0.103000 s | 0.891984 s |
Ray [Pandas] | 0.024222 s | 0.650240 s |
Ray [Dask] | 0.027408 s | 0.016287 s |
With these tests we can see that these libraries can be useful when facing computing resource problems, but they can be counterproductive when raw Pandas can work perfectly well. We can also see that the benefits depend on the complexity of the function.
3. Machine Learning Comparison
As we said before, Data Analysis is currently one of the most important fields in the business world as large datasets are stored and they must be processed by a computer. The information extraction from large datasets is typically done with Machine Learning techniques, so the computer can reach conclusions from the given data by finding patterns in it. This has a very high computational cost, so this is where these libraries are more relevant.
In terms of Machine Learning techniques, we usually divide the task into 2 or 3 steps: the training, the validation (which is optional), and the test. As you can imagine, the training step has the higher computational cost, so we should focus on optimising these computations.
There are many Python libraries to work with Machine Learning, but the most common is Scikit-Learn. This library does not replace Pandas or Dask tasks, but instead uses the created DataFrames to build the model. Nevertheless, there will be a difference between a Pandas DataFrame and a Dask DataFrame, as with Dask the data is partitioned and it will be easier to parallelise processes with a cluster of machines.
Most of the Machine Learning libraries are designed to work on in-memory arrays, so there are problems when working with large datasets that do not fit into our available memory. Dask has implemented an extension called Dask-ML where we can find almost all the functions needed for ML tasks ready to work with machine clusters.
With data wrangling we saw that these libraries may not be useful unless we are working with huge datasets, as the computational cost of the functions is not that high. To see how these libraries work with functions with a higher computational cost, we fitted a clustering model with a randomly generated dataset with different numbers of entries: 100,000, 1,000,000, 10,000,000 and 100,000,000 entries.
100,000 | 1,000,000 | 10,000,000 | 100,000,000 | |
|---|---|---|---|---|
Scikit-Learn | 0.359504 s | 3.916643 s | 43.334999 s | 502.258518 s |
Dask-ML | 0.550719 s | 3.396780 s | 37.125517 s | 428.510227 s |
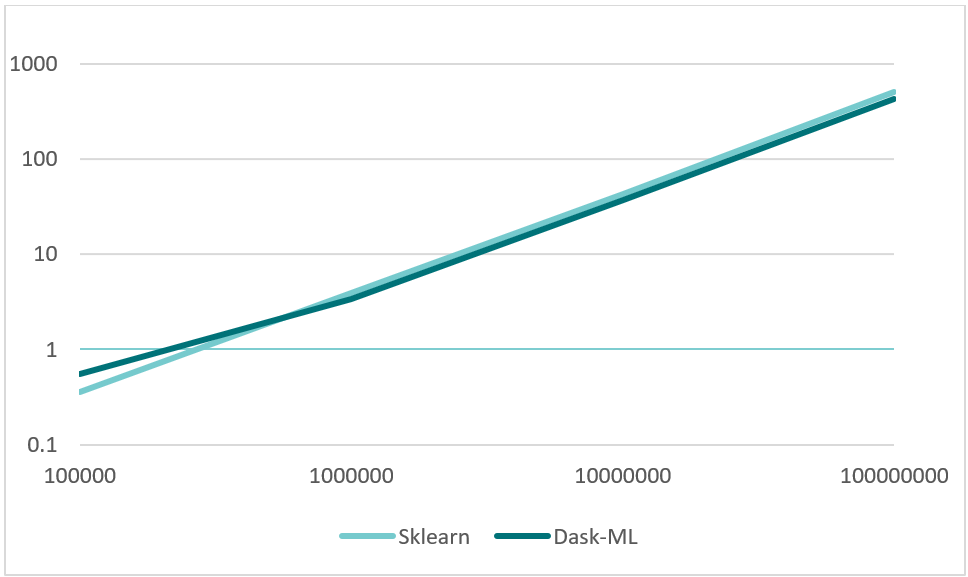
In this line plot we can see the benefits of using Dask when working with large datasets, and how it is of little help when we are not facing memory issues. We can see that the runtime improvement is logarithmic, so we can notice bigger improvements when working with larger datasets.
Conclusion
After our research, we found that these new libraries can be very useful when dealing with very large datasets or with tasks that require lots of computing resources. These libraries have been implemented to be easy to use for Pandas-friendly users, so you do not have to learn a whole new library from scratch.
What we must bear in mind is that these libraries should not be used unless they are needed, as they add some difficulty to the coding; and if we are working with small datasets, it would be overkill. As we saw with our tests, if we do not have any problems while running the code, we should keep using raw Pandas as it is the most efficient way to go.
Here at ClearPeaks, our team of specialists are always testing new developments and looking for solutions to your advanced analytics needs, so don’t hesitate to get in touch with us if there’s anything you think we can help you with!
