14 Oct 2021 Enhancing an AWS Data Platform with Airflow and Containers
Amazon Web Services (AWS) is the market-leading on-demand public cloud computing provider, getting more and more popular year after year. AWS improves its services regularly and creates new ones every other month to tackle all sorts of workloads, so it’s hardly surprising that many companies, including a few of our customers, want to migrate their data platforms to AWS.
At ClearPeaks, we are experts on data platforms leveraging big data and cloud technologies, and we have a large team working on various AWS projects. And yes, it is true that this platform and its services offer a lot of possibilities, but sometimes it is easy to get lost among so many services to choose from.
In previous blog entries we have already offered some help in this regard, since in our previous entries we discussed how to build a batch big data analytics platform on AWS and also how to build a real-time analytics platform on AWS, in both cases using Snowflake as the data warehouse. In this blog article we are going one step further, to fill a couple of gaps that have traditionally existed on AWS data platforms, and that will, for sure, be of interest to anyone attempting to design a modern and capability-rich AWS data platform.
The first gap is in data ingestion: AWS has a plethora of services for doing all sorts of things with data already in AWS, but what options are there to bring data from outside ? As we will discuss below, there are services in AWS for bringing data from common types of sources, such as RDBMS, into AWS. But what happens when we are dealing with an uncommon source?
The second gap is orchestration: what options do we have if we need a tool or mechanism to allow us to schedule the execution of cross-service data pipelines in an organized and simple way?
Filling the Gaps
Regarding data ingestion for uncommon data sources, in AWS we can do it in different ways as we will discuss below, but in this blog we will explore and demonstrate a solution using Python code encapsuled in Docker, which pretty much allows us to do whatever we want for as long as we need and as often as we need.
Regarding orchestration, since our team is very active in AWS and we are in constant collaboration with their engineers, we were one of the first teams to test a new service in AWS that specifically aims to fill this gap, Managed Workflows by Apache Airflow (MWAA). This new service gives us the possibility to use Airflow in AWS without the need to manage the underlying infrastructure.
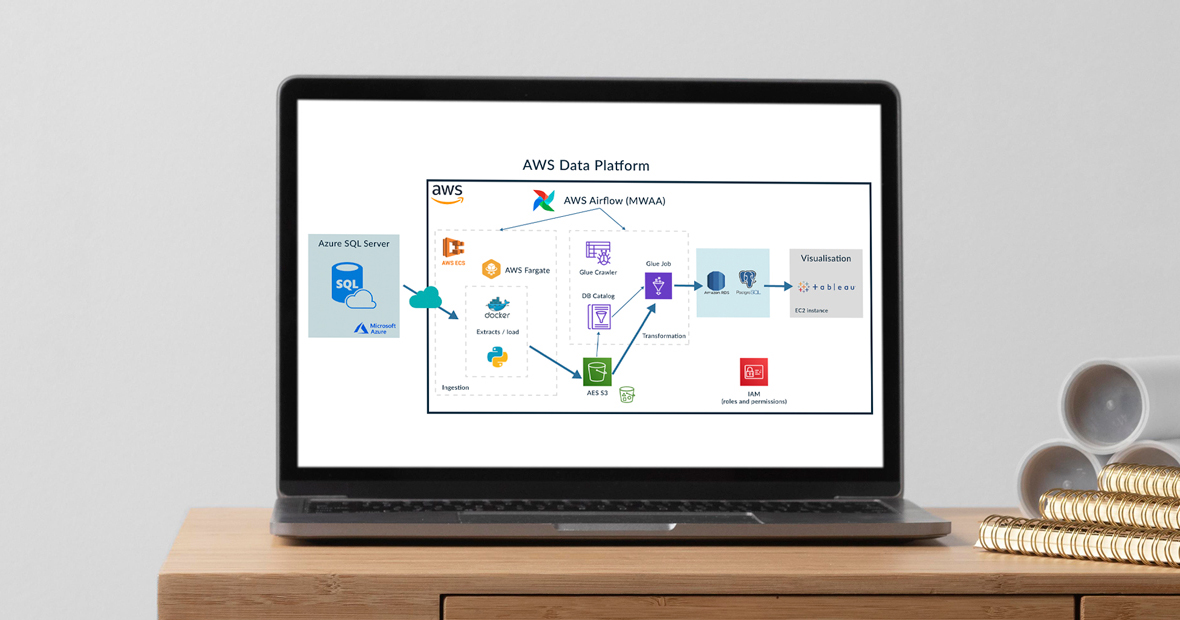
To illustrate the proposed solutions, we have built the platform shown below to address a simple use case:
In this example, we are using Python and Docker to read data from an RDBMS into S3, make a simple transformation with Glue, store the transformed data in a PostgreSQL RDS and visualize it with Tableau; the ingestion and transformation steps are orchestrated by Airflow.
We are aware that an RDBMS is anything but uncommon! But bear with us since we just want to illustrate a simple example of building and using a custom connector to read from any type of source. For the sake of simplicity, we chose an RDBMS, but to make it a bit more challenging it’s from Azure; please note that you could use the same approach (of course with different Python code) for any other type of source.
Ingestion
As we have already noted, in some contexts where the data source is not traditional, connectors are not provided by AWS; so we may encounter some limitations when it comes to extracting and ingesting data from these sources. To overcome this limitation, leveraging a Docker container running Python code, we can connect to any type of data source by writing our own code and using the required set of libraries.
In our scenario, the Python code uses the “pyodbc” library to connect to the source database. In addition, we rely on the common “boto3” library (AWS SDK for Python) to manage AWS services. In our scenario, boto3 is used to store the extracted data in S3. Obviously, this code can be easily modified to connect to another type of database.
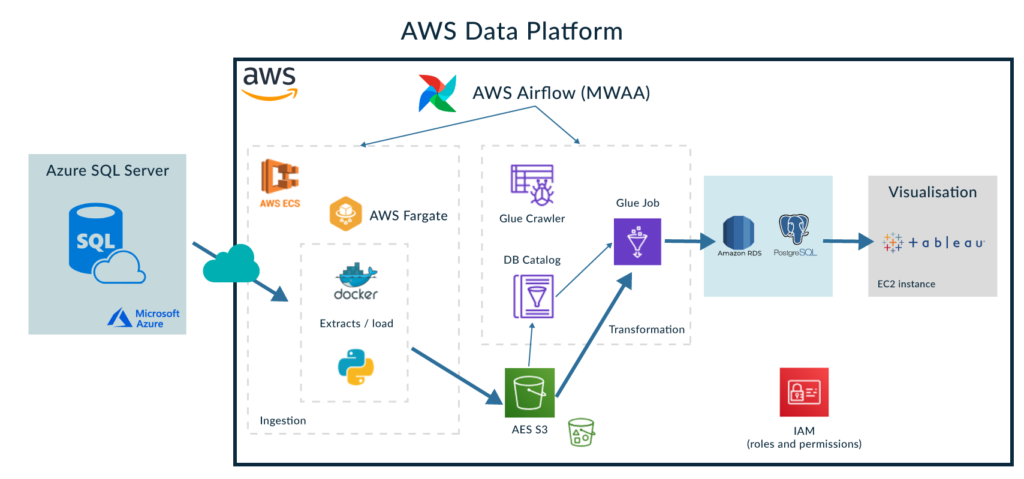
At the risk of explaining something you already know, we must emphasize that the development of the Python code and the creation of the Docker image is done in a local development environment running Ubuntu, where local tests can be executed.
Our next step will be the preparation of the Dockerfile (the document that specifies the dependencies in order to execute the Python code correctly). Once both files are ready, the creation of the Docker image can be done by running a “docker build” command in our local development environment. AWS provides a repository service for containers, AWS ECR, where we are going to push the created docker image. See the image below for more details:
AWS proposes several ways to run docker containers. Our approach uses AWS Fargate, which is a serverless compute engine for containers. We could have deployed the docker image in an EC2 instance, but as the ingestion process is only going to run once per day, AWS Fargate will cost less, and will also take care of the provision and management of the underlying servers.
We have chosen AWS ECS as the orchestration engine for the containers, which integrates well with Fargate and our use case (a single execution per day). We also tried AWS EKS, but it didn’t fit our scenario as it tries to keep the service up and available at all times, which was not a requirement for our use case.
If you want more information about how ECS and Fargate work together (and what the differences are) we recommend this blog article.
Orchestration
Before the release of AWS MWAA, there were two approaches to orchestrate data pipelines in AWS: AWS Steps Functions, or using an event-based approach relying on AWS Lambda. Nevertheless, neither of these services met all the requirements expected of a data orchestration tool.
AWS MWAA is a managed service for Apache Airflow, which allows the deployment of the Airflow 2.0 version. AWS MWAA deploys and manages all aspects of an Apache Airflow cluster, including the scheduler, workers and web server. They are all highly available and can be scaled as necessary.
Regarding the sizing of the cluster, AWS MWAA only provides three flavours: small, medium, and large. By selecting one of the sizes, AWS dimensions all the components of the cluster accordingly, including DAG capacity, scheduler CPU, workers CPU, and webserver CPU. The cluster can also scale up to the maximum workers. For our use case, we chose the small one as we just need to schedule one pipeline.
The orchestration logic, i.e. the DAGs, developed in Python, are stored in S3 buckets; plugins and library requirement files are also synchronized with the Airflow cluster via S3.
The following image corresponds to the Airflow portal UI:
One of the downsides of AWS MWAA is the fact that once deployed, the cluster cannot be turned off or stopped, so the minimum monthly cost of a cluster will be around $250.
In our project, we have used the operators to interact with AWS ECS and Glue services. Operators are pre-defined tasks, written by providers (AWS, Google, Snowflake, etc.) and imported via libraries. Bear in mind that not all the tasks are available via operators, such as the execution of a Glue job. In this case, two other options are available: Hooks, which provides a high-level interface to the services, or we can use a Python operator and write the low-level code that connects to the API.
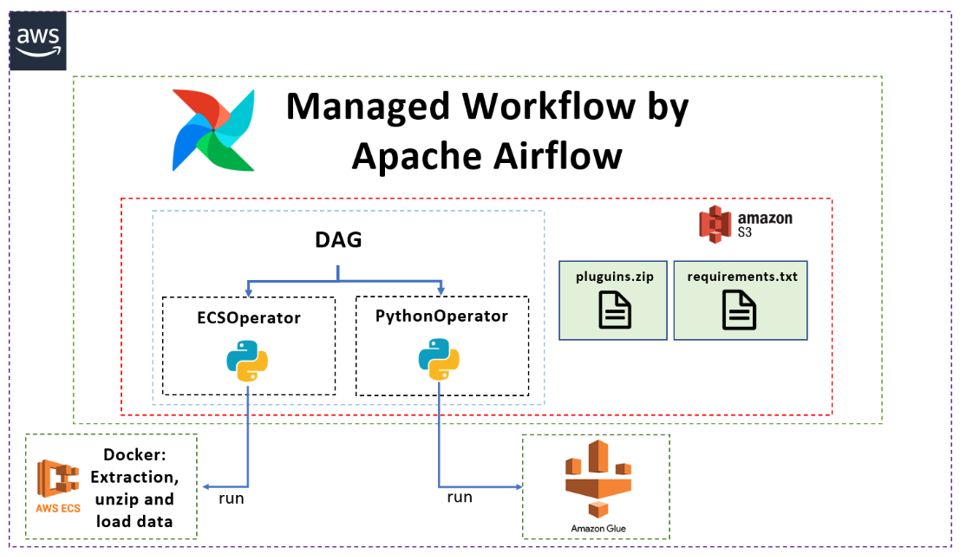
The following diagram represents the Airflow environment along with the files we developed and uploaded into S3 as part of our simple demonstration. Our DAG runs an ECSOperator and a PythonOperator. The ECSOperator controls the ECS service that runs the Docker container (on Fargate) that connects to the source (in this case the Azure DB) and loads the data into S3. The PythonOperator interacts with the Glue jobs via the API – it reads the data from S3 and loads it into the PostgreSQL RDS:
Conclusion
Now let’s go over everything we have learned in this blog post, highlighting the important parts.
Through a simple example, we have presented an approach to ingest data into AWS from any type of source by leveraging Python and containers (via AWS ECS and Fargate), and we have also seen how the AWS MWAA service can be positioned as the main orchestration service ahead of other options such as AWS Step Functions.
We hope this article has been of help and interest to you. Here at ClearPeaks, our consultants have a wide experience with AWS and cloud technologies, so don’t hesitate to contact us if you’d like to know more about what we can do for you.
