
05 Apr 2023 Using ChatGPT for Topic Modelling and Analysis of Customer Feedback
Given the recent explosion in popularity for Large Language Models (LLM), or AI models that have been trained on vast amounts of text and can perform various types of tasks involving natural language, there has been an uptick in companies looking for ways to leverage this technology. This has been especially the case with ChatGPT, OpenAI’s most popular LLM released to date, which opened access to its API just a few weeks ago.
In this article, we are going to use LLMs to analyse customer feedback in bulk, extracting insights and key complaints; and thus enabling the business to understand exactly what users are complaining about without having to read through all the individual feedback, which could consume too much time.
We’re going to be using real Amazon reviews from this Kaggle post to experiment with different methods of analysis. And we’ll also show you how our results compare with already existing solutions.
Current Solution
One approach to analysing free form reviews is topic modelling, the objective of which is to discover which topics are talked about in a block of text or documents, and then extract some kind of useful information from them.
For this scenario, a traditional topic modelling approach would go roughly as follows:
Clean the text from words like “the”, “and”, “is”, etc., that don’t convey any particular meaning, and then words like “good”, “bad”, “terrible”, etc. (basically, remove all words that indicate an obvious positive/negative sentiment).
From the remaining words, you can now check which ones have the most appearances in low score reviews. For example, if “battery” has a high correlation with low score reviews, this might be a hint that your product has battery problems.
The most common way to visualise this is by using a word cloud.
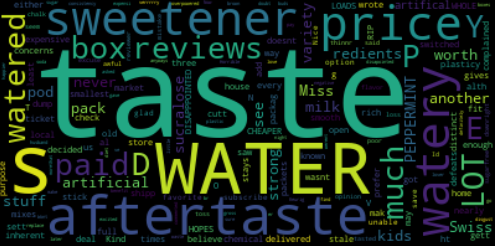
Here, we have a word cloud generated in this manner from 5 user reviews belonging to the previously described dataset. They correspond to a hot chocolate product for coffee machines (Product ID B005K4Q1VI). All three reviews have 2 stars or less out of 5.
From one look, we can guess what the main complaints are about. People don’t like the taste, it’s watered down, has a bad aftertaste, and/or they don’t like the sweetener used.
However, this technique has a few problems.
Firstly, the information they extract is limited to one word. So, if a concept has to be written with more than one word, or if it can be described with different words similar in meaning, there might be problems when trying to interpret the word cloud.
The term “taste” might be useful to indicate that there’s something wrong with the taste of the beverage, but it provides very little context as to what the actual problem is. Is it too bitter? Does it not taste like chocolate at all? Maybe it’s even described as a good thing – “bad taste” and “good taste” will both have the same impact on the diagram.
This requires someone with expert knowledge to step in and take a closer look, which entails having to read the reviews to get more context. And that is the one thing we are trying to avoid in the first place.
Secondly, there’s a good chance for false positives. If a key problem with the product is correlated to some other aspect, but that aspect is not a problem in itself, it might still show up in the results.
For example, if a phone’s battery gets so hot that the screen also starts to heat up, and enough reviewers mention this in their reviews; “screen” might appear as a keyword, even though there is nothing wrong with it.
There are other forms of topic modelling, like the use of transformer models to extract key topics from text. However, they have the same pitfalls – singular words and little context.
Given this, it becomes clear that there’s not only a need to understand context, but to also be able to extract more complex concepts from text when needed, rather than just singular keywords.
The best tools for this kind of work are precisely LLMs. Therefore, in this article, we are going to use the new ChatGPT API and other tools to try to solve these problems.
First, we are going to start with a topic modeling approach, telling ChatGPT to extract key complaints from user reviews, which we will aggregate in a way that is useful to the end user. Then we will try to emulate Few-Shot classification, telling ChatGPT it to classify user reviews into predefined complaint categories we provide.
Topic Modelling with ChatGPT
The prompt we will use this time goes as follows:
Given the following user review “REVIEW” extract the key complaints the user has, summarized into either 2 or 3 words for each key complaint. write it out as a python list.
The reason we ask it to write it out as a python list is to keep the format constant and make it easier to parse. It’s also important to ask this right at the end of the prompt, or ChatGPT tends to forget it from time to time.
We ask it to summarise key complaints into 2-3 words because ChatGPT has a tendency to elaborate too much on these types of tasks, so this keeps it short but not too short. (Although it sometimes ignores this part of the prompt!)
We run a script to execute this prompt for all negative reviews of the Amazon listing with product ID B000KV61FC, which corresponds to a dog toy that breaks very easily.
This process seems to work, ChatGPT returns all the complaints in a neat python list. But there is one problem, it often writes out the same problem in slightly different ways:
![]()
![]()
In review 16 it writes out the same thing as 12, “Not durable”, but the first letter is in upper case while the other one has it in lower case.
Similarly, the same complaint can be written twice but with different wording.

“Easy to destroy” and “Destroyed Easily” are essentially the same thing, but if we try to do a simple text comparison this would come out as separate complaints.
To solve this issue and be able to aggregate all the complaints, we’re going to employ sentence embeddings, and use their cosine similarity to decide if two complaints are the same. For this, we used Facebook’s LASER (Language-Agnostic SEntence Representations) toolkit.
Here we take a few test sentences and check which complaints have a cosine similarity superior to 0.8:
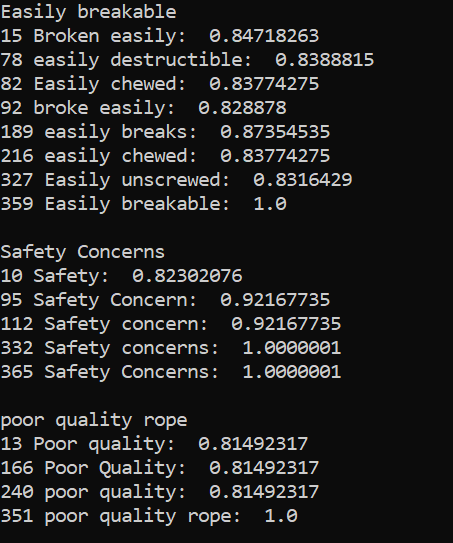
Looks pretty good!
There are a few flukes here and there (like ‘easily unscrewed’ being grouped in with ‘easily breakable’), however these are very much in the minority. Since the objective is to get a rough idea of what the problems are, and not exact numbers, this is more than good enough.
Now, we extend our Python script to include a section that “fuses” the labels with a high enough cosine similarity, and we should be done.
This is the resulting graph:
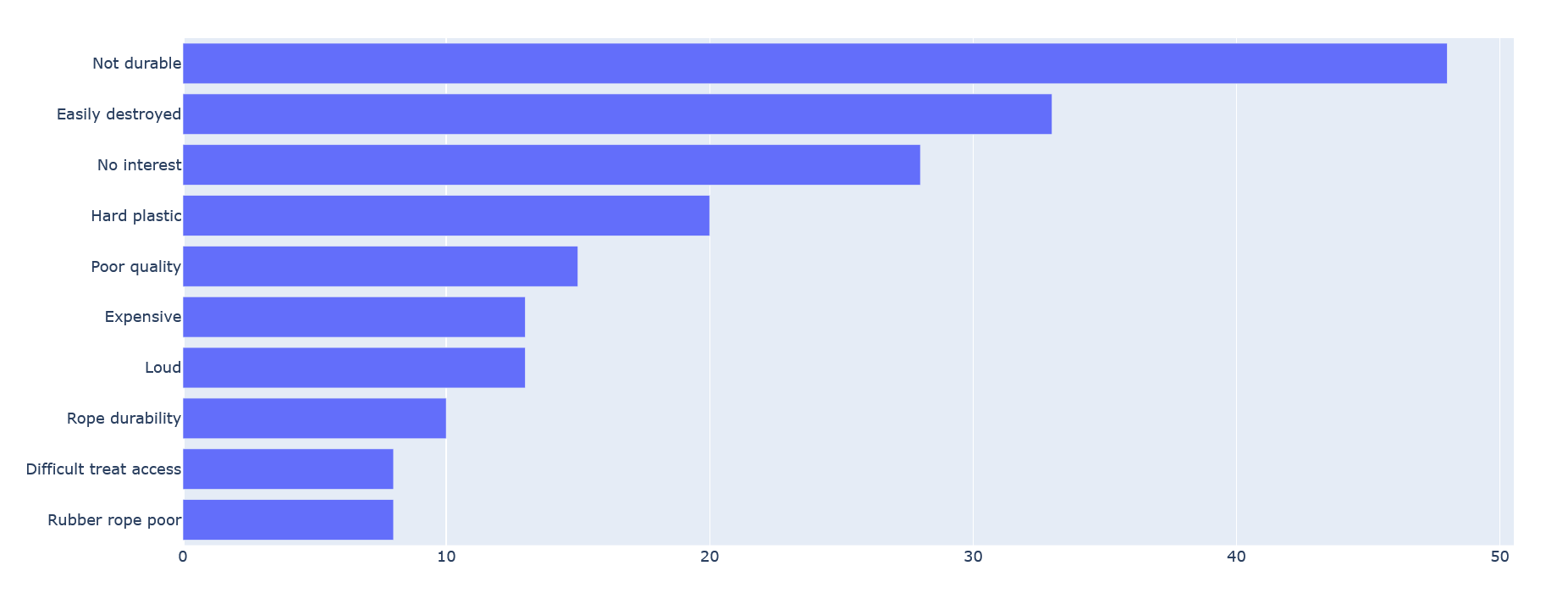
Metrics for topic modeling are notoriously hard to obtain, so testing for accuracy is difficult. However, we manually checked the reviews to see if the labels aligned with the contents of the text, and we believe they were pretty spot on. But this is as far as the testing can go without spending too much time on it.
One advantage of this method is that it allows for this kind of analysis to be done with complete blindness as to what the reviews are about, and can be easily replicated for any kind of feedback since it only requires the plain text as input, and nothing else.
Here are a few more example outputs, for different products.
Reviews for the hot chocolate product from the beginning of this article:
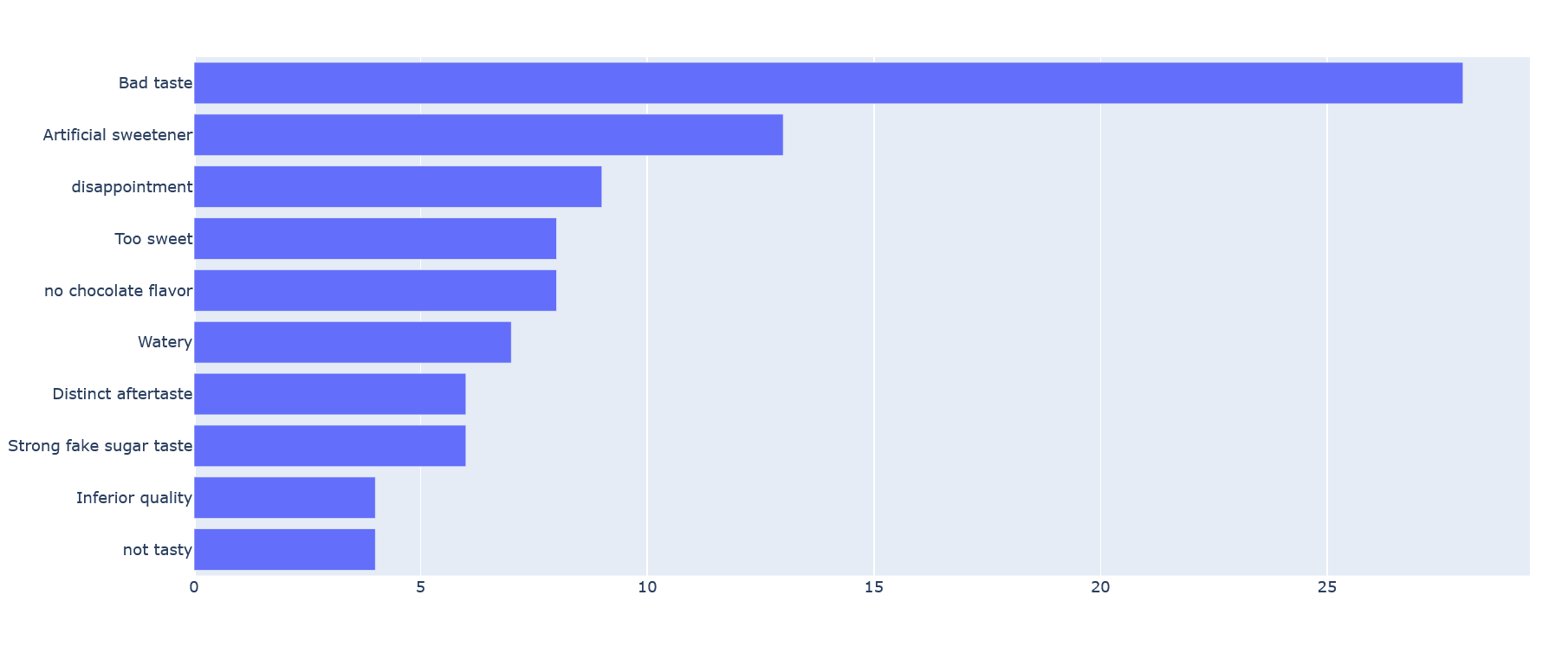
Reviews from some coffee pods (product ID B003VXFK44):
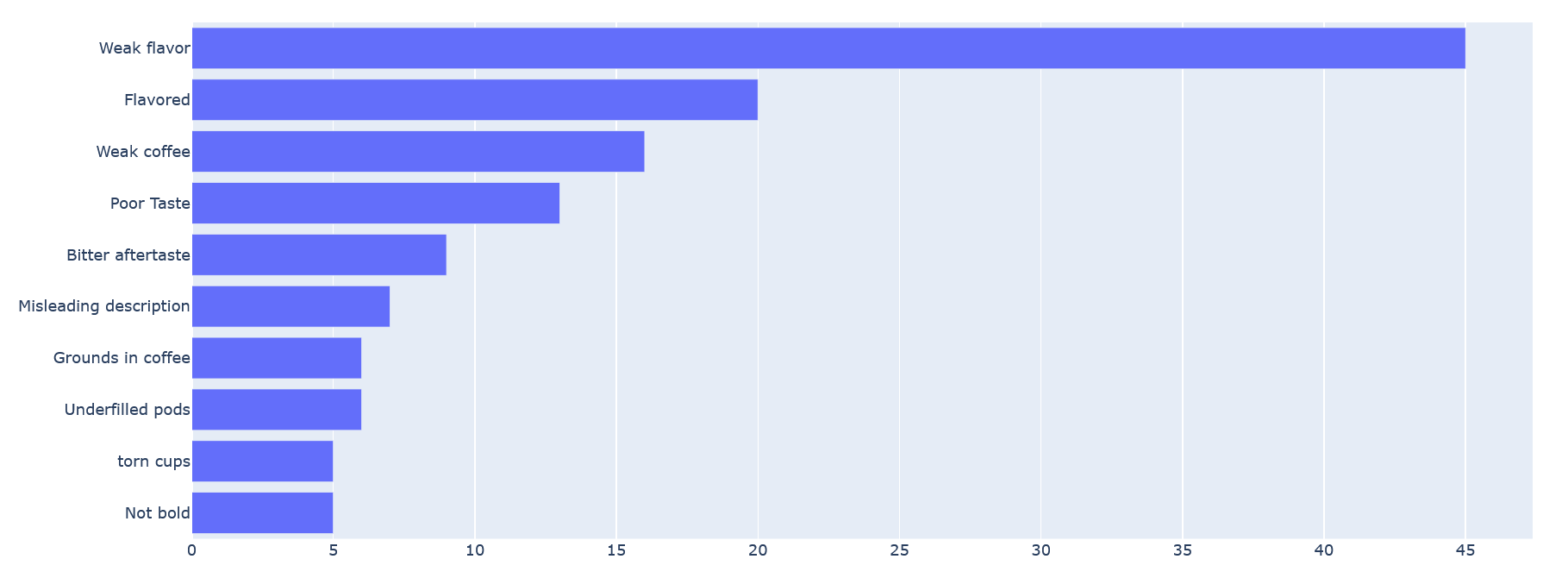
Again, generating these two extra graphs required only changing the product ID in the Python script, and no other input was necessary by the user.
Zero-Shot/Few-Shot Classification
Next up, we’re going to try to emulate Few-Shot classification using ChatGPT. In this case we do not ask ChatGPT to make up the categories, but we provide a set of options to ChatGPT to choose from.
For this, we are going to use the same hot chocolate product from the beginning. Reading a bit into the reviews, these are the 5 categories that we think are appropriate.
[“Weak taste”, “Bad taste”, “Bad aftertaste”, “Artificial sweetener”, “Too sweet”]
We are going to filter the reviews down to 2 stars or less. First, we will test it with a regular pre-trained classification model, and afterwards we will compare it to our ChatGPT method.
Zero-Shot Classification Using Pre-Trained Transformers
For this approach, we’re going to use Facebook’s bart-large-mnli with multi-label mode enabled. The idea is that if a review is classified with high confidence under a certain complaint category, we will assume that that review contains such a complaint.
After testing with a lot of reviews in order to find a good cut off confidence score, we’ve found that the confidences in the different categories depend mostly on whether the review matches their positive or negative sentiment, and not whether the actual complaint is contained within the review.
To illustrate this point, here’s a negative user review of a dog toy. Right below it are a few different categories and their respective confidence scores (they range from 0 to 1, higher is more confident):
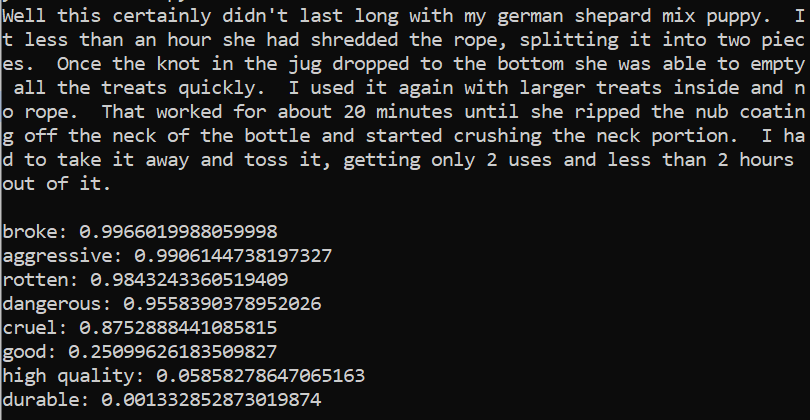
‘broke’ and ‘aggressive’ might make sense, it could be interpreted that the dog got aggressive and broke the toy. But ‘rotten’, ‘dangerous’, and ‘cruel’ have no business having such high scores, especially 0.984 out of 1 for ‘rotten’, when the word is not even mentioned in the text.
These results were replicated with almost all the reviews we’ve tested, also when trying out different categories; and even with positive reviews/categories. The problem seems to worsen the shorter the review is.
Regardless, we tried to classify the hot chocolate reviews and compared it to our manually chosen labels with a classification report, to see how it goes:
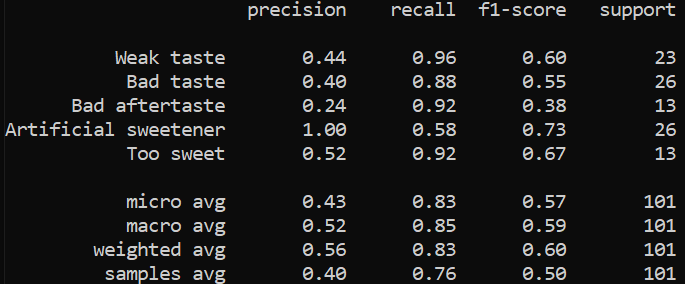
The F-score is not great at all, and looking at the confusion matrix we see that the number of false positives is higher than true positives. This was done with a confidence score cut-off of >0.8. However, raising this cut-off doesn’t help. Instead, it lowers the overall amount of positives, raising the number of true negatives and false negatives.
Although good for other applications, it seems that using pre-trained transformers is not very good for this particular use case.
Few-Shot Classification Using ChatGPT
Next up, were going to try to use the ChatGPT API to perform few-shot classification.
In order to do this, we’re going to take the list of different problem categories, and straight up ask ChatGPT to tell us which of those categories the review falls under.
After trying various prompts, we found that this one performs the best:
Given the following user review "REVIEW", tell me under which of
these categories it could
be classified under.
“Category 1”
“Category 2”
Etc.
Give no explanation, write the result out as a python list.
Here’s a few example outputs for reference:
Review 1: XYZ
Output 1: XYZ
Review 2: …
Etc.
We settled for 3 example reviews, given that after that the results stopped improving.
This is the result:
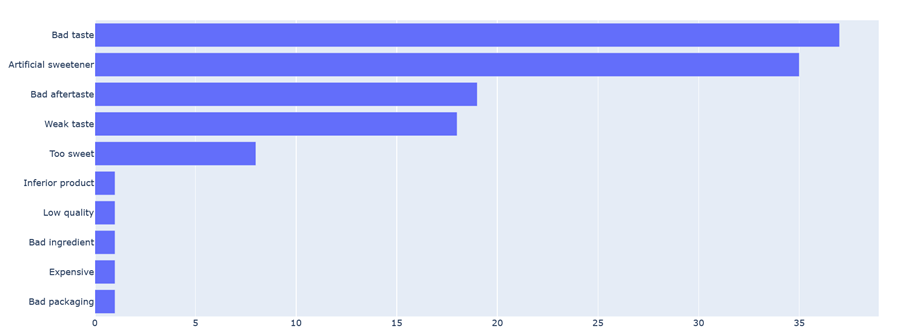
Tokens used in total: 10573. API usage cost = 0.03945USD for 64 reviews.
So far so good, although something that stands out is that ChatGPT has created new labels out of thin air. Looking into why, it seems that when a review falls under none of the complaints we provided, it creates new ones instead of returning an empty list.
This is a pretty simple error to filter out. We ask to check if the complaint is inside the list we initially gave, and if it’s not, simply discard it.
Now, we check the accuracy of this method.
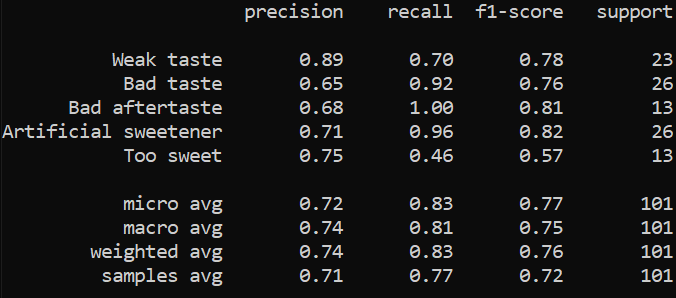
That’s a lot better. Checking the confusion matrix, we see that the number of false positives has dropped from 112 to 33. 33 is still somewhat high, but now the results are a lot more usable. One can actually start seeing what the main customer complaints are.
The transformer seems to be very good at predicting the overall sentiment of the reviews. However, we can already do that using the 1-5 star rating it comes with, so it’s not of much use to us.
The cost of the ChatGPT API usage was 0.04 USD for our example, or 0.000625 USD per review. This seems to be reasonable, especially given that this is the kind of analysis that you only perform occasionally, so the cost doesn’t pile up too much.
Another additional advantage against traditional methods is that ChatGPT is multi-lingual, which removes the need to translate the feedback before its processed. In fact, it’s as easy as adding
“write the answer in English”at the end of a prompt, and no matter what language the feedback is in, the result will always be in English.
Conclusions
We hope this article shows how the recent advancements in the LLM field can be used for more than the usual gimmick “write me an essay” or “write me a cover letter” prompts, and how LLM models can automate a lot of tasks involving natural language that would, otherwise, be very tedious to complete.
Our results are not perfect, they are probably susceptible to biases, and the exercise was not free. If we created a model to perform this task specifically and gave it a lot of supervised training, we would probably get better results. But given how we didn’t have to do any training, and how easy the implementation was, we see it as a realistic option for this kind of task. With Microsoft’s Copilot’s impending release, hopefully we will soon see the full potential of these tools for improving productivity and automation.
As a final note, there’s a concern to be mentioned regarding privacy. When using services like ChatGPT, you are sending information to OpenAI, and their privacy policy clearly states that they may collect any kind of information from your usage of their services, and then use it however they please. For more information, check the privacy policy of OpenAI.
In this particular use case, it doesn’t matter because these product reviews are already public. But this needs to be taken into account if you’re processing sensitive data that can’t be shared.
However, given the vertiginous speed at which the field is advancing, we could soon have GPT level LLMs running locally. Meta LLaMa 65B already works on Apple’s M1 chip, and the Standford team responsible for Alpaca claims to reach GPT levels with only 7B parameters, which indicates that they are becoming more accessible every day.
If you want to understand how advanced analytics and large language models can enable your organisation to become more productive and leverage the full value of your data, simply drop us a line and our expert consultants will be happy to help!
