
01 Sep 2021 What’s new in KNIME Analytics Platform 4.4 and KNIME Server 4.13
KNIME is an open-source data science platform enabling organisations to discover business value hidden in their data. It allows the blending of various data sources, ETL (Extraction, Transformation, Loading), modelling, data analysis and visualisation without (or with minimal) coding.
ClearPeaks is a trusted partner of KNIME and helps businesses to use the power of Advanced Analytics to deliver fresh insights to make strategic decisions and drive business value. In this article, we cover some of the exciting new features of KAP (KNIME Analytics Platform) 4.4 and KNIME Server 4.13.
1. Dynamic Data Apps
Data Apps (previously known as Guided Analytics Webapps) are now dynamic!
It is possible to deploy workflows as Data Apps with the desired user interface using widget nodes. In the new release, these are dynamic, so that users can choose to make a multi-step application, or have one or multiple refresh buttons (using Refresh Button Widget nodes) inside their application. Using these, users can interact with the data on the page and trigger the re-run of the workflow without leaving the page.
Below is a sample workflow that illustrates the use of Dynamic Data Apps, using the Refresh Button Widget:
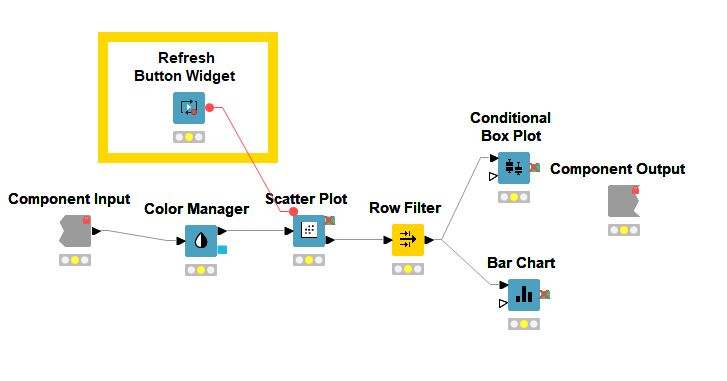
Execution at the web portal is shown in the next image. When the Refresh button is pressed, the conditional box plot and bar chart will be updated dynamically with the data points selected from the scatter plot:
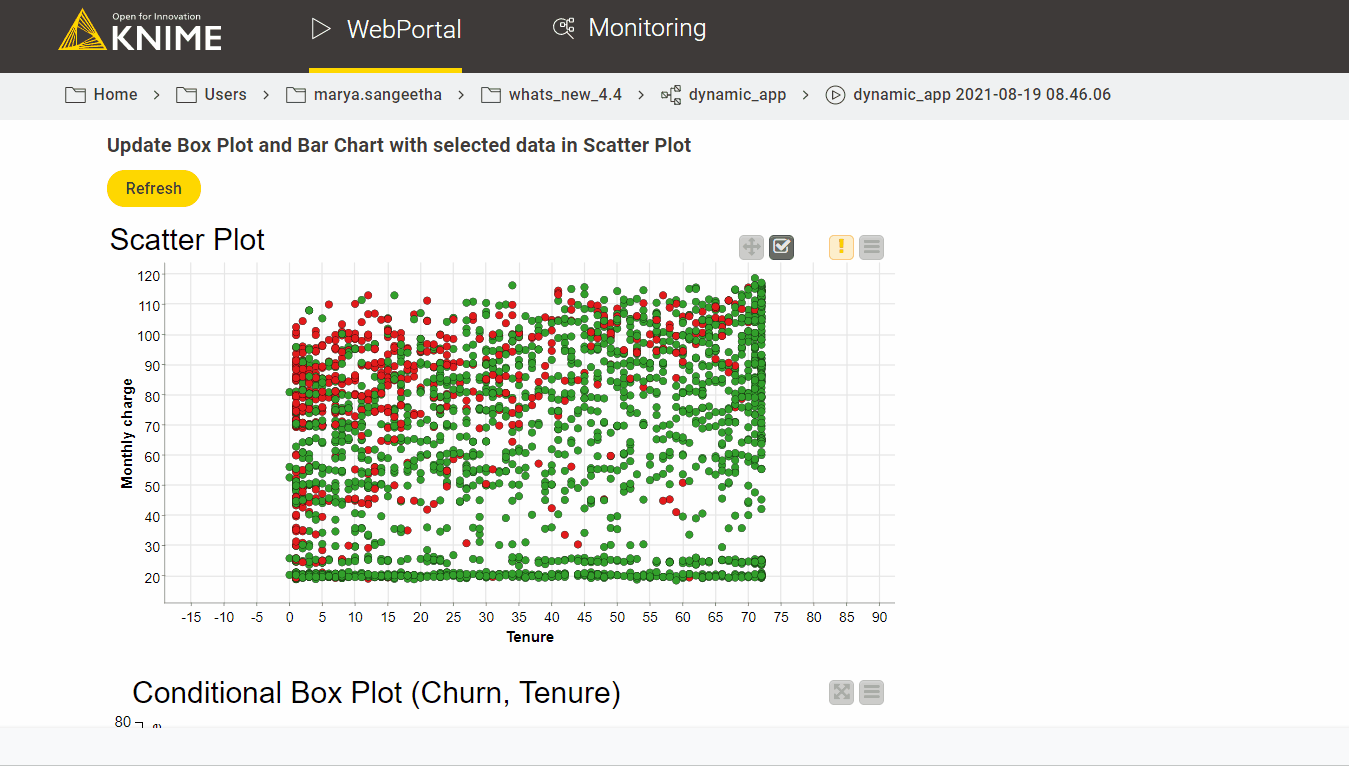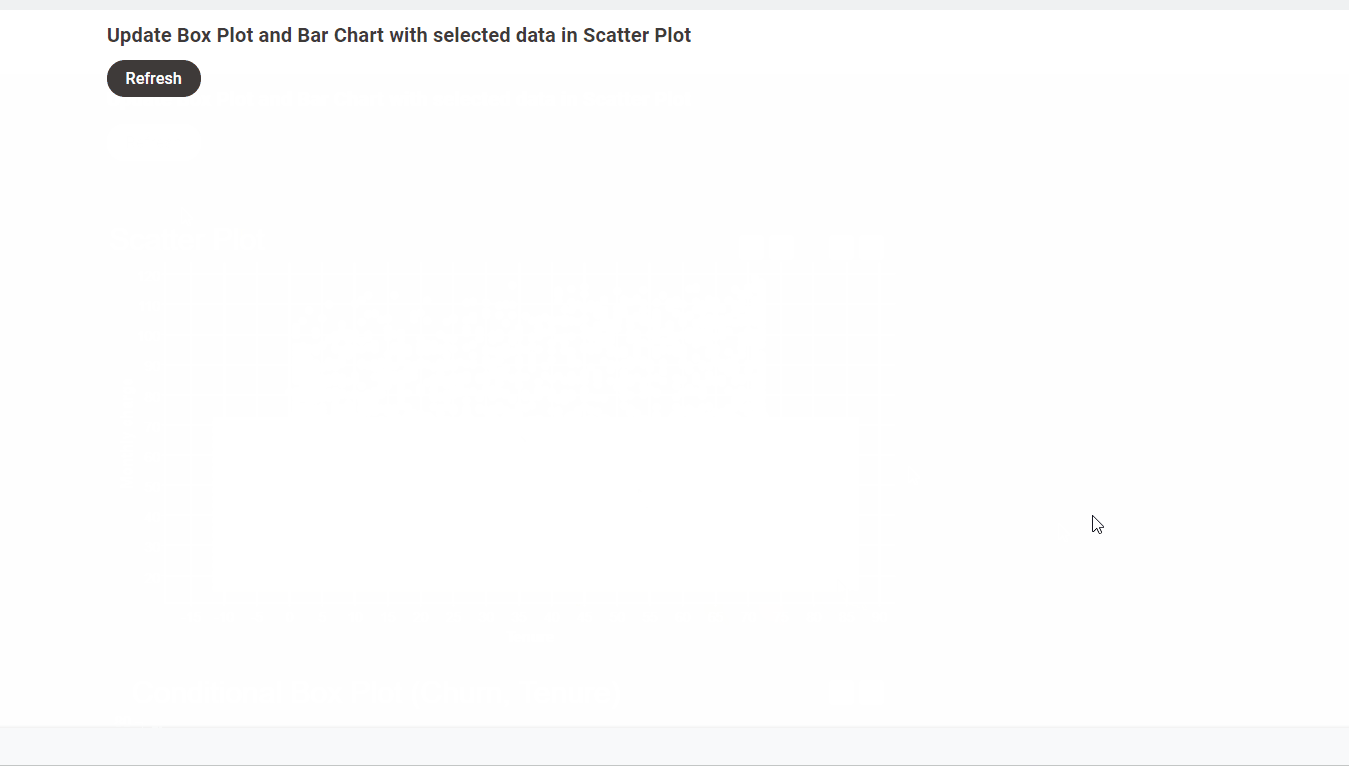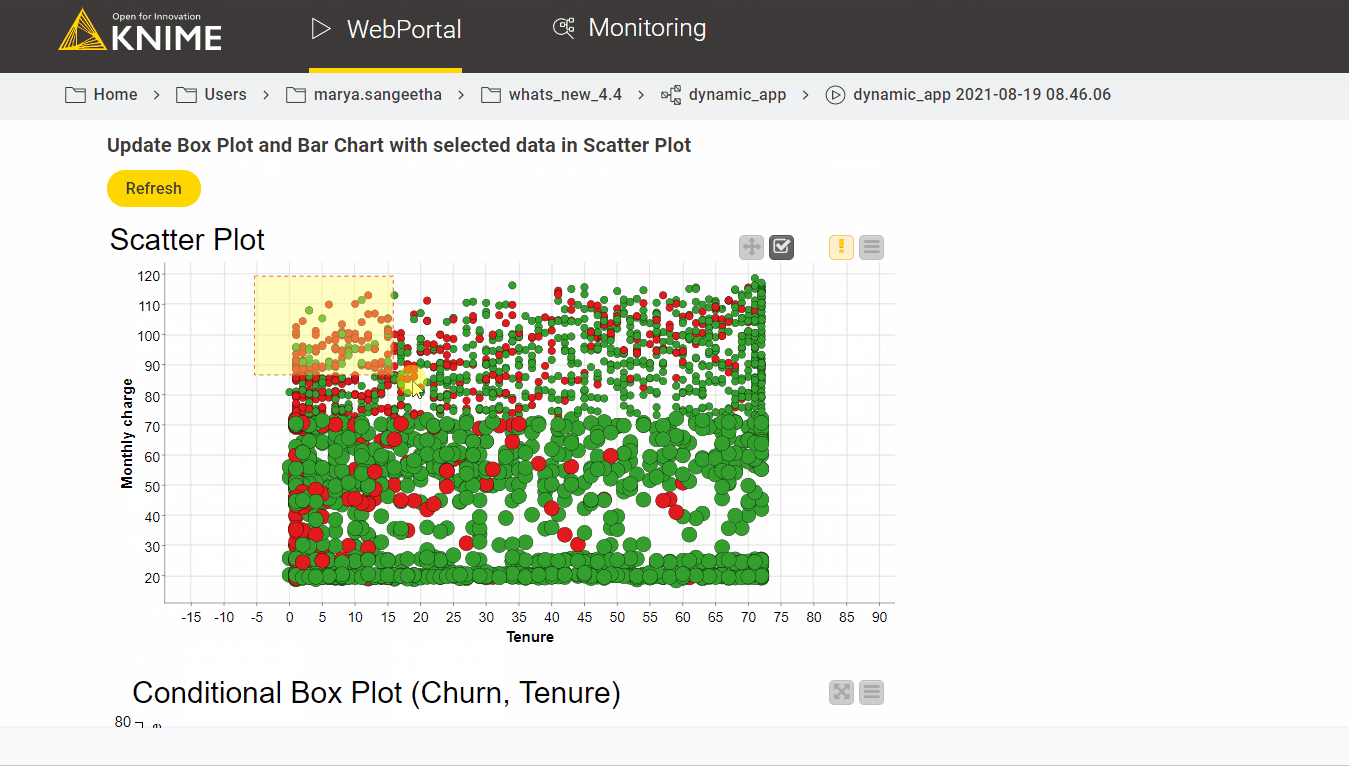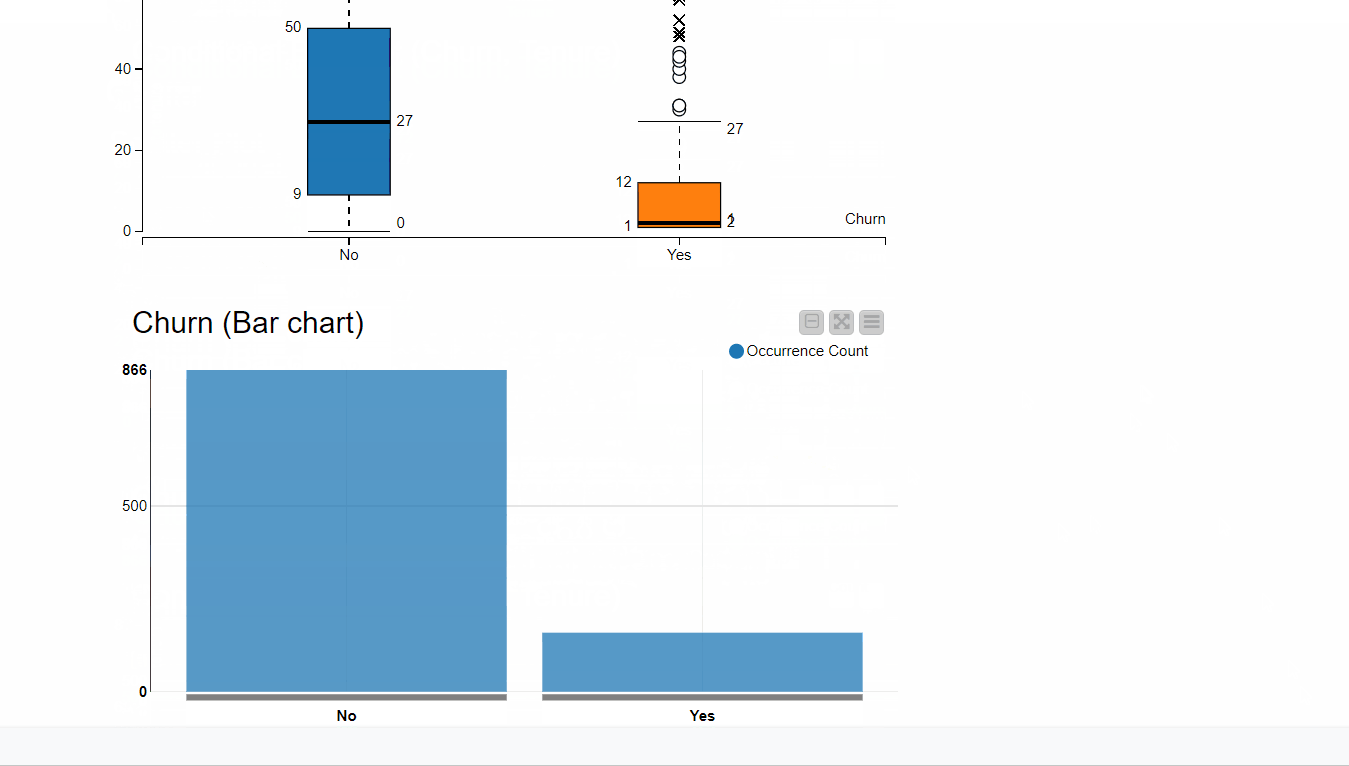
Data Apps are also now shareable, either via a link or embedded in a third-party application (available on Server Large).
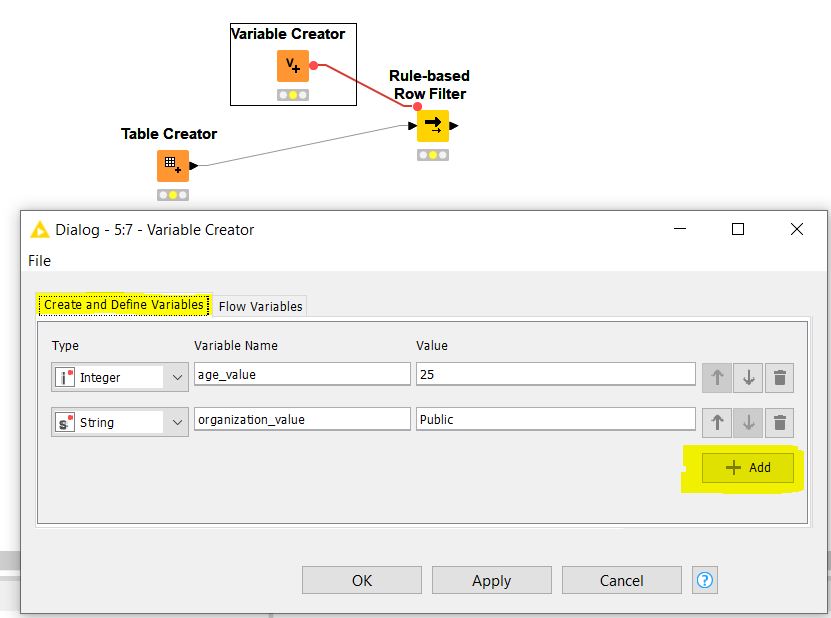
2. Variable Creator
For those who had issues creating flow variables, there’s good news for you! With the latest release, you can create and define a lot of flow variables effortlessly all at once, using the Variable Creator node as shown below:
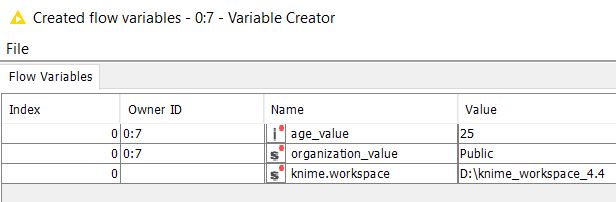
The next image shows the flow variables ‘age_value’ and ‘organization value’, created by the Variable Creator node, which can be further used by downstream nodes.
3. H2O AutoML nodes
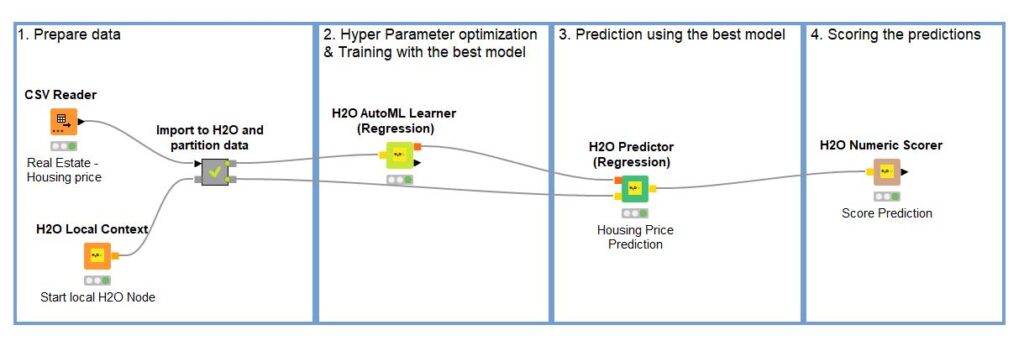
One of the most stunning new features is the H2O AutoML node, allowing the automatic training and tuning of various models. The H2O AutoML Learner node is used for classification, whereas the H2O AutoML Learner (Regression) node is used for regression tasks.
The image below shows a sample regression task, ‘Real Estate Housing Price’ using the H2O AutoML Learner (Regression) node:
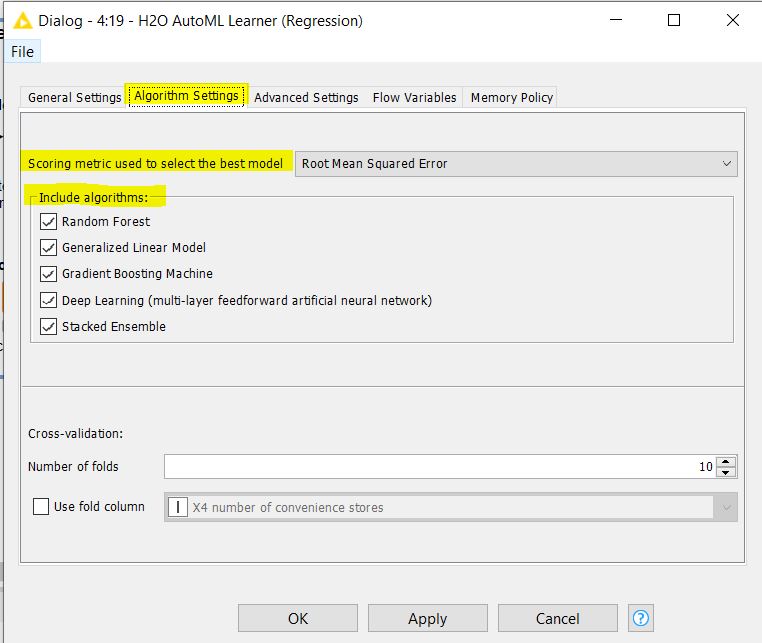
In the Algorithm Settings tab of the Learner node, you can choose the algorithms to be trained on and the scoring metric used to select the model:
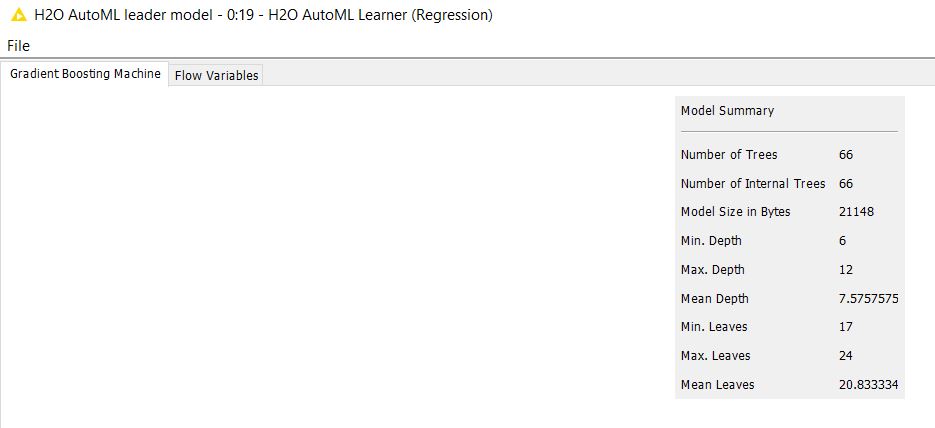
One of the output ports of the Learner node provides the best model, based on the scoring metric, as shown below:
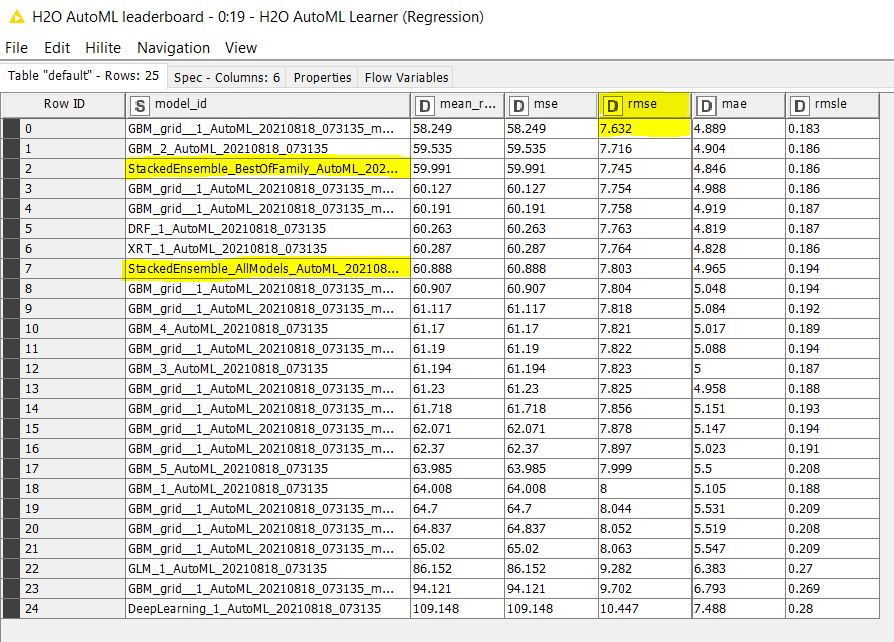
The other output port of the Learner node shows the leader board with results from all the models:
Checking the Stacked Ensemble algorithm in the algorithm settings will provide you with the result of highly predictive ensemble modes, one based on all previously trained models and the other based on the best model of each family.
The best model selected will be automatically used for the final prediction. H2O AutoML nodes can also be used on Spark.
4. Schedule Retries
While scheduling a job to the server, there is now the option to specify the number of retries for the job. A scheduled job may fail due to various reasons like a temporary connection problem to the third-party data sources. Providing retries for a failed job ensures it gets executed, even though the first attempt failed.
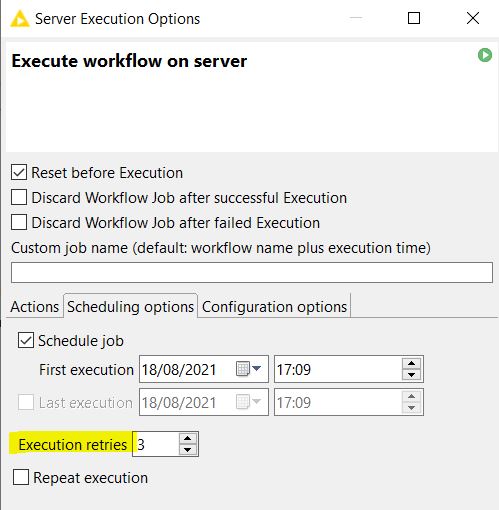
In the example below, the number of execution retries is given as 3:
5. File Handling Framework
KNIME continuously updates nodes and adds new connectors to the file-handling framework to offer a practical and consistent user experience. The Azure Data Lake Gen 2 Connector and the SMB Connector are two of these new additions.
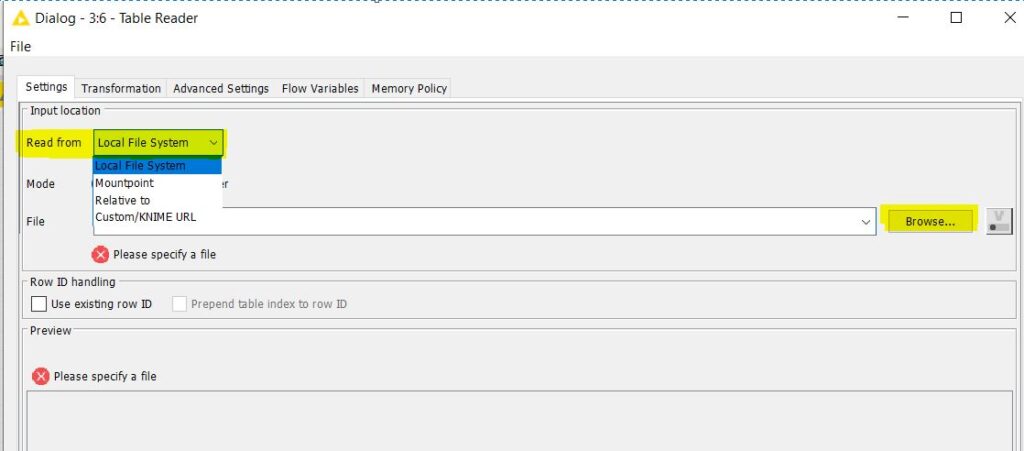
The File Reader, File Reader (Complex format), JSON Reader, Table Reader and Table Writer nodes now come with the new framework, allowing the browsing of files from local file systems or relative to workflow, etc.
6. Improved Indexing and Searching nodes
Advanced searches on millions of records can provide results in a fraction of a second using Indexing!
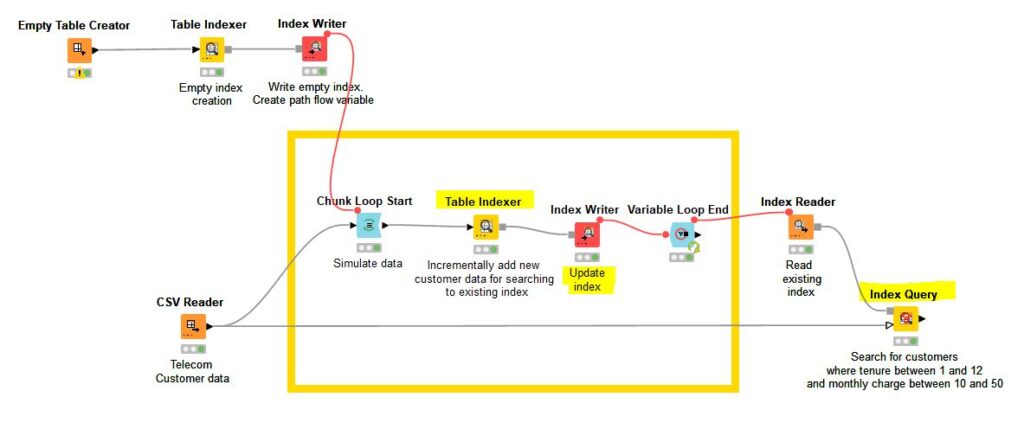
The Table Indexer Node creates an index from the input table. Each table row is represented as a document in the index. Once the index has been generated, it can be queried using advanced search techniques to find matches in milliseconds using the Index Query Node.
In this new version, the index can be stored in any supported file system and used across multiple workflows. The example below shows the incremental updating of an existing index:
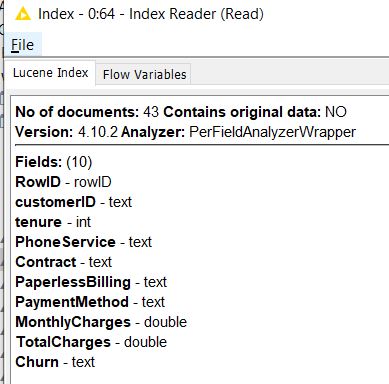
The image below shows the last updated index, read through Index Reader:
7. Error Handling for REST nodes
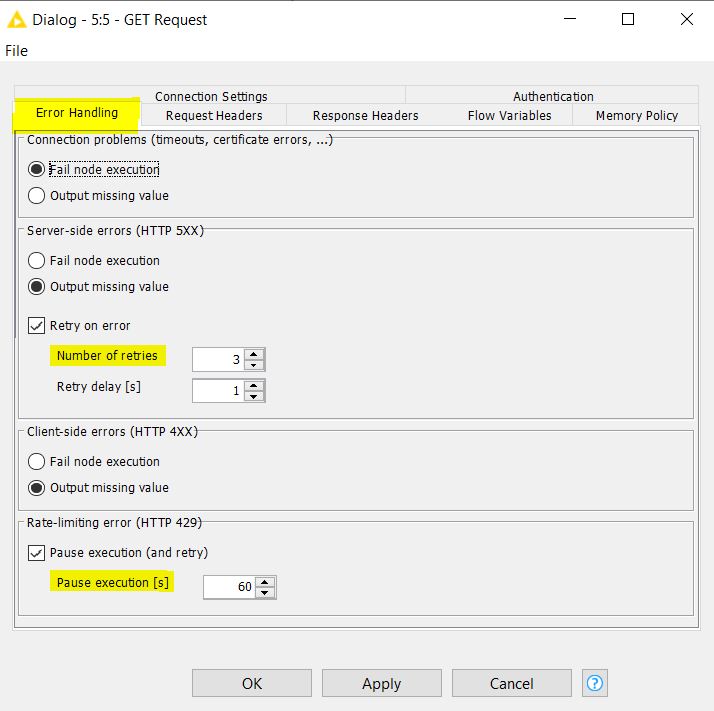
In the latest release, REST nodes (GET Request, Put Request, etc.) come with an additional Error Handling tab in their configuration dialogue, where the user can specify node behaviour in case of error. There can be client-side errors, server-side errors and rate-limiting errors that can cause node failures. For such scenarios, users can create error handling rules within the node itself, like the number of retries, pause execution, etc. The Error Handling tab is shown here:
8. Out of KNIME Labs
Newly developed nodes are first tested by the community in KNIME Labs. Numerous nodes have been moved out of KNIME Labs and are now production-ready!
Integrated Deployment Nodes that capture and write workflows have been moved out of labs. Two new nodes, Workflow Reader and Workflow Summary Extractor, have been added.
All Power BI Nodes and MongoDB Nodes including MongoDB Reader, Save, Update, Remove and Writer nodes are out of labs too!
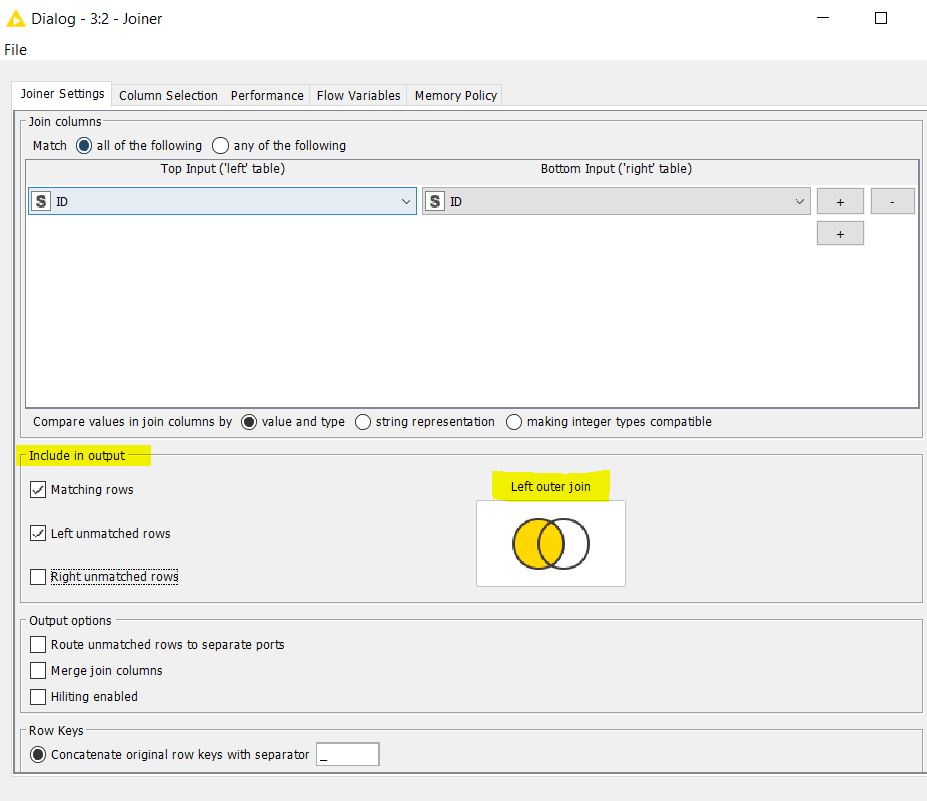
The Joiner Node, also out of labs, now has a different layout when selecting the type of join as shown below:
In addition to the features mentioned in this blog, there are others like the Snowflake Connector Node for In-Database processing, Conda Environment Propagation for R (previously Python), Enhanced Variable Scopes in Loops and Other Contexts, available as part of this new release.
In the previous version, try-catch, if-statements and loops had dedicated start and end nodes which defined the scope. Variables defined or modified inside them were not accessible downstream, something that is now possible with the new update.
Conclusion
Dynamic Data Apps are a remarkable feature in the new KNIME release, now more accessible and shareable. To reduce time and effort in modelling-related tasks, H2O AutoML nodes can be used to automate Machine Learning workflows. REST nodes now have error handling functionality. New connectors have been added, more nodes have been rewritten to the new file handling framework. Many nodes are out of Labs and more are on their way!
KNIME consistently strives to listen to customers, improve already existing features and add new ones to guarantee a hassle-free user experience. In partnership with KNIME, we work with our clients to provide innovative enterprise solutions and services that fulfil their data science needs. Contact us now and find out how our expertise here in ClearPeaks can help you in your Advanced Analytics journey with KNIME!
Subscribe to our newsletter to stay updated.
