
01 Feb 2023 Data Governance with Apache Atlas: Atlas in Cloudera Data Platform (Part 2 of 3)
In the first article in this series, we learned about Apache’s open-source offering for data governance, Apache Atlas, and took a detailed look at its architecture, capabilities, and web user interface. Nowadays, Apache Atlas is included in the offerings of many tech vendors, and one such vendor is the big data platform leader, Cloudera. In this second part of the series, we’ll see exactly how Atlas is integrated with Cloudera Data Platform (CDP), and how it provides connected governance when enabled with other Cloudera services.
Apache Atlas in Cloudera
Apache Atlas originated with Hortonworks Data Platform (HDP), and after the merger of Cloudera and Hortonworks, Apache Atlas was chosen as the de facto governance tool for CDP, the new data platform resulting from the mix of both HDP and CDH (the old Cloudera Distribution of Hadoop).
Within CDP, Apache Atlas is a standard metadata store designed to exchange metadata inside and outside the Hadoop stack, providing scalable governance for organisations and enterprises that are driven by metadata. It can be installed like any other CDP service, via the Cloudera Manager Admin Console, and requires HBase, Kafka, and SolR as dependent services (we’ll see why in the next section).
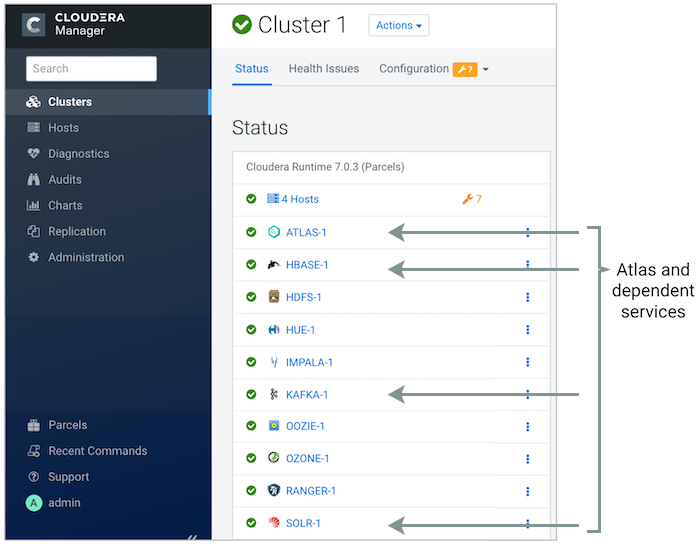
Figure 1: Atlas in Cloudera Manager
(https://docs.cloudera.com/cdp-private-cloud-base/7.1.7/atlas-configuring/topics/atlas-configure-status.html)
Atlas also supports multiple instances of the service in an active-passive configuration. Within Hadoop, Atlas provides various service hooks with command line interfaces that load metadata information from HBase, Hive, Impala, NiFi, Spark, Sqoop, and Kafka. However, Atlas also supports building custom hooks or, in simple terms, connectors (we’ll be going into this in more depth in our next post in this series).
Finally, the close integration of Atlas with Apache Ranger also enables you to define, administer, and manage security and compliance policies consistently, across all the Hadoop stack components.
Metadata in Cloudera
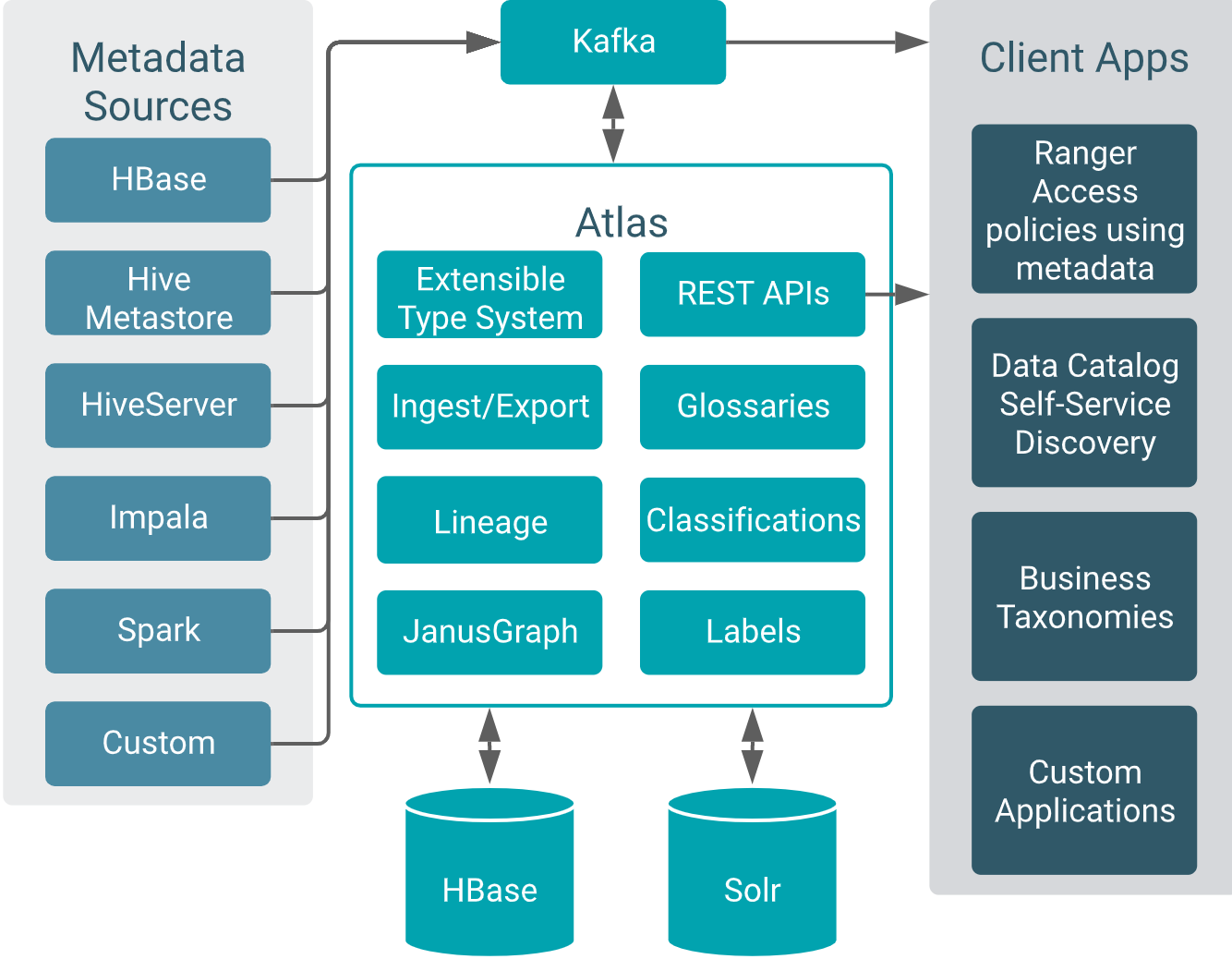
Figure 2: How Atlas loads metadata in Cloudera
(https://docs.cloudera.com/cdp-private-cloud-base/7.1.7/cdp-governance-overview/topics/atlas-overview.html)
In Cloudera, many data processing and storage services come with Atlas add-ons (the hooks) that enable them to release activity metadata on a Kafka topic called ATLAS_HOOK. When an action occurs in a Cloudera service instance (for example, the creation of a new table in Hive), the appropriate Atlas hook populates a metadata entity by gathering information and publishing this as a message on the ATLAS_HOOK Kafka topic.
When analysing this message, Atlas determines which data will lead to creating new entities, and which information will lead to updating existing entities. Atlas creates and updates the appropriate entities and resolves lineage from existing entities to the new ones.
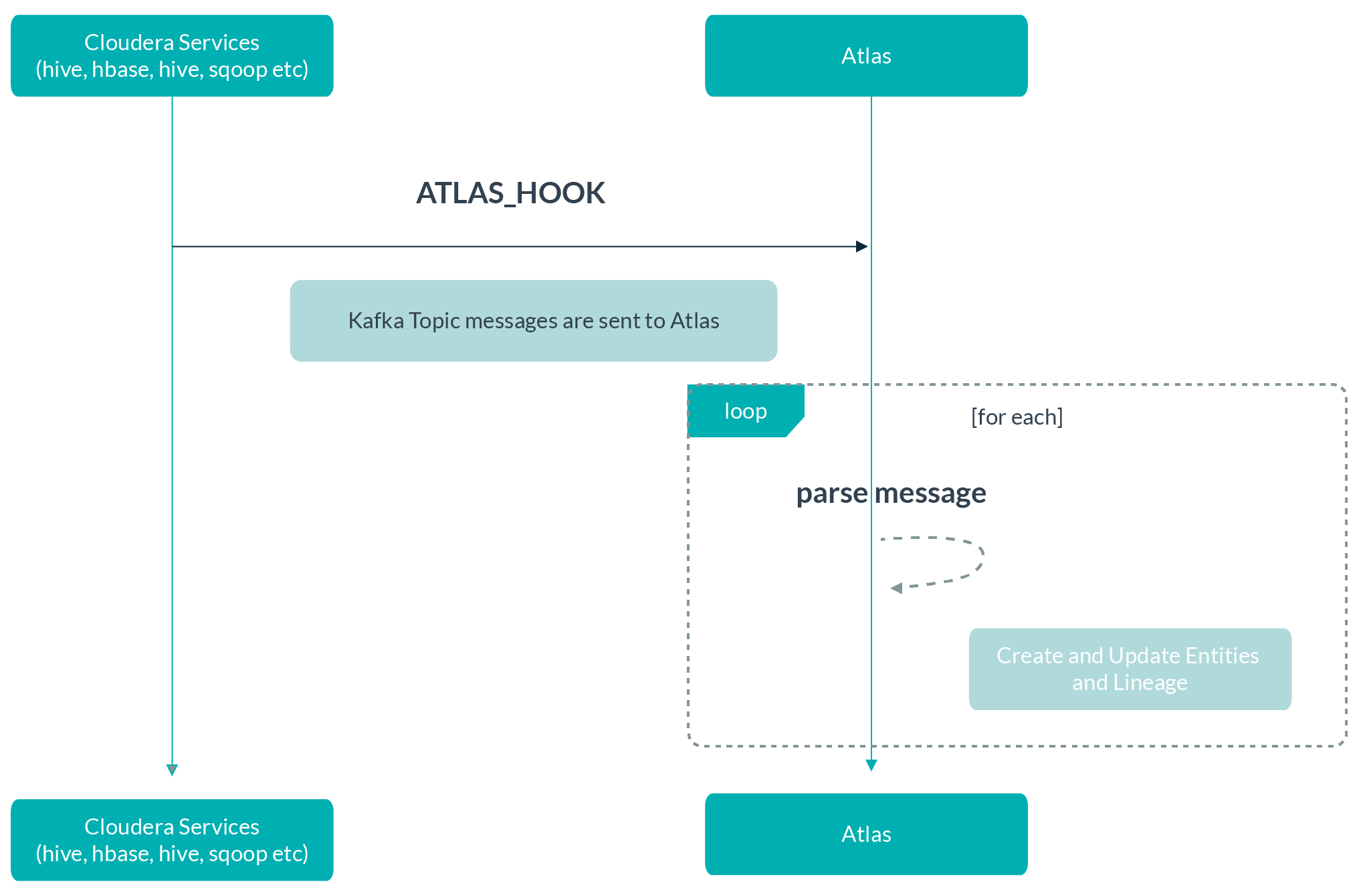
Figure 3: How metadata is updated via the ATLAS_HOOK Kafka topic
In addition, applications interested in metadata changes can monitor messages on the ATLAS_ENTITIES Kafka topic.
Internally, to model the relationships between entities, Atlas reads such messages and stores them both in JanusGraph, backed by an HBase database, and as search indexes in Solr.
Cloudera provides a set of Apache Atlas entities that are referenced for the collection of metadata information. Below you can see a table of available Atlas types when Atlas is part of the current deployment:
Source | Actions Acknowledged | Entities Created/Updated |
|---|---|---|
HiveServer | ALTER DATABASE CREATE DATABASE DROP DATABASE | hive_db, hive_db_ddl |
ALTER TABLE | hive_process, hive_process_execution, hive_table, hive_table_ddl, hive_column, hive_column_lineage, hive_storagedesc, hdfs_path | |
ALTER VIEW | hive_process, hive_process_execution, hive_table, hive_column, hive_column_lineage, hive_table_ddl | |
INSERT INTO (SELECT) | ive_process, hive_process_execution | |
HBase | alter_async | hbase_namespace, hbase_table, hbase_column_family |
create_namespace alter_namespace drop_namespace | hbase_namespace | |
create table | hbase_table, hbase_column_family | |
alter table (create column family) alter table (alter column family) alter table (delete column family) | hbase_table, hbase_column_family | |
Impala* | CREATETABLE_AS_SELECT | impala_process, impala_process_execution, impala_column_lineage, hive_db hive_table_ddl |
CREATEVIEW | impala_process, impala_process_execution, impala_column_lineage, hive_table_ddl | |
ALTERVIEW_AS_SELECT | impala_process, impala_process_execution, impala_column_lineage, hive_table_ddl | |
INSERT INTO | impala_process, | |
Spark* | CREATE TABLE USING CREATE TABLE AS SELECT, CREATE TABLE USING … AS SELECT | spark_process |
CREATE VIEW AS SELECT, | spark_process | |
INSERT INTO (SELECT), | spark_process |
Atlas in Action
We’ve talked about how Atlas hooks (or bridges) load metadata from various services, so now let’s run through an example for Hive DB in CDP.
Every time we create a Hive database in Cloudera Data Platform, different attributes of that table are loaded into the Atlas entity type hive_table. Here’s an example of the default hive_table structural attributes:
Attributes:
name: string
DB: hive_db
owner: string
createTime: date
lastAccessTime: date
comment: string
retention: int
sd: hive_storagedesc
partitionKeys: array
aliases: array
columns: array
parameters: map<string,string>
viewOriginalText: string
viewExpandedText: string
tableType: string
temporary: Boolean
Let’s create a Hive database in our Cloudera Hadoop platform using the command below:
CREATE DATABASE atlas_test_db;
After its successful creation, we will see that a new entity, type hive_db, is also created in Apache Atlas. Note how it also has additional information about this Hive database, which we never provided:
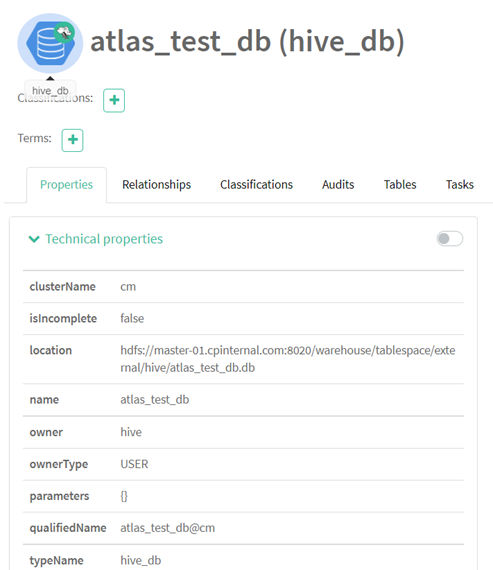
Figure 4: List of attributes captured for hive_db entity in Cloudera
The information is extracted from the underlying system and stored as metadata in Apache Atlas. This information tells us more about this database, such as where it is stored on the disk, who is the owner of this database, when this table was created, and so on:
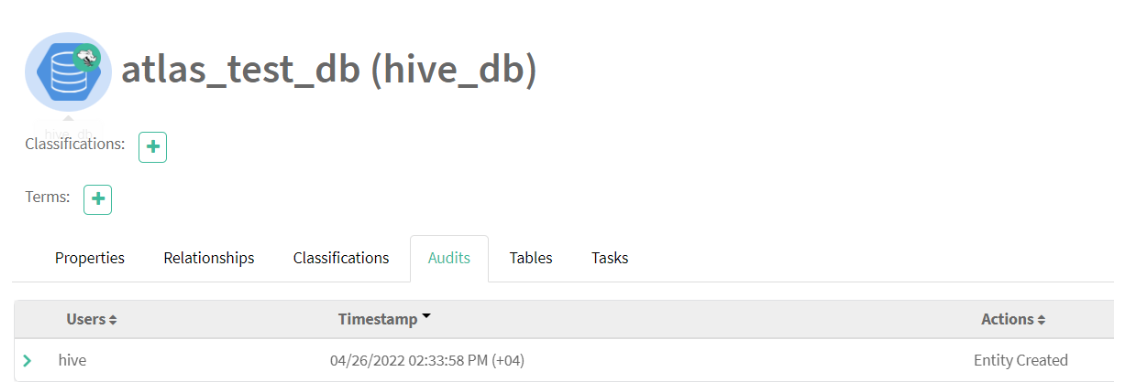
Figure 5: Audits captured for hive_db entity in Cloudera
Now we’re going to create a table in the above database using the script shown below. Once again, the information in this table is unimportant; our real interest lies in the metadata associated with this table in Apache Atlas:
create external table AtlasTestHive
(
id string,
name string,
group_name string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/tmp/testAtlas'
tblproperties ("skip.header.line.count"="1");
A table relationship pointing to the Hive DB is also built after the creation of the table; an audit log simultaneously captures entity creation, update, and delete events:
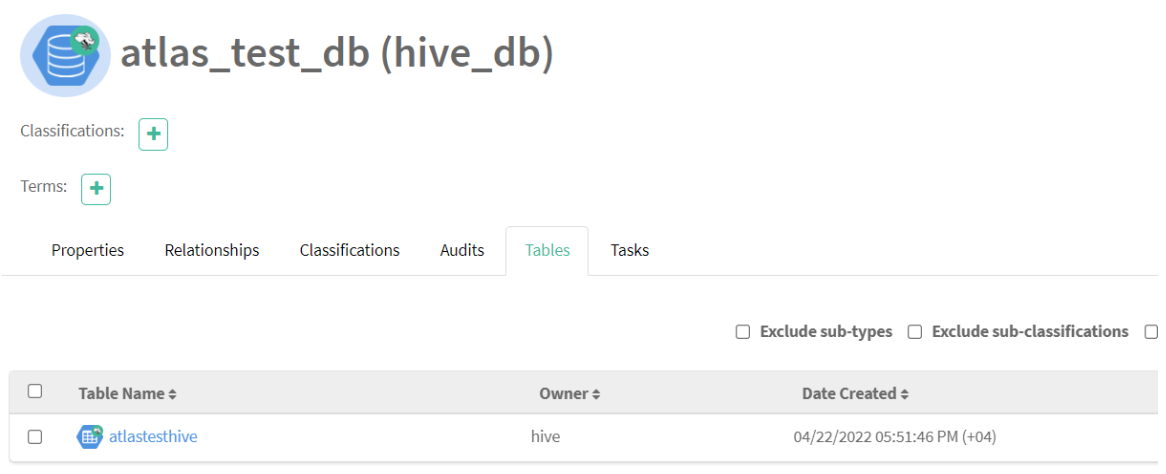
Figure 6:Table audits captured for hive_db entity in Cloudera
We created three fields: id, name, and group_name, each representing a string data type. Soon after the table was built in Hive, an entity of the type hive_table was also created in Atlas, collecting a good amount of information on the table. A unique qualified name is assigned to this entity. In addition, not only do we see the columns (of type hive_column) and DB name (of type hive_db), but also information related to the creation time of the table, when it was accessed, who is the owner, what type of table it is, etc.
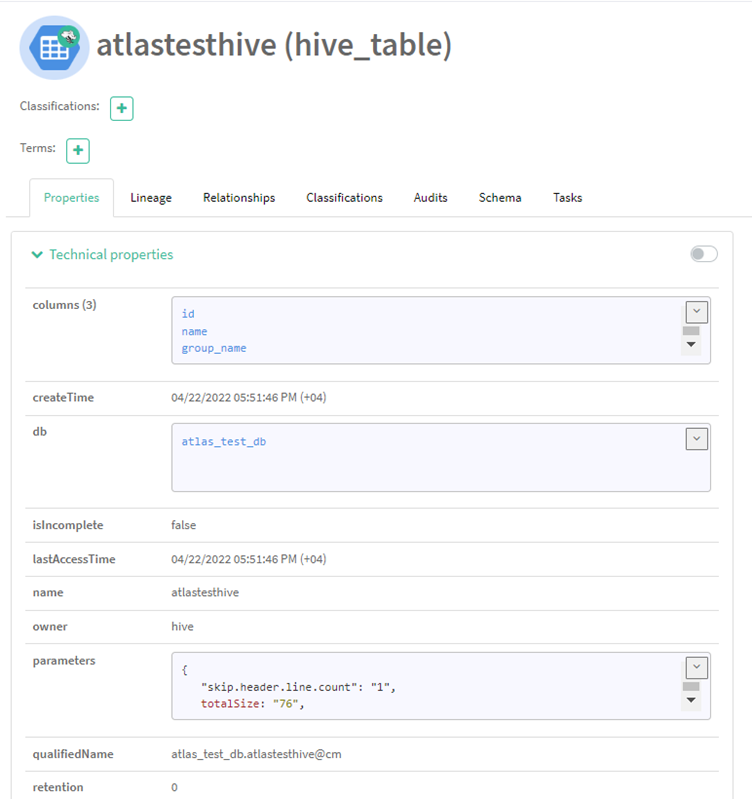
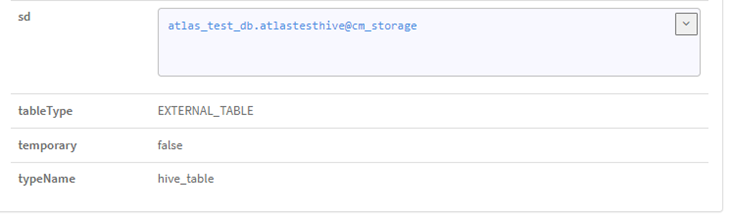
Figure 7,8: Entity of type hive_db
Now, let’s wrap up the overall process. We had a location in HDFS, which created an external table called “atlastesthive” in the hive. The completed lineage is also automatically created by Atlas, and can be viewed in the Lineage tab of that entity:
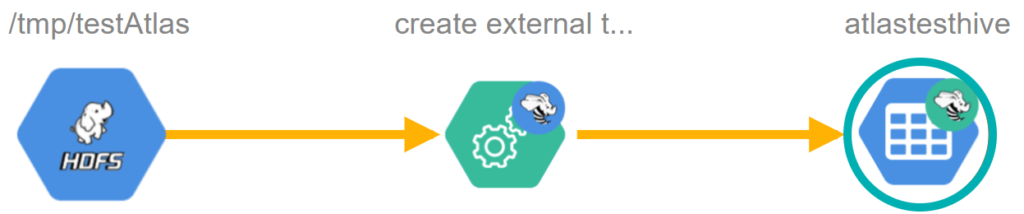
Figure 9: Data lineage for the AtlasTestHive table
Similarly, there are several other tabs available: in the Relationship tab, we can see column relationships, database relationships, process relationships, storage descriptions, etc.:
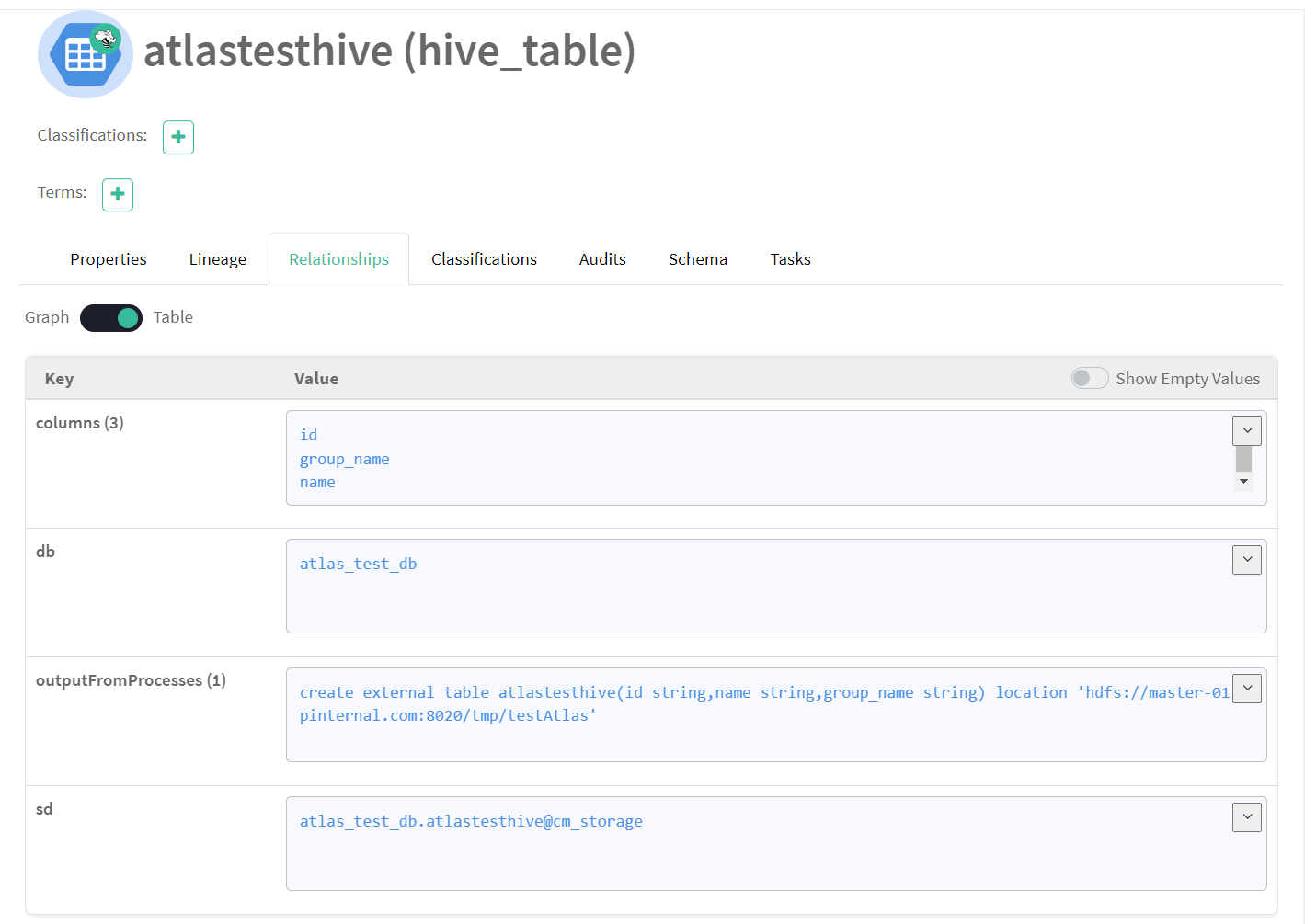
Figure 10: Relationship details of the AtlasTestHive table
However, some of this information is repeated in other tabs, like the Schema tab, which also has details about columns:
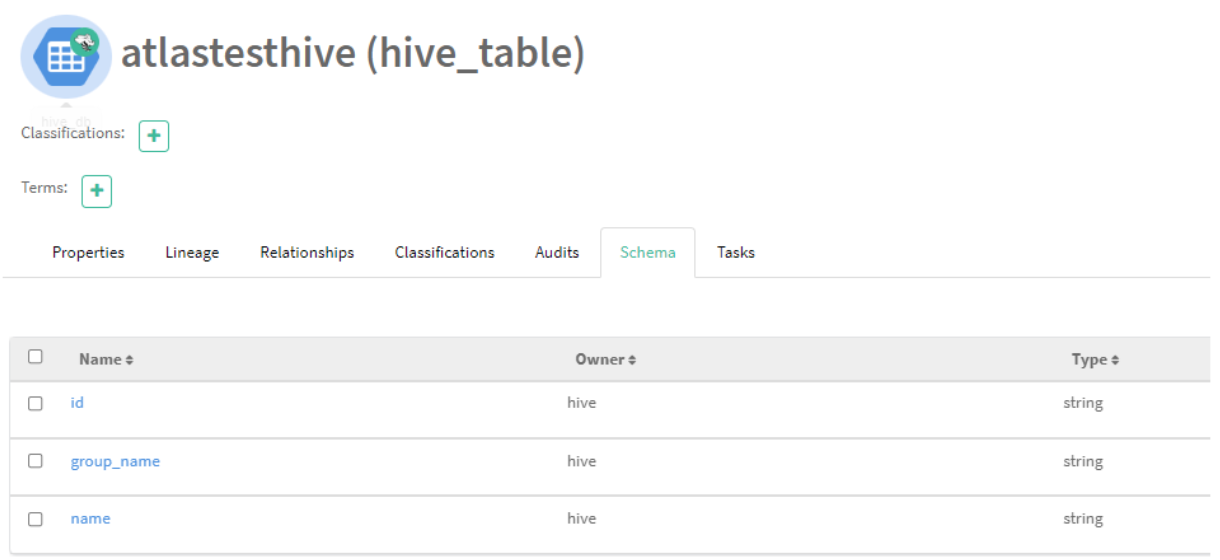
Figure 11: Schema details of the AtlasTestHive table
Now, let’s click on the “id” column: we can see all the information related to this column, categorised as a new entity of type hive_column:
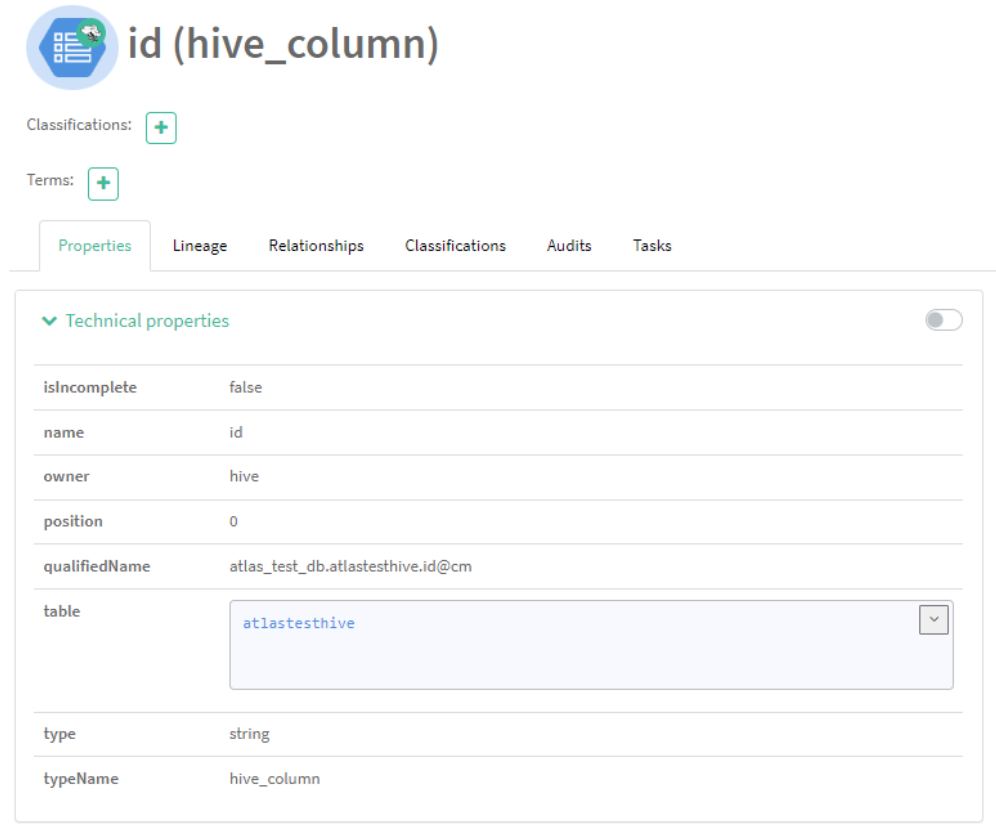
Figure 12: Hive column (id) metadata details
Summarising, the overall process gives us information about three important entity types – hive_db, hive_table, and hive_column. Depending on the service used for the processing, we can utilise the type we’re working with in any data processing job. For example, we could use a Kafka Topic in our data processing and have the entity type kafka_topic capturing metadata about it in Apache Atlas. Atlas, in Cloudera, provides these entity types for almost all the services that are used inside, making CDP really convenient for displaying the organisation’s connected governance efforts.
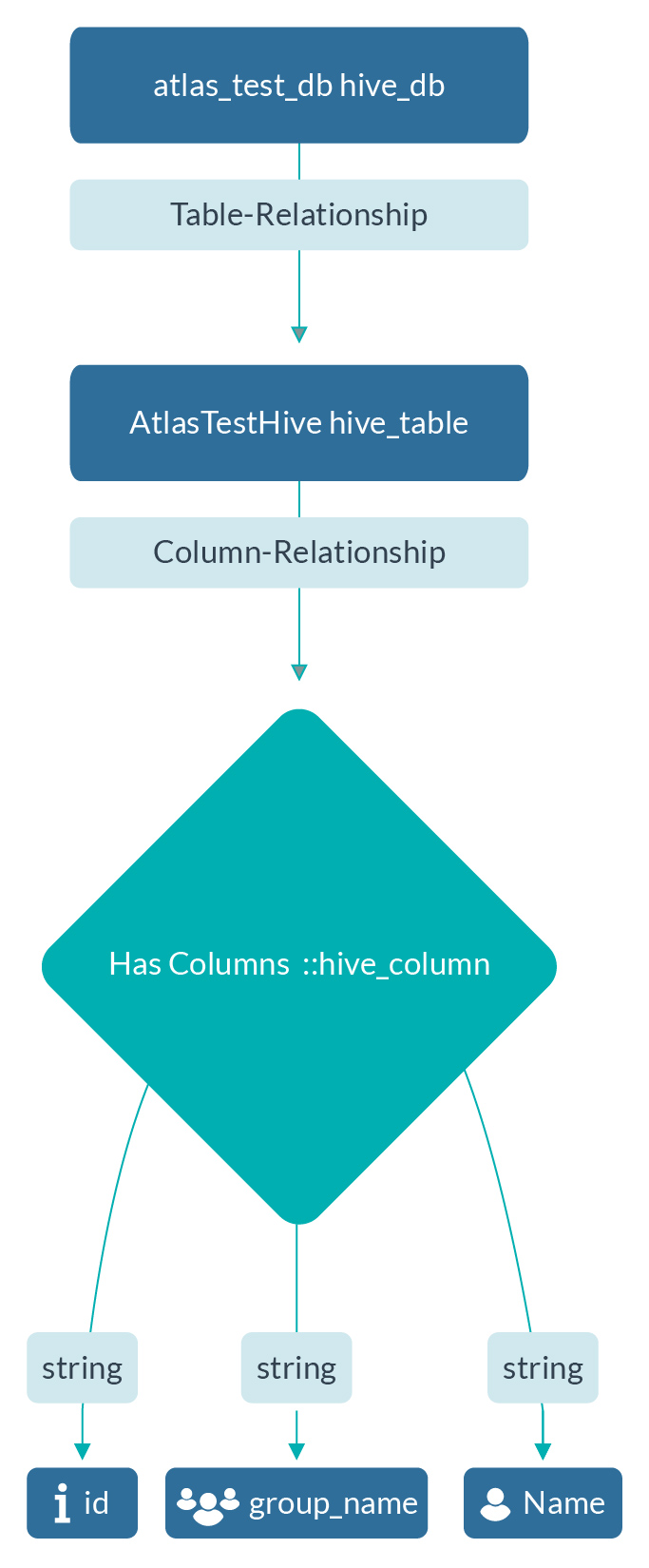
Figure 13: Overall entity types utilised in the example
Next Steps
In this article, we’ve looked at Atlas in the context of Cloudera Data Platform, and gone through data processing as well as moving data from HDFS to Hive. We’ve also analysed the background metadata model created by Apache Atlas for our overall process, and seen different types created as part of Cloudera’s built-in Atlas type.
In our next article, we will build a custom entity type and create hooks to load data and relationships in Apache Atlas.
If you have any questions about what you’ve read, or if you are simply interested in discovering more about Cloudera, Apache Atlas, or any other data tool for that matter – do not hesitate to contact us at ClearPeaks. Our certified experts will be more than happy to help and guide you along your journey through Business Intelligence, Big Data, Advanced Analytics, and more!
