
10 Mar 2022 Data Mesh, Data Lakehouse, DataOps, Data Governance and Data Observability – What You Need to Know to Build Your Next-Generation Enterprise Data Platform
I intentionally named this article after some of the hottest buzzwords on the current (and future) data analytics landscape (at least I left out the Artificial Intelligence ones!). The choice was not only to get clicks, which I hope it does, but also because we’re going to look at all the terms in the title: what they have in common, what they are, how they relate to each other, and why it is a good idea to know about them (Spoiler alert: the answer to the last point is in the title – knowing about these terms will help you build your next-generation Enterprise Data Platform).
This blog is also a follow-up to the YouTube video we recently posted on the fourth-generation Enterprise Data Platform, the Data Mesh, so if you want to get the full context of the blog (and learn about data mesh in the process), I recommend you check out the video before joining me here – it is very much focused on data mesh, the cornerstone for building a fourth-generation Enterprise Data Platform. Towards the end of the video, I briefly mentioned how all the above-referenced terms relate to each other and how, by joining them together, we have a complete next-generation Enterprise Data Platform, and here we’re going to go in a bit deeper.
What They Have in Common
Scale is what they all have in common. More and more companies are transforming themselves into data-driven organisations, and as that happens, more and more data is being used for everything, but let’s focus on the use of data for analytics purposes for now.
Analytics data is no different though, every day more and more of it is generated, transformed, and consumed – every day there is a new data source, or a new analytics use case that requires new data to be ingested and transformed in a data platform and served to expectant consumers.
While small companies or companies with a “low” data footprint may be fine with relatively simple data platforms, as “data-drivenisation” happens, the traditional ways of architecting and managing data platforms may not suffice, and organisations will start looking for alternatives and improvements.
All the concepts here are such alternatives and improvements, and they make a lot of sense when dealing with data and use cases at scale. Even though they look at the scale issue from different angles and tackle different aspects of it, the truth is that if you are building a data platform at scale, you’d better learn about them and leverage them. So, let’s make some introductions.
What They Are
Below we define data mesh, data lakehouse, DataOps, data governance, and data observability. Note that each of these concepts could fill many pages, but here I’m going to be brief, get to the point, and give the reader a basic understanding of each concept. If you want to dive deeper into any of these terms, there are plenty of other blogs out there.
My objective is rather, once we have established the basics, to discuss how the terms relate to each other, and how they fit together in a complete and technology-agnostic reference architecture to build a fourth-generation Enterprise Data Platform with all the capabilities you should expect.
Data Mesh
Data mesh is a new paradigm created by Zhamak Dehghani for building the next-generation data platform, addressing various limitations of previous generations. In Zhamak’s original data mesh write-up she covers these limitations very well and we also talked about them in our video so we are not going to repeat them here. But the bottom line that she proposes is:
- A decentralisation of the centralised and monolithic data platforms we have been using until now, fully embracing Domain Driven Design (DDD) to create a distributed domain-driven architecture in which data ownership always stays with the domains.
- A complete treatment of data assets as products, hence “data products”. As highlighted in the previous point, it is the responsibility of the domains to own, host and serve their data products in an easy and interoperable way. This requires a shift from the traditional “push and ingest” to a “serve and pull” model across domains, where data pipelines (in charge of ingesting and transforming data) are no longer centrally managed but are owned and handled by the domains, and are a logical part of the data products.
- A Self-Service Data Infrastructure as a Platform, owned by a “central” data platform team, the purpose of which is to provide the data infrastructure components in a self-service manner while hiding all the underlying complexity.
- A federated computational governance that sets standards, ensures interoperability, globalises security and compliance, defines boundaries between domains, and avoids entity duplication.
While the concept of data mesh is technology-agnostic, many data platform tech vendors are already talking about it and discussing how a data mesh can be implemented with their tech stack. Check out, for example, this blog post from Cloudera (ClearPeaks has recently participated in a data mesh implementation with Cloudera Data Platform Public Cloud and AWS).
Data Lakehouse
Even though I first heard about the data lakehouse through Databricks, the term itself was initially coined by Pedro Javier Gonzalez Alonso in 2016, and was adopted later by Snowflake, Dremio, and others. While I could not find any official documentation on data lakehouses on Azure, a quick web search will reveal many external blog posts about building data lakehouses on Azure, especially with Azure Synapse. AWS hosts a blog post that introduces the term and details the lakehouse reference architecture on AWS. Likewise, GCP also hosts a blog post detailing their view on data lakehouses.
Trying to come up with a common definition of a data lakehouse is tricky, since all data platform tech vendors say slightly different things and look at the term in the most convenient way for them. However, I do like the first paragraph in the Databricks definition:
A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data.
So, it is a new architecture that combines data lakes and data warehouses; and if we read the rest of the Databricks definition, we will see that in their case this combination is offered in a single platform that also takes care of data transformations (and some ingestions).
At this point, though, different vendors have different views on the expected features of a data lakehouse. Some vendors, because they do not really offer a strong data transformation engine, will skip this in their definition of a data lakehouse. Other vendors may lack strong job orchestration capabilities, so that part will be ignored in their definition. The same happens with topics such as governance, security, etc. Finally, some vendors will detail a data lakehouse that, in reality, is composed of many different services instead of a single platform.
Not all is lost though! It is clear that a data lakehouse offers both data lake and data warehouse capabilities (although tech vendors differ on what those capabilities are exactly), and we can also agree that whatever this data lake + data warehouse combination actually is, it is done in a way that it is either in a single platform or in various platforms/services that are highly integrated (for example, via common cataloguing or the ability to move data around easily), ultimately making the usage experience better than when we have decoupled data lakes and data warehouses.
DataOps
DataOps has its origin in the DevOps movement in software engineering, but also in Lean Manufacturing, Total Quality Management and Agile. DataOps proposes, for the development of our data operations, utilising version control in code repositories enabling parallel development and code reuse (most probably using solutions based on Git); continuous and automated testing; continuous integration and continuous delivery (CI/CD); and self-organising teams working in short development sprints.
By “data operations” we mean not only the development of the data pipelines that ingest, transform, and serve data in an organisation, but also the creation of the data infrastructure to handle these data pipelines; and in that context, we also find the use of automated infrastructure provisioning mechanisms with infrastructure as code (IaC) solutions such as Terraform.
DataOps can help organisations to achieve high levels of productivity and quality in their data operations, while nurturing team collaboration. However, DataOps requires a cultural change in the organisation: not just a set of tools to take care of the technicalities, but also an understanding (and collaboration and even patronage) of business stakeholders in order to drive the onboarding of DataOps in the company.
Data Governance
As with data lakehouses, when we look at the definitions of data governance from tech vendors, we also find differences depending on their offerings. So, as a starting point in ClearPeaks, we like to look at the technology-agnostic definitions of DAMA in their DAMA-DMBOK (Data Management Body of Knowledge). Their initial definition states:
Data Governance is defined as the exercise of authority and control (planning, monitoring, and enforcement) over the management of data assets.
DAMA also defines data governance in the context, and in a guiding role, of the so-called DAMA-DMBOK2 Data Management Framework, in which data governance is essentially the business-driven framework that guides all the data management functions in an organisation. And by all data management functions, we mean all of them: data architecture, data storage, data modelling, data warehousing and Business Intelligence, metadata management, data quality, data security, data integration and interoperability, master and reference data management, and document and content management.
Data governance is not all the stuff we’ve just listed, but the processes and policies to carry them out, and for the entirety of the data life cycle, in a standardised, compliant and secure way, with defined roles and responsibilities, i.e., data owners and stewards, to ensure the whole thing is done properly.
More and more tech vendors have data governance offerings that focus on data cataloguing with extra features such as the definition of business glossaries, lineage analysis, issues management, etc. (for example, check out our upcoming blog on Azure Purview). These data governance tools also provide functionality for the definition of roles – owners or stewards of the catalogued data assets – and functionality to make the work of these owners or stewards easier.
Note that data governance is not just something we need to consider from a technological point of view, for it is also an organisation-wide endeavour that requires patronage from the higher spheres (C-level) of the company. It is not just cataloguing and stewardship, but all the rest of the organisation’s processes and policies to standardise and secure the management of their data assets.
Data Observability
Our last term of today, before we wrap them all together, is data observability. Data observability focuses on tracking and managing the health of the data and its underlying systems, so it revolves around monitoring, testing, lineage, provenance, risk identification and mitigation, and in enabling the delivery of the best possible data quality and consistency, so that all the related metadata is easily consumable by all the interested parties via easy-to-use APIs or web UIs that can answer questions like “how much data was loaded in the last pipeline execution?”, “was the loaded data the expected amount?”, “did it have the expected format?”, “when was it loaded?”, “what is the quality level of the loaded data?”, and so on.
As with DataOps and data governance, data observability also requires an organisation-wide commitment. While the concept itself is more recent than data governance, there is an emerging market of tools that provide data observability capabilities with cool features such as predicting incidents or data quality issues.
How They Relate To Each Other
Let’s start with last two items we’ve covered: data governance and data observability. While there is an obvious overlap between these two concepts (for example, both concepts involve lineage), they have a different focus, and you might even find they are managed by different teams in an organisation.
Now, let’s add DataOps to the mix. DataOps is related to both data governance and data observability to such an extent that it’s difficult to imagine either of them existing without a number of DataOps processes in place.
On the other hand, the concept of the data lakehouse is more a technical detail – the ability to have certain technical capabilities in an easier and more integrated way – so this term is a bit different from the other three.
Finally, data mesh – the new paradigm that promises to solve all our at-scale Enterprise Data Platform problems. If we look at the definition of data mesh (check out our YouTube video and the blog posts by Zhamak) we will realise that most of the terms we’ve covered today are already there, either explicitly or implicitly.
Why It’s a Good Idea to Know About Them
As the title states, if you aim to build an Enterprise Data Platform that can cope well with scale at all levels, you will most likely be looking at an architecture that combines all the terms we discussed today. And such an architecture will look like this:
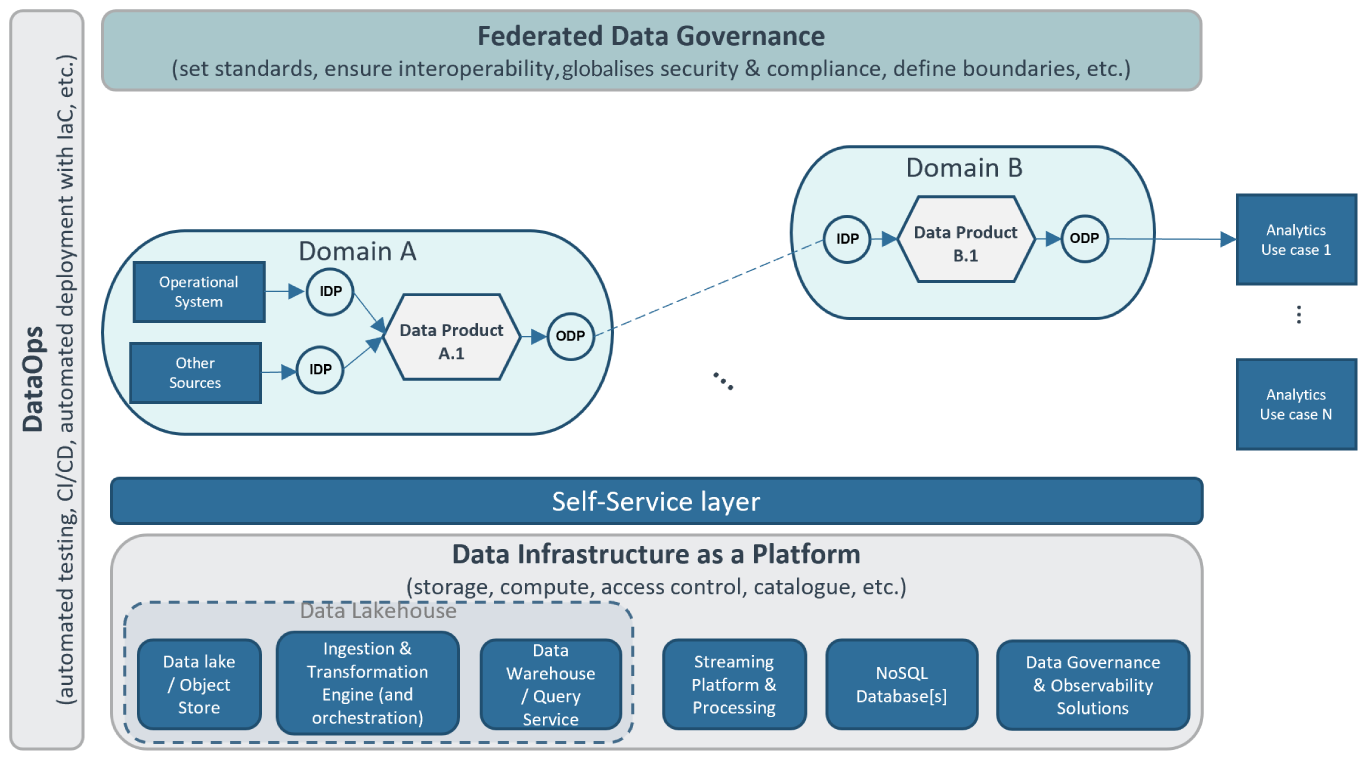
Figure 1: The fourth-generation Enterprise Data Platform reference architecture.
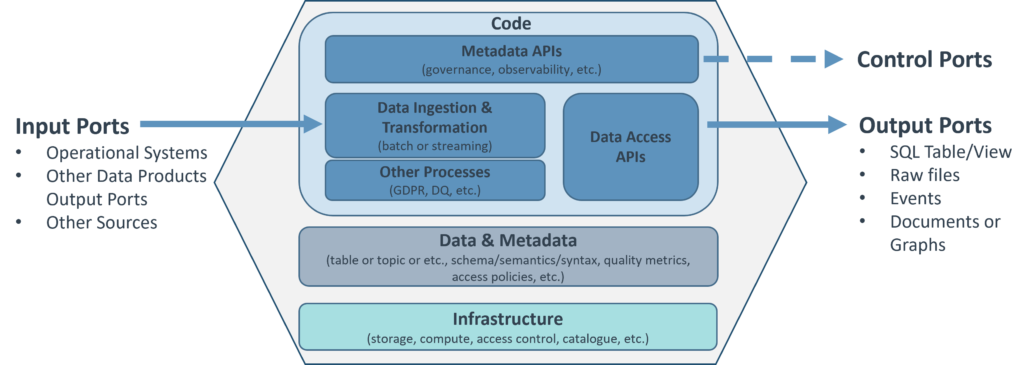
Figure 2: A data product logically contains all the data and metadata related to it, but also the code to generate and access it, and the code to fetch metadata. From a logical point of view, a data product also contains all its infrastructure, but the key idea is that such infrastructure (whose physical layer is managed by a central platform team) is accessed via the easy-to-use self-service layer.
At the core of the reference architecture depicted in Figure 1, you can see the distributed data mesh composed of domains and data products (we zoom in on a data product in Figure 2). The data mesh is built using a self-service layer on top of the data infrastructure as a platform where we find one or more data lakes or object stores; ingestion, transformation, and orchestration engines; and data warehouses and/or data querying services.
You might find all or some of the previous components unified, to a certain level, in a data lakehouse platform, but in either case you most probably need to complement them with streaming platforms for managing and processing events, as well as NoSQL databases (to handle stuff like graphs). Finally, you also need some tools or services that ease data governance (cataloguing, ownership definition, data access policy enforcement, etc.) and data observability (data quality capturing, monitoring, lineage, etc.). The goal of the self-service layer is to provide, in an easy and accessible way, the required technical capabilities from the underlying systems to the data mesh developers and users, while hiding their complexity.
On the left side of the architecture, we find DataOps, which we use for all the development efforts, including the provisioning of the various systems (using infrastructure as code), the required developments to provide the self-service capabilities, and, obviously, the creation and development of the data mesh itself, i.e., of its data products.
And above all, you find global governance, a federated team in charge of putting the data governance framework for cataloguing, setting and enforcing standards, interoperability, security and so on into place. As part of this governance framework, you also want to use DataOps (for example, for the process to create and catalogue domains and data products).
Conclusion
In this article we have discussed a few of the hottest buzzwords on the data analytics landscape, not just because they’re trending, but because if you are planning to build an Enterprise Data Platform at scale that does not suffer from traditional limitations, you should know about all these concepts in order to make a well-informed decision when architecting your next data platform – the combination of the terms we’ve discussed today can be used to pave the road to success. I would not go so far as to say it is the only road though, but at this point I hope you will agree that it is a road that makes a whole lot of sense!
Please note that while we have tried to be technology-agnostic in this blog, we have mentioned some technologies here and there – but these are just examples to help the reader get the idea. There are many technologies and tools on the market that can get you there, and maybe the tech stacks of your organisation already have tools related to the terms of today.
I hope you’ve enjoyed this blog post, and you are now in a better position to help your organisation take the next step on their data journey. If you require guidance or assistance in choosing the most suitable data platform architecture for your organisation, as well as the technologies and methodologies to implement it, please do not hesitate to contact us. We can also help you to add DataOps, data governance and data observability to your existing data platforms – you know where to find us!
