27 Mar 2024 Diving into Delta Lake
In today’s constantly evolving tech landscape, we have witnessed tremendous progress in data architectures for data management. This journey started with the structured confines of data warehousing, offering a systematic approach to organising and managing structured data, but due to the coupling of storage and compute, storage costs were high, and what’s more, you couldn’t store semi-structured or unstructured data. To overcome these limitations, the data lake was born, offering a cost-effective, scalable solution for all types of data. Nevertheless, challenges persisted in terms of reliability, consistency, and performance.
The solution to these challenges was the lakehouse, a concept presented by Databricks in their paper Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics, now broadly adopted across the industry. We have covered this concept in many of our previous blog posts and webinars, so it may well be familiar to you! In this blog post, we are going to see how Delta Lake is emerging as a key player in the lakehouse revolution.
What is Delta Lake?
Delta Lake, from Databricks, is an open-source project with a mission to address the shortcomings of traditional data lakes. It first emerged to tackle issues such as data reliability, performance optimisation, and transaction consistency, effectively becoming a cornerstone of the lakehouse concept.
Delta Lake introduces groundbreaking concepts in data lakes, incorporating ACID transactions for robustness, scalable metadata handling for efficiency, as well as compatibility with both batch and streaming data.
Delta Lake is an open format built upon standard data formats stored in any data lake solution from any cloud provider. It seamlessly integrates with the medallion architecture, improving the structure and quality of data as it flows through each layer, providing reliable, clean data for users and applications to perform analytics or machine learning.
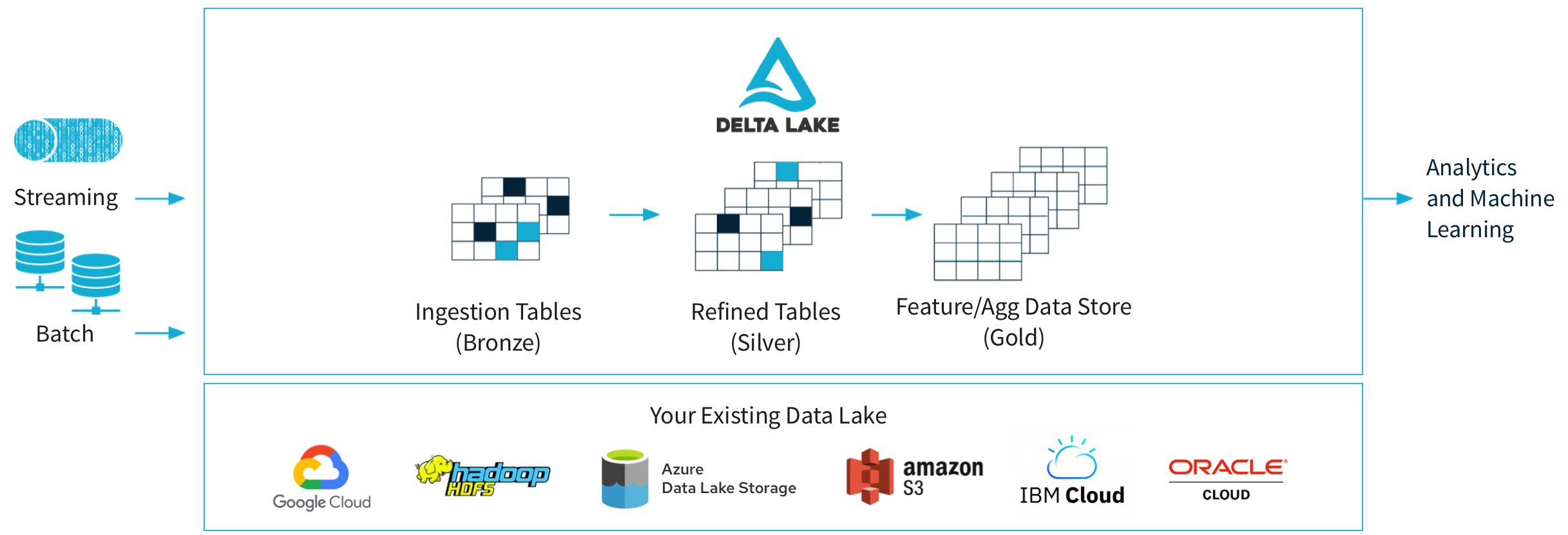
Figure 1: Delta Lake Diagram
The endorsement of Delta Lake by industry giants like Databricks, and its integration into Microsoft Fabric highlights its importance. As organisations seek solutions to enhance their data infrastructure, Delta Lake stands out as a preferred option thanks to its broad range of integrations and capabilities.

Figure 2: Delta Lake Integrations
In the following section, we’ll delve into the intricacies of Delta Lake, exploring some of the features and capabilities that make it a game-changer in the realm of data management.
Delta Lake Features
Delta Lake merges open storage formats (like Parquet) for storing structured, semi-structured, and unstructured data, with a data management layer that includes transaction logs in a folder named _delta_log, where individual commits and checkpoints are stored in JSON format. Delta Lake also supports both batch and streaming operations.
![]()
Figure 3: Databricks: Unpacking The Transaction Log
Tracking transactions allows Delta Lake to offer a wide range of features. Let’s check some of them out!
ACID Transactions
As mentioned before, Delta Lake introduces ACID transactions to the underlying open formats. This means that, unlike in formats such as Parquet, where updating or deleting specific records means rewriting the entire dataset, in Delta Lake these operations are seamlessly integrated like in a data warehouse.
UPDATE delta_table SET col = “Synvert” WHERE col IS NULL DELETE FROM delta_table WHERE col IS NULL
Besides updating and deleting, Delta Lake also enables you to perform upserts using the MERGE statement, which merges data from a source table, view, or DataFrame into a target Delta table. This operation enables inserts, updates, and deletes, automatically ensuring the source schema is compatible with the target. It compares records on both sides based on a key, and depending on the match, the following operations can be performed:
- whenMatched: Updates or deletes target data when keys match.
- whenNotMatched: Inserts source data into the target when keys don’t match (the target does not have that record).
- whenNotMatchedBySource: Updates or deletes target data when keys don’t match (the source does not have that record).
The MERGE operation is a powerful tool for performing transformations that require marking previous key values as old and adding new rows as the latest values. Such use cases are common in Silver and Gold layers, and especially in Slowly Changing Dimensions (SCD) Type 2 scenarios.
This function has seen continuous improvements since its introduction, including data skipping for matched-only records, and in Delta Lake 3.0 performance has been increased by up to 56%.
Schema Enforcement and Evolution
Schema enforcement ensures that data written to a table adheres to a predefined schema, preventing data corruption by rejecting writes that deviate from what’s specified.
When writing data to a Delta table, Delta Lake verifies the incoming data’s schema against the table’s predefined schema. By default, Delta Lake raises an error if there is a mismatch, preventing the write operation and maintaining data integrity. For instance:
# Write data to Delta Lake with initial schema
data_initial_schema = spark.createDataFrame([(1, "John"), (2, "Alice")], ["id", "name"])
data_initial_schema.write.format("delta").save("path/to/delta-table")
# Attempt to write data with a mismatched schema
data_mismatched_schema = spark.createDataFrame([(1, "John", "Male")], ["id", "name", "gender"], ["id", "name", "gender"])
data_mismatched_schema.write.format("delta").mode("append").save("path/to/delta-table")
In this example, we define a schema for the Delta table with only the “id” and “name” columns. When attempting to append data that contains an additional “gender” column, Delta Lake enforces the schema and triggers an AnalysisException error.
Schema evolution refers to the process of modifying your data’s structure over time. In a dynamic data environment, where requirements change and new data attributes need to be accommodated, a system that supports schema evolution is essential.
Delta Lake supports schema evolution when writing to a Delta Table with the mergeSchema option set to true. When you append new data to a Delta table with a modified schema, Delta Lake automatically adjusts to accommodate the changes, without requiring you to restructure the entire dataset, meaning that you can add new columns (or in some cases change the data types of existing columns) without affecting the existing data.
# Evolve the schema and append new column “gender”
data_evolved_schema = spark.createDataFrame([(3, "Bob", "Male"), (4, "Eve", "Female")], ["id", "name", "gender"])
data_evolved_schema.write.option("mergeSchema", "true").format("delta").mode("append").save("path/to/delta-table")
In this code, we evolve the schema by adding a new column, “gender”, and append data with the modified structure. Delta Lake effortlessly handles this schema evolution when the option option(“mergeSchema”, “true”) or the configuration spark.conf.set(“spark.databricks.delta.schema.autoMerge.enabled”, “true”) is enabled.
Change Data Feed (CDF)
The concept of CDF in Delta Lake refers to an improved Change Data Capture (CDC) mechanism that tracks row-level changes made to a table.
In Delta Lake CDF is not enabled by default, but it is recommended for your tables in the Silver and Gold layers, particularly when you publish changes to external tools, or for audit purposes. Basically, it is recommended whenever you need to track changes in your data.
Once enabled, any altered data resulting from UPDATE, DELETE, and MERGE operations is documented in a folder named _change_data. INSERT-only statements or full partition deletes are handled more efficiently this folder. All these changes can be queried using the table_changes SQL function.
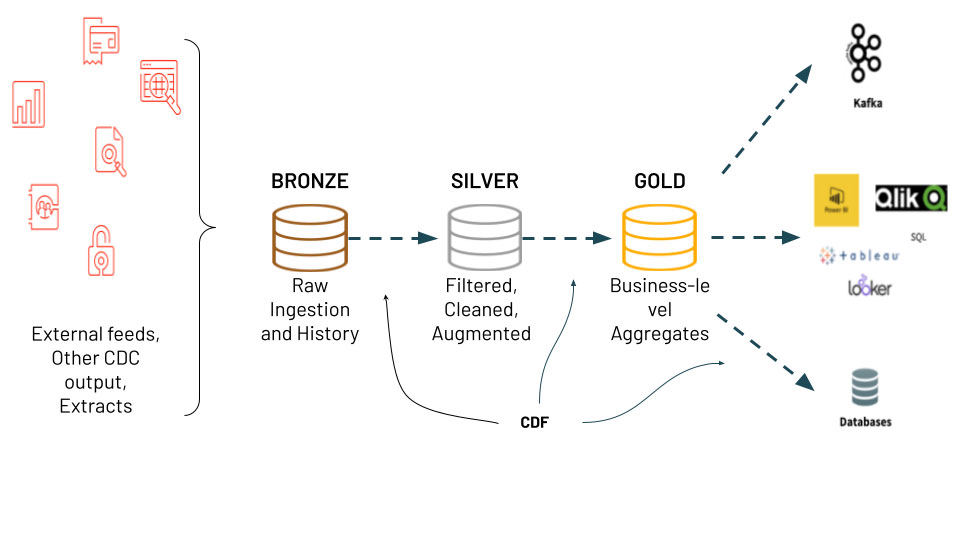
Figure 4: Databricks: CDF Diagram
Time Travel
Changing data always brings challenges such as auditing, reproducing experiments during model training, or rolling back after bad data has been stored.
Delta Lake’s time travel feature simplifies all these use cases by storing snapshots of your data at each change operation, allowing you to read or restore older versions. For example, you can read an older version by specifying the version number using this SQL statement:
SELECT * FROM delta_table VERSION AS OF 2
To rollback undesired changes, use the RESTORE command:
RESTORE TABLE delta_table TO VERSION AS OF 2
To visualise the different versions corresponding to the applied changes, use this command:
DESCRIBE HISTORY table_name
This command shows each version number, the operation executed, and additional information such as who executed it and when.
Streaming Processing
Streaming processing presents some challenges, such as balancing low latency with high throughput, a constant trade-off. What’s more, events in a stream may not always arrive in the order they were produced, and failures and crashes might lead to duplicate or missing messages.
Delta Lake supports streaming sources, enabling you to read data from streaming platforms and to write the streaming data into Delta tables. This is typically done using Apache Spark Structured Streaming, a scalable and fault-tolerant stream processing engine, which uses checkpoints to keep track of the streaming progress and to ensure fault tolerance. Moreover, its transaction log guarantees exactly-once processing, even when there are other streams or batch queries running concurrently against the table.
And finally, when reading from a Delta Lake, you can specify a version or a timestamp to determine the starting point of the streaming source without needing to process the entire table.
Optimisations (Partitioning, Compaction, Clustering)
The traditional optimisation technique to enhance queries over tables in lakehouses is data skipping with partition pruning. This is not a new concept, and it’s supported by Delta Lake. However, as this format is already efficient, it is not recommended to create partitions unless each partition is expected to contain at least 1GB of data. Furthermore, table and partition information, including maximum and minimum values for each column, is stored to automatically improve query performance through data skipping without the need for configuration.
Another common issue with partitioning is the accumulation of small files over time, especially when data is added in small batches; this can end up affecting the performance of your table. A typical way of tackling this problem is to reprocess your data with the Spark repartition function to specify the number of files you want in each partition (or across the entire table, if unpartitioned).
Delta Lake also offers the OPTIMIZE command for compaction, which effectively merges small files into larger ones, enhancing data management and access:
OPTIMIZE '/path/to/delta/table'
Along with OPTIMIZE, you can also specify Z-Ordering, a technique to collocate related information in the same set of files.
OPTIMIZE '/path/to/delta/table' ZORDER BY (column)
Z-Ordering is advisable if you expect a high-cardinality column to be commonly used in your queries.
It is worth mentioning that in Databricks Runtime 13.3 LTS and above, the introduction of the Liquid clustering feature eliminates the need for partitioning and Z-Ordering, allowing Databricks to autonomously manage all aspects of optimisation:
CREATE TABLE delta_table(col string) USING DELTA CLUSTER BY (col)
Other Features
It is impossible to cover all the Delta Lake features in this blog post given the extensive range of capabilities on offer, such as generated columns, converting Parquet files to Delta, and a wealth of utility commands to interact with and manage Delta tables, like renaming them, cloning, and removing old files with VACUUM, amongst others.
You can get more information in the Delta Lake documentation or at the Databricks Academy, where you’ll also find interesting material about Databricks itself.
Conclusion
As we close this article on Delta Lake, we invite you to explore, experiment, and integrate its cutting-edge features into your own data ecosystems. The lakehouse era is here, and Delta Lake is at the forefront, driving us towards a future where data management is not just a challenge, but a strategic advantage.
Here at ClearPeaks, we have ample experience in building and managing data platforms with lakehouse architecture, as well as with technologies like Databricks and Microsoft Fabric that leverage the Delta Lake format. Don’t miss this opportunity to transform your data strategy from a mere necessity to a competitive advantage by contacting us today and letting us guide you through the intricacies of optimising your data architecture for unparalleled efficiency, performance and results!
