03 Jan 2024 Natural Language Processing (NLP) in Dataiku – Part 1: Text Summarisation and Keyword Extraction
Natural Language Processing (NLP) is a field of AI that focuses on enabling computers to understand, interpret, and generate human language in a way that is both meaningful and useful. Now more than ever, NLP is in the spotlight thanks to the surge in popularity of Large Language Models (LLMs) such as ChatGPT.
Dataiku is a leading AI platform that simplifies the creation, deployment and management of end-to-end AI projects, empowering organisations to turn raw data into actionable insights and to make data-driven decisions. Here at ClearPeaks we use Dataiku extensively with our customers.
This blog post is the first part of a series where we will explore the powerful combination of Dataiku and NLP. Today we’ll present a straightforward, easy-to-understand, yet inspiring NLP use case that showcases the advantages of using an advanced analytics platform such as Dataiku to tackle NLP tasks in a simple, governed manner.
There are loads of potential NLP-related use cases, and in this article we’ll focus on two problems: keyword extraction and text summarisation. These tasks play a crucial role in processing and understanding large volumes of text data efficiently and effectively. In our example use case, we have built a Dataiku application that, given an input text, provides a summary and a list of keywords.

Dataiku offers a variety of NLP capabilities, either through native processing, via locally run models, or by leveraging third party APIs. For today’s specific scenario, we’ll harness the power and flexibility of the SpaCy library within a custom Python recipe in Dataiku. This approach enables us to employ SpaCy’s advanced linguistic processing and text analysis functionalities in a more customised way, allowing for greater control over the preprocessing, analysis, and extraction of insights from the textual data.
SpaCy is an open-source library and NLP framework written in Python. Designed to be fast, efficient and user-friendly, it’s a popular choice for various NLP tasks, including tokenisation, part-of-speech tagging, named entity recognition, dependency parsing, text classification, and more.
Before we delve into the application itself, let’s explore the concepts of keyword extraction and text summarisation and see how SpaCy can assist us in these areas.
Keyword Extraction
Keyword extraction involves identifying and extracting the most important and relevant words or phrases from a given text. These keywords represent the core concepts and topics present. Keyword extraction has various applications, including information retrieval, document categorisation, and content recommendation.
In our use case, we employ a frequency-based approach, which consists of identifying the keywords according to their frequency of occurrence in the text: words that appear frequently are assumed to be important. However, common words (stop words) like “and,” “the,” etc., may also appear regularly in the text but do not constitute meaningful keywords, so they need to be filtered out.
Prior to ranking the words based on their frequency, an additional filtering step is taken: SpaCy offers pre-trained language models like en_core_web_sm, which are used for text processing and tokenisation. This facilitates the identification of part-of-speech tags for each word, enabling the filtering process to retain only specific categories of interest, including nouns, adjectives, and proper nouns.
Once these steps have been completed, the frequency of each word is calculated using the Counter function.
Text Summarisation
Text summarisation is the process of condensing a longer piece of text into a shorter version while retaining the most important information and principal ideas, particularly useful to quickly understand lengthy articles, documents, and web pages. There are two main types of text summarisation:
- Extractive summarisation: The system identifies and selects the most relevant sentences or phrases directly from the original text and then combines them to form a coherent summary.
- Abstractive summarisation: This involves generating new sentences that capture the essence of the original content by using natural language generation techniques. This approach requires a deeper understanding of the text and often involves rephrasing and paraphrasing.
In our use case, we’ve harnessed the capabilities of the extractive approach using the keywords previously extracted with SpaCy. The first step consists of computing the normalised frequency for better processing, done by dividing the frequency of each keyword by the maximum frequency.
Subsequently, each sentence from the input text is assigned a weight according to the frequency of keywords it contains. Basically, sentences containing important terms that are relevant to the overall content of the text are given higher weights. To calculate the sentence score, the normalised frequencies of the keywords within the sentence are aggregated, and the sentences with higher scores will be included in the summary.
Dataiku Application
We created a Dataiku project which contains the custom Python recipe that uses SpaCy for the various NLP tasks, then packaged it into a so-called visual Dataiku application so that the developed functionality can be accessed via a simple user interface (UI) as shown below:
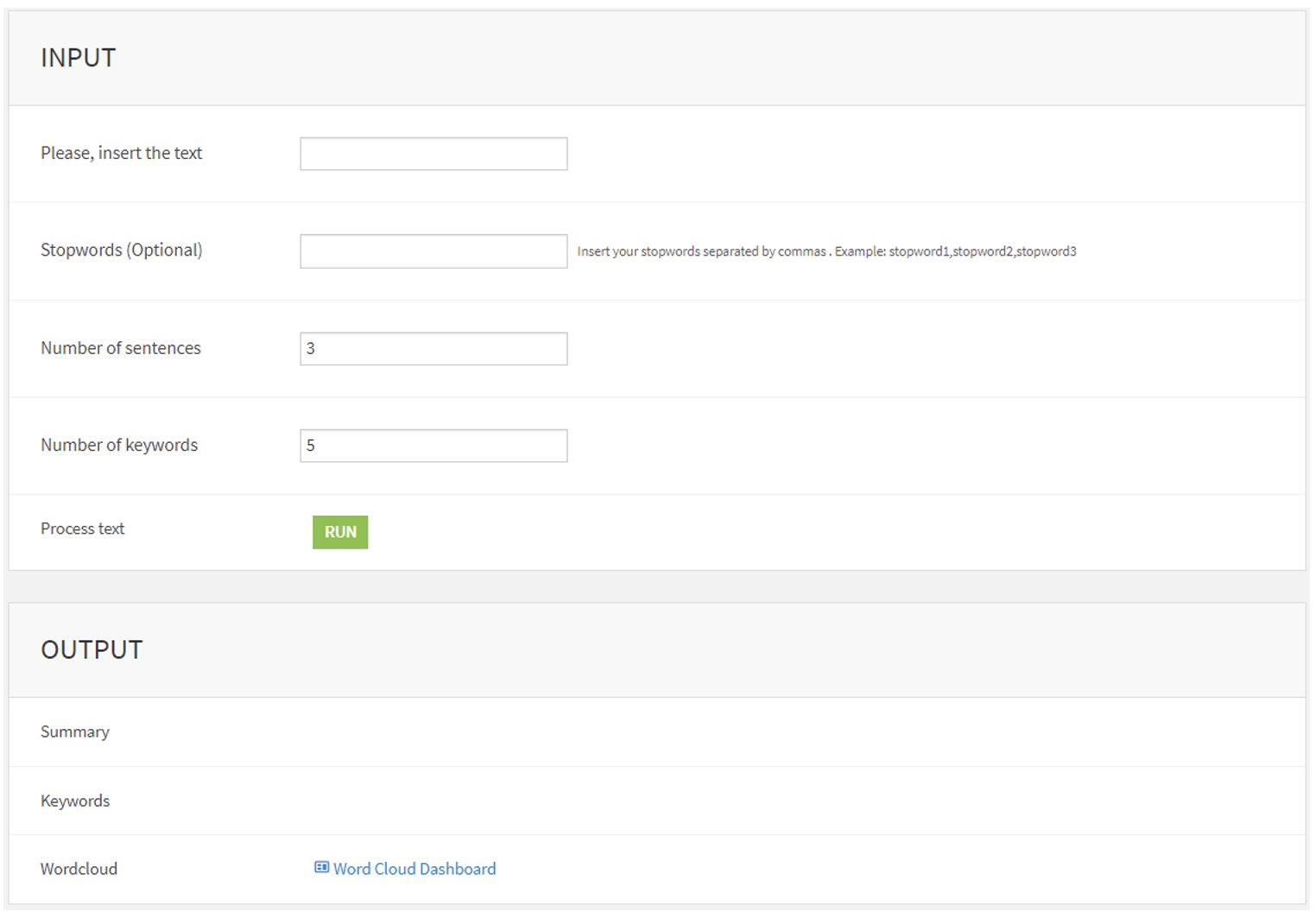
The application’s UI is divided into two sections: the input section, where the user inserts the text and adjusts the application parameters, and the output section, where the results are shown.
Input section
- Input text: The input box enables users to enter and edit the input text.
- Stop words: The SpaCy framework includes a predefined set of the most common stop words, and users can also incorporate their own custom stop words if they wish.
- Number of sentences: This parameter is used to limit the number of sentences included in the summary.
- Number of keywords: The user can specify the number of keywords they want to be displayed in the result section.
- Process text: This activates the Dataiku Data Science Studio (DSS) scenario to run the Python recipe and obtain the results.
Output section
- Summary: This tile is used to display the summary of the input text.
- Keywords: The most important words of the input text.
- Word Cloud: A link to a dashboard containing a visual representation of the keywords, where the most frequently occurring words are displayed prominently, whilst less frequent words appear in smaller fonts.
You can see an example of how the application is used below:
Application Deployment
Once the application has been built, users need to create instances of it, making it accessible and executable. An instance of a visual app refers to a particular occurrence or version of a visual app with which a user interacts. It can be thought of as a copy or a session of the visual app that is uniquely tied to that user’s inputs and actions.
When a user opens a visual app, they are essentially creating an instance of that app, and any actions they take within the app, such as uploading data, configuring settings, or generating visualisations, happen within this specific instance.
Instances of visual apps are separate from each other. If another user opens the same visual app, they will create their own instance, independent of the others. Essentially, an instance of an app represents a dynamic implementation of the app’s blueprint, whereas the app itself constitutes the underlying structure and logic that drive these instances.
User Permissions: Security Groups
Dataiku applications can be configured to allow instantiation only for users with execute permission. Assigning permissions to projects is done in the Permissions pane of the Security menu. In each project, you can configure an arbitrary number of groups with access to the application. All members of a group will inherit the group’s permissions.
Another way to acquire the execute permission for those users without any permission is to initiate an instantiation request, which they can do through a modal that will be displayed when landing on the application URL. Application administrators can manage execution requests from within the project’s security section or by handling the request in the request inbox.
Creating an App Instance
Once the user has obtained the required permissions, they can access the app URL and click on the blue “CREATE APP INSTANCE” button, in the top-right corner of the screen. After entering the instance name, a copy of the application will be created, and the user will be able to run it.
After creating the instance of the application, the user can run the app using the UI explained above.
Conclusions
This blog post is the first in a series exploring NLP within Dataiku. Today we have seen how developing a Dataiku application for NLP-based text summarisation and keyword extraction is straightforward, and how it can then significantly streamline and enhance these processes. The application we presented empowers users with the ability to upload, process, and analyse text data, generating summaries and extracting keywords with just a few clicks, and this is just one example of what Dataiku and NLP can do for your organisation!
In the next blog post we will run through another use case that we are already implementing for our customers, a document-based Q&A application that leverages LLMs. Dataiku’s intuitive interface, coupled with its powerful data processing capabilities, provides an ideal platform for creating robust and efficient NLP applications. By integrating NLP libraries and models within the Dataiku environment, users can leverage cutting-edge technologies without needing in-depth programming knowledge. As NLP continues to advance, integrating these capabilities into user-friendly platforms like Dataiku will undoubtedly play a pivotal role in driving innovation and productivity across various industries.
If you’d like to know more about what Dataiku and NLP can do for you and your business, just contact us here at ClearPeaks!
