20 Mar 2024 Building a RAG LLM Chatbot Using Cloudera Machine Learning
In recent years, Large Language Models (LLMs) have revolutionised the field of natural language processing, revealing unprecedented capabilities in understanding and generating human-like text. These models, such as GPT and BERT, have found applications across various industries, from chatbots and language translation to content generation and sentiment analysis. As the demand for more sophisticated language understanding continues to grow, the need for the efficient deployment and optimisation of LLMs becomes paramount.
This blog post demonstrates the integration of LLMs into the Cloudera Machine Learning (CML) platform, emphasising the role of Applied ML Prototypes (AMPs) in the adoption of these models. CML, known for its comprehensive support in managing end-to-end machine learning workflows, provides a robust environment for deploying and scaling LLMs to meet the demands of today’s data-intensive applications.
The launch of ChatGPT, which gained 100 million users in its first two months, sparked a huge surge in interest in LLMs, exhibiting extraordinary language generation capabilities that inspired researchers and experts to incorporate similar capabilities into their own applications, highlighting the need for efficient and scalable platforms, such as CML, to harness their full potential. As we navigate through the integration of LLMs into CML, we will also look at prevalent industry concerns and the challenges associated with deploying these models.
Key Concerns About LLM Adoption
As organisations look forward to capitalising on the opportunities presented by these LLMs, it’s equally important to appreciate their apprehensions and to tackle them to ensure a responsible and effective deployment. Let’s look at some typical concerns:
- Data Privacy and Security: The adoption of LLMs raises critical concerns about data privacy and security. As organisations leverage the power of these models to process extensive textual data, the risk of inadvertently exposing sensitive information becomes a critical concern, so it is crucial to have vigorous security measures to protect against potential breaches and adversarial attacks.
- High Operating Cost: Whilst LLMs offer unparalleled language generation capabilities, the computational resources required for training these models raise environmental concerns and mean high operational costs. Balancing the advantages of LLM adoption with their environmental impact and associated expenses becomes a necessity for organisations aiming to embrace these advanced models.
- Transparency and Explainability: The black-box nature of LLMs presents challenges in terms of transparency and explainability, so their adoption requires accountability and trust. Similarly, the risk of perpetuating biases present in training data demands a proactive approach to address concerns. Achieving a balance between the complexity of the model and its interpretability is essential for its responsible adoption.
- Missing Business Context: There’s a significant risk of neglecting the importance of business context: adopting these models without a clear understanding of industry-specific complexities or company-specific jargon may lead to less than perfect results. It’s crucial to customise LLMs to the unique needs of each business sector and to keep them updated with changing circumstances to fully leverage their potential in real-world scenarios.
The Cloudera Solution
Cloudera Machine Learning is an enterprise data science platform covering the end-to-end machine learning workflow, enabling fully isolated and containerised workloads – including Python, R, and Spark on Kubernetes – for scalable data engineering and machine learning, with seamless distributed dependency management. A deep dive into CML can be found in this previous blog post.
In response to the concerns mentioned above, last year Cloudera introduced an Applied Machine Learning Prototype (AMP) titled “LLM Chatbot Augmented with Enterprise Data”. This AMP demonstrates how to enhance a chatbot application by integrating it with an enterprise knowledge base, ensuring context awareness whilst allowing public and private deployment, even in air-gapped environments. What’s more, the entire solution is built on 100% open-source technology, providing a secure and transparent approach to incorporating LLMs into enterprise workflows.
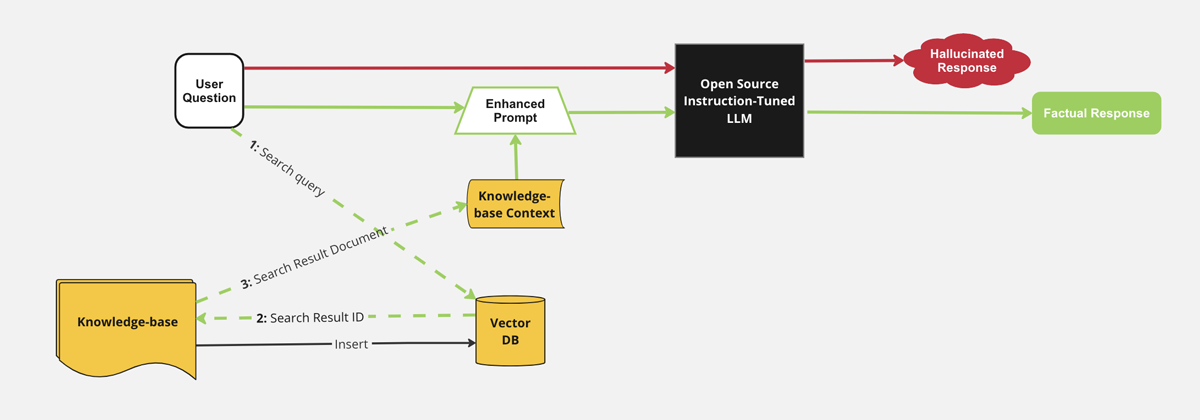
(Source: CML_AMP_LLM_Chatbot_Augmented_with_Enterprise_Data)
Our Approach
In this section, we’ll delve into a practical implementation of an LLM chatbot using the Cloudera AMP in CML. Our goal is to use an open-source pre-trained instruction-following LLM to build a chatbot-like web application. LLM responses are enriched by contextual information obtained from an internal knowledge base, enabled by semantic search facilitated by an open-source vector database.
When a user question is sent directly to the open-source LLM, there is a greater risk of hallucinated responses due to the generic dataset the LLM was trained on. By enriching the user input with context retrieved from a knowledge base, the LLM can more readily generate a response with factual content. This is a form of Retrieval Augmented Generation (RAG). The RAG architecture can be understood like this:
- Ingesting the knowledge base into the vector database –
- Generating embeddings (vector representations of words, phrases, or documents that capture their meaning and relationships in such a way that similar words or documents have similar numerical representations) with an open source pretrained model for each data file containing contextual information, then storing these embeddings, along with document IDs, in a vector database to enable semantic search.
- Augmenting the user question with additional context from the knowledge base –
- For any given question, the process involves searching the vector database for the documents that are semantically closest based on their embeddings, and then retrieving context based on document IDs and embeddings returned in the search response.
- Submitting an enhanced prompt to the LLM to generate a factual response –
- Creating a prompt that includes the retrieved context and the user question, then returning the response generated by the LLM to the web application.
All the components of this application (the knowledge base, context retrieval, prompt enhancement, and LLM) are running within CML and do not call any external model APIs; neither does the LLM require any additional training.
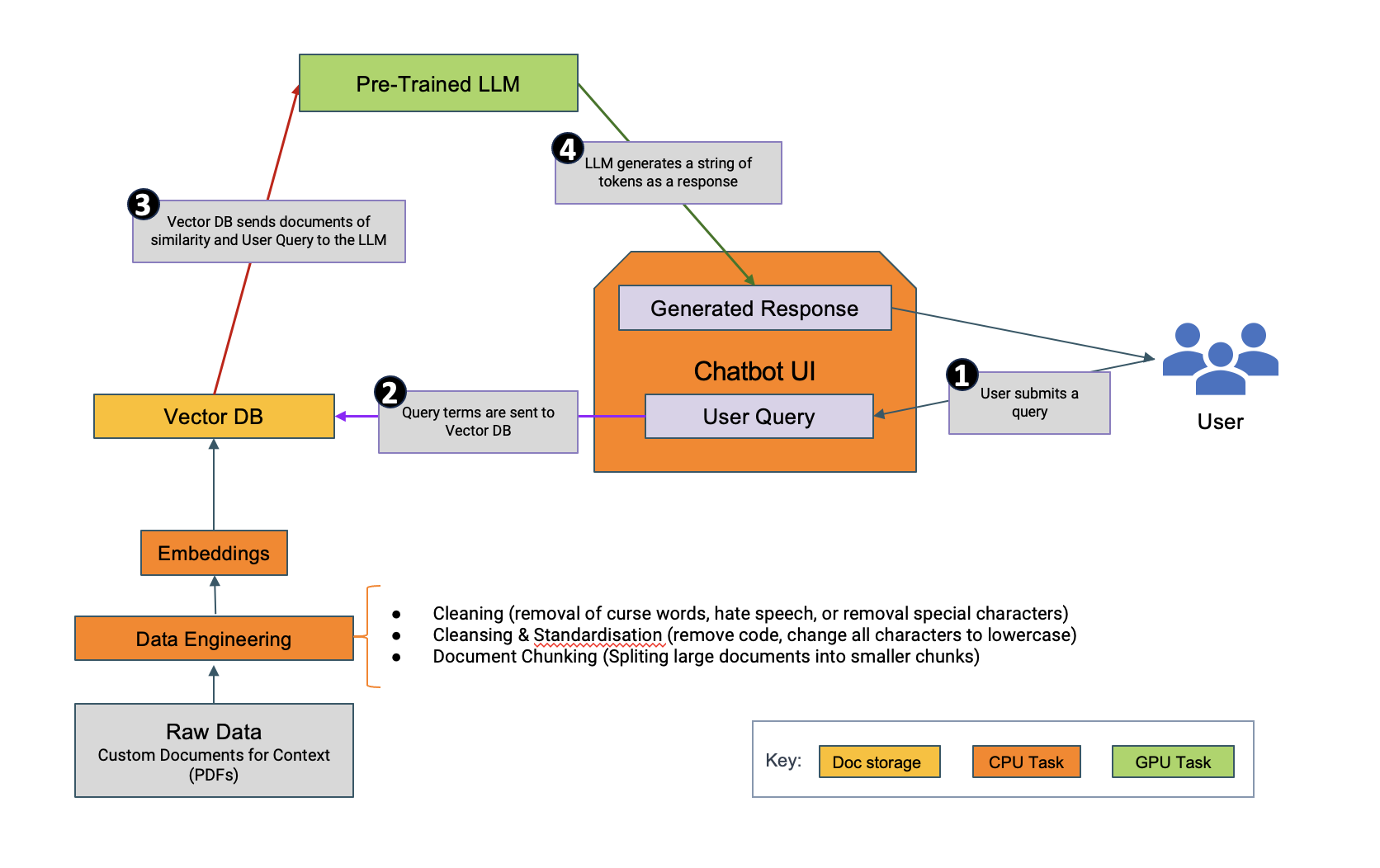
The setup shown above offers an advantage in terms of complete control. However, it’s important to note that for certain use cases, there may be instances where using external vector databases makes more sense. With CML, the user has the flexibility to maintain a closed environment while also being able to outsource certain components to external systems. This allows easy adaptation to diverse scenarios and additional performance demands.
Challenges Encountered and Solutions Explored
Parallel Processing on Multiple GPUs
During the implementation, one major challenge was to optimise the chatbot for parallel processing across multiple GPUs. CML’s support for distributed computing proved instrumental in addressing this challenge, and we configured AMPs to distribute the workload efficiently, significantly improving the model’s inference speed.
Document Parsing for Large Documents
For the sake of this article and to demonstrate the capabilities of CML, we built a simple application that worked with large documents, including ClearPeaks blog posts, market reports, and research reports. However, using such large documents posed another challenge, particularly in the context of embeddings and response generation. LLMs, constrained by context length limitations, have trouble with documents exceeding 15 pages, so we designed a custom parsing function, dividing documents into smaller chunks and extracting headings for embedding generation.
Technology Stack
Here are the components we used for this simple application:
Cloud Hardware | Azure VM (2 vCPUs, 2 GPUs) | |
|---|---|---|
Vector Embeddings Generation Model | ||
Vector Database | ||
Large Language Model | h2ogpt-oig-oasst1-512-6.9b | |
Chatbot UI |
Please note that, as mentioned above, CML can interact with these and other technologies, allowing you to fully customise the components for your application: just pick the ones that are best for you! Do reach out to us if you need help deciding.
Chatbot Performance
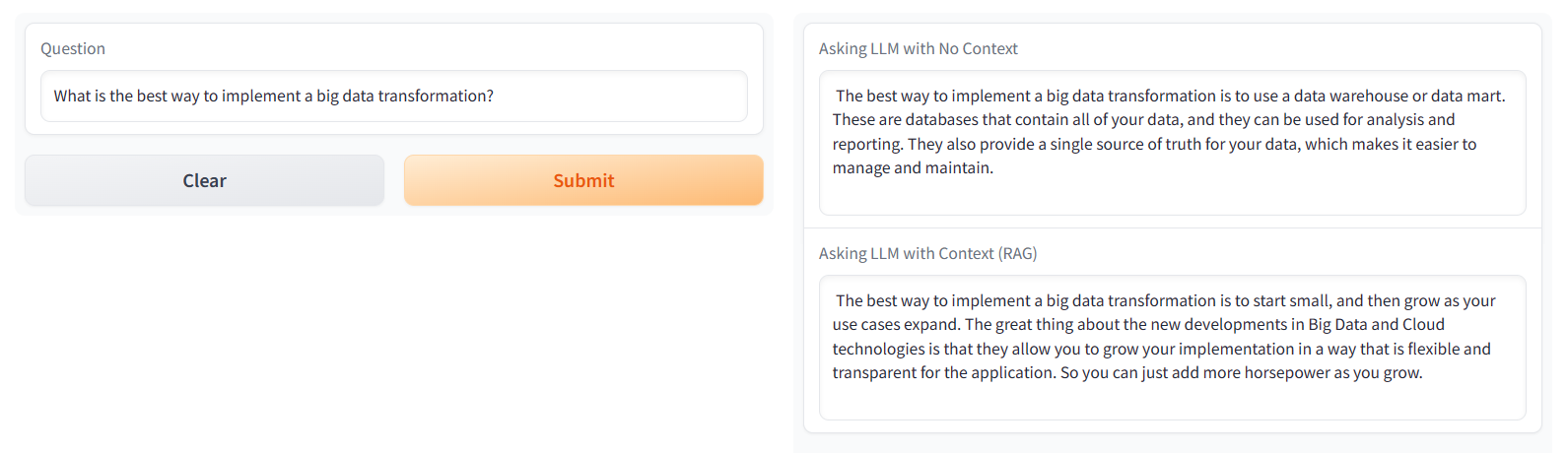
Our application demonstrates the effect of employing RAG by generating two distinct responses. Firstly, the chatbot queries the LLM directly to produce a response, whereas the second approach conducts a semantic search within our vector database, which is augmented with contextual information. This ensures that the response is contextually influenced, highlighting RAG’s ability to enhance both the quality and relevance of responses.
To illustrate the point, here’s an example of two responses to the same question. The first is a directly generated response without any additional context, whereas for the second, the application referenced information from a custom document (a ClearPeaks blog post) to answer:
Chatbot-in-action example: responses generated (with and without context) by referencing a ClearPeaks blog post
Extract from a ClearPeaks blog post referenced by the chatbot to generate the response in Example 2

(Source: Why Big Data Transformations Fail – And What You Can Do To Succeed – ClearPeaks Blog)
Conclusion
In this blog post we’ve demonstrated the use of Cloudera Machine Learning as the backbone for LLM implementations within the Cloudera stack. CML seamlessly integrates with various open-source technologies, offering a user-friendly interface for deploying advanced solutions whilst guaranteeing total data security. Its versatility is evident as it effortlessly addresses various challenges, making complex tasks more accessible to users.
The practical implementation of an LLM chatbot within CML, as outlined in this blog post, provides a solution-driven approach that addresses industry concerns: the emphasis on responsible AI is evident in the AMP’s focus on data security, transparency, and context. By incorporating open-source technology and leveraging CML’s capabilities, we’ve been able to showcase our commitment to providing a secure, contextually aware, and scalable LLM deployment for our customers.
We hope you’ve enjoyed reading this ClearPeaks blog post, and remember, if you’re interested in similar solutions for your company or organisation, our consultants are here for you – just contact us!
