31 May 2023 Creating a Chatbot Based on ChatGPT for Interacting with Databases
In this article we are going to explore how ChatGPT (and similar models) can be used to interact with databases, showing how these tools can be used to improve productivity in this field by allowing quick prototyping and analysis, and even as an aide to learning.
The first step is to prepare a testing data warehouse with a non-privacy sensitive data model. To do so, we will use this sample database, which is a mock-up of a fake bike store with different brands, employees, products, etc. Our objective is to build an interface that allows us to interact with our data model, and for the prototype we will use a simple Flask webserver that implements a chatroom.
We asked ChatGPT to create the chat interface for us by providing an HTML file and its accompanying CSS code; we will show you what this website looks like later on.
In this article we’re going to run through three main tasks:
- Run SQL queries generated by ChatGPT, based only on the DB schema and the user request, expressed in natural language.
- Perform general Q&A about the data model, asking how different elements are structured or asking how to incorporate new developments.
- Generate diagrams that give visual explanations of whatever the user is asking about.
As we are going to perform different tasks, we’ll need a method to differentiate between user request types. Let’s call ChatGPT again, to ask which mode the question requires with the following prompt, then parsing the output:
Given the following request, and the provided cases, tell us which case best fits the request:
REQUEST: “Insert Request”
CASE 1: “Requests written explanation of something, no image was requested.”
CASE 2: “Explicitly requests an image or diagram.”
CASE 3: “Requests a SQL query to execute it.”
Example answers are:
“1”
“2”
“3”
Give no explanation, only a singular number.
Now we can simply evaluate the output and treat the request differently, depending on what the user is asking for.
Querying the Database with Natural Language
Let’s start with our SQL queries. The idea here is for the user to be able to query data from the database without needing any knowledge about exactly how the database is structured, or how the SQL language works.
In order to do this, we’re going to use a tool called LlamaIndex, which, amongst other things, enables the transformation of sentences into SQL queries once given access to the database.
It does so by inserting the database schema and user request into the following query:

After sending the prompt to OpenAI’s text-davinci-003, a predecessor to ChatGPT’s GPT-3.5-Turbo, the tool retrieves the SQL query, which is executed, and the resulting outcomes are returned to the user.
Here are a few results for different requests, run on our example database:



This last one is particularly interesting: the database contains a lot more brands than those shown here, but the ones that don’t appear are those without stock in the store. This shows us that it’s able to do a lot more than just look up the brands table and return its content.
If we ask it to return all the brands in the database, it returns the full list:

So far, so good! Nevertheless, this doesn’t mean that it’s infallible, and one thing that this system relies on heavily is the proper naming of the tables and columns. Of course, if confusing language is used when constructing and describing the tables then it will get things wrong, and this is why we strongly recommend giving systems like this permission to read data, but not to modify it. One wrong statement and the entire database can go up in flames!
Please note that the results of the SQL queries are not sent to OpenAI; they can only see our data model schema in order to construct the query.
General Q&A About the Database Structure
Next, we’re going to use ChatGPT to ask general questions about how the database is structured so that the user can ask how different tables are related, as well as request explanations on how specific things work.
The first one is simple; we will put the database schema and user request into the following prompt:
Given the following SQL schema:
‘SCHEMA’
Answer the following request with a bullet point explanation:
‘REQUEST’
It looks simple enough, but nevertheless allows us to ask a range of different questions.
The user can also ask about what the database is, how it’s structured, and how different tables are related to each other:
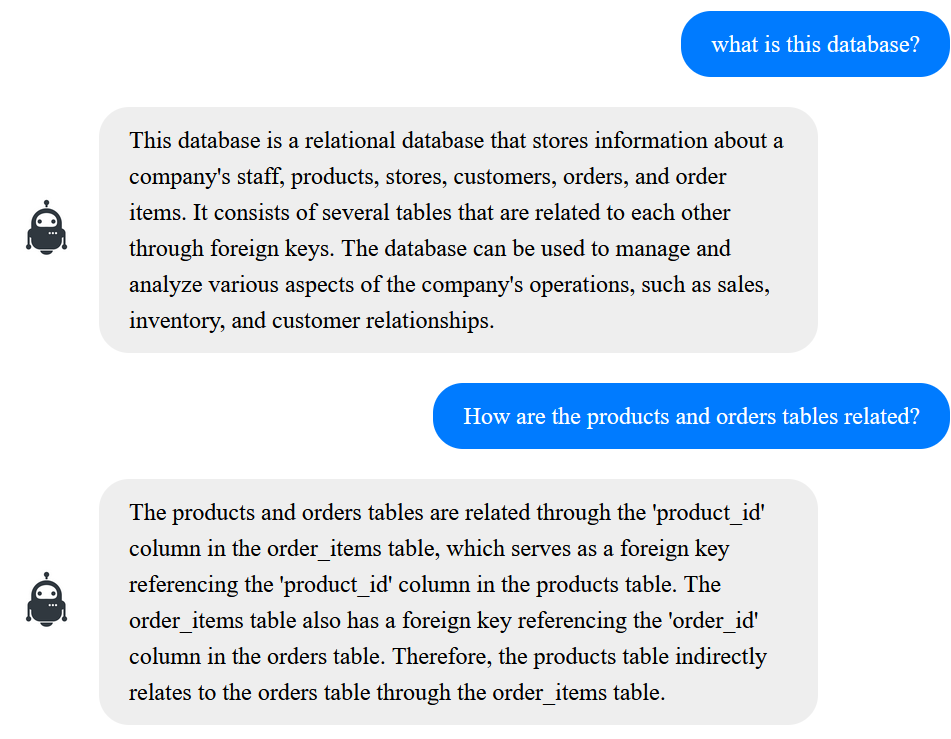
Asking how to create SQL queries to carry out specific tasks could be very useful for learning and speeding up work:

This offers the added advantage of allowing the user to review the query manually before executing it, unlike earlier when it ran the SQL query directly.
The utility of this Q&A functionality really depends on what it’s being used for. In our example of the bike store it might seem a bit superfluous, given the simplicity of the database, but for complex databases with a large number of tables, views and procedures, it could be very handy to clear up confusion and to speed up tasks without having to look through the entire schema to see what needs to be done.
Image Generation
In this task, our objective is to take the request and use it to generate a diagram that explains what the user is inquiring about visually.
For example, if the user wants to ask how two tables are related in a database, the output would be something like this:
![]()
In order to achieve this, we will ask ChatGPT to generate a DOT script for Graphviz, an open-source graph visualisation library. The idea is to extract the script from the prompt answer and pass it on to Graphviz, which generates the image and returns it to the user.
The prompt we decided on goes as follows:
“Given the following SQL schema:
‘SCHEMA’
and the following request:
‘text’
Create a DOT script for graphviz that will generate a diagram in response to the request. All relations need to be labelled.
Here is an example request and its response:
‘EXAMPLE REQUEST’
‘EXAMPLE RESPONSE’
A good thing about the way ChatGPT generates code is that it always places it inside a markdown code block, marked with three inverted commas: “` CODE “`
This makes it extremely easy to parse, as we only have to cut out everything between the commas.
Here are a few results:
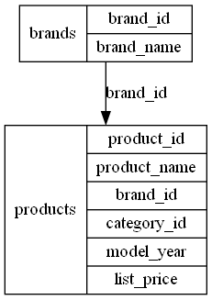
Request: “Give me a diagram of the relation between the brands and products tables”
Output:
Request: “Give me a diagram of the relation between the “order_items” and “categories” tables”
Output:
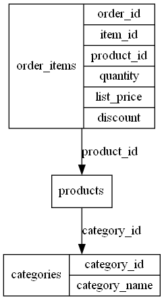
Note that there is no direct relation between the two tables, and ChatGPT can bridge them using the products table.
Request: “Give me a diagram of the entire database and the relations between the tables”
Output:
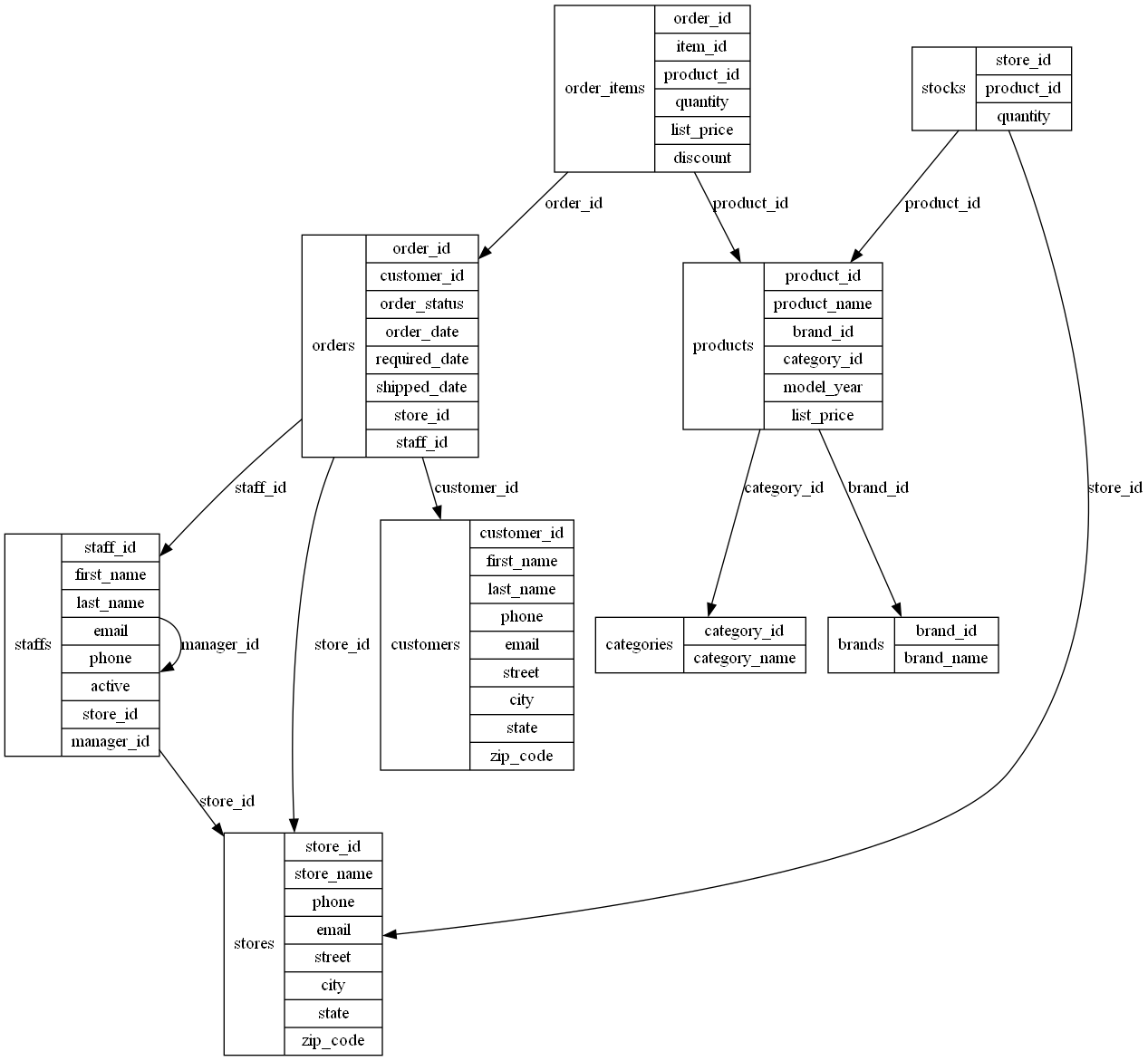
One thing to note is that the orientation of these arrows is not always correct. If you compare diagram 1 with diagram 3, you can see that the first one has the relation between products and brands backwards.
Having said that, these are still very good results: ChatGPT is able to generate a graph showing exactly what the user is asking about.
Apart from the database use case, this could easily be used to generate any kind of graph or flowchart. Just to give an example, here’s what it comes up with when asked to explain the Watergate scandal as a diagram:
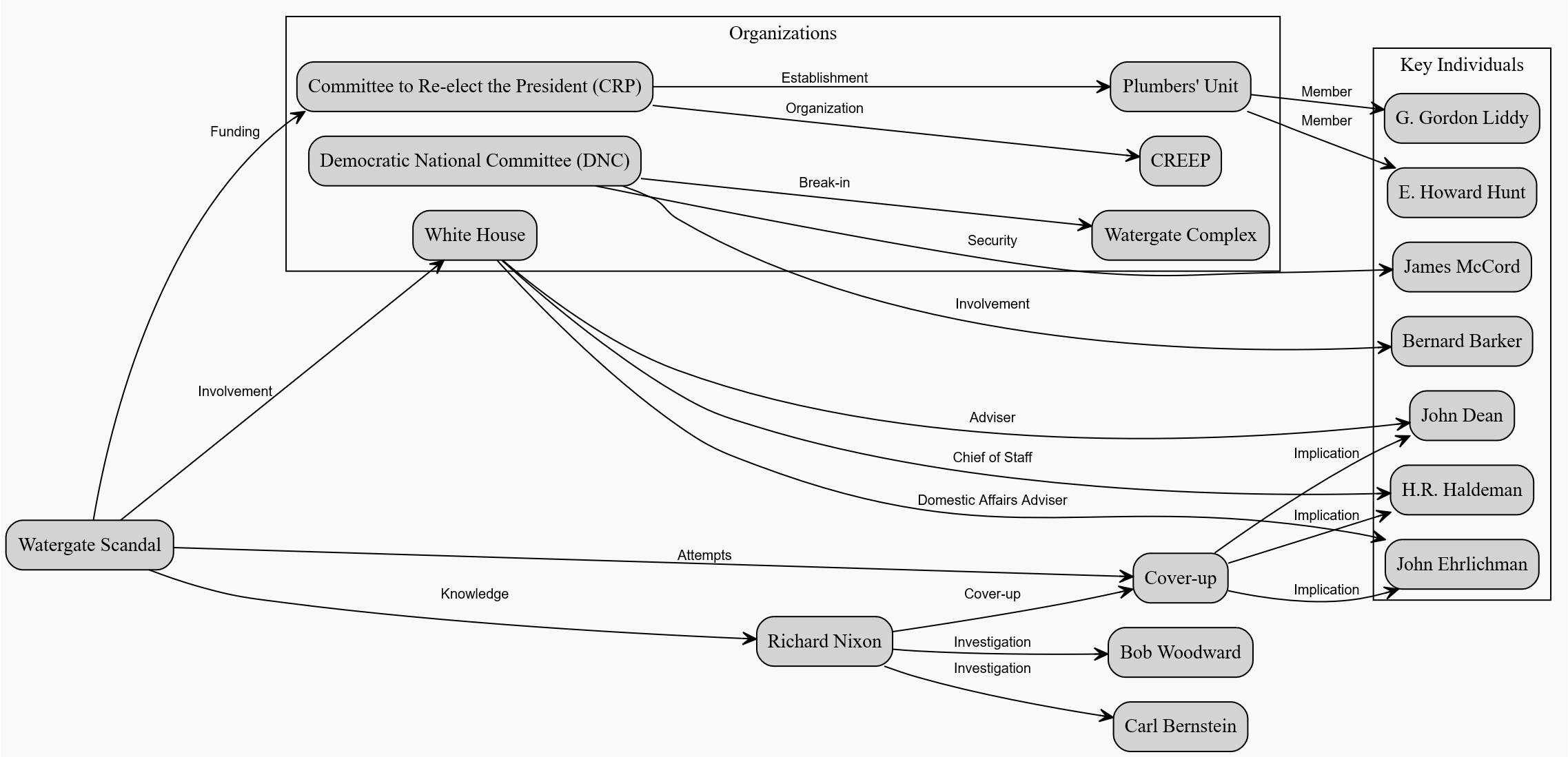
Like the previous examples, this is very useful for learning and exploring, providing the ability to break down complex topics into easy-to-understand diagrams in seconds.
In-Context Learning
As you might have noticed, we always include example inputs and outputs in our prompts. This is what’s known as “in-context learning” and it’s extremely useful for forcing ChatGPT to give its output in a particular format.
In the diagram generation task which we showed you a moment ago, one big problem we experienced was that approximately 50% of the time, ChatGPT appeared to be under the impression that it couldn’t generate DOT script, giving the following answer instead:
“Sorry, as an AI language model, I don’t have the capability to create visual diagrams or generate code.”
However, we all know that it is more than capable of generating code. Here, since the script is used to generate an image, the model gets confused and defaults to the error message saying it can’t create images.
The solution was to provide an example output, a DOT script of a simple diagram, and the problem was (mostly) fixed:
“Given the following SQL schema: ‘SCHEMA’ and the following request: ‘REQUEST’ Create a DOT script for graphviz that will generate a diagram in response to the request. All relations need to be labelled.
Here is an example response:
digraph G {
node [shape=record];
brands [label=”brands | {brand_id | brand_name}”];
products [label=”products | {product_id | product_name | brand_id | category_id | model_year | list_price}”];
brands -> products [label=”brand_id”];
categories [label=”categories | {category_id | category_name}”];
products -> categories [label=”category_id”];
}“
Now it only gives the error message about 5% of the time, which is a great improvement and allows us to get the script without too much trouble. It also helps to avoid unnecessary text: for example, in the task selection prompt, it often gave a long-winded explanation as to why it chose this specific task, which would take much too much time to be generated. Giving a few example outputs, essentially “1” “2” “3”, solved this issue.
Conclusion
Like in every article we write on ChatGPT, we need to remind the public of the importance of privacy with these types of tools. OpenAI can and does store a lot of the prompts it receives from its users for later use in training. Just recently, Samsung employees got in hot water for accidentally leaking trade secrets and source code when asking ChatGPT for help in summarising meetings and fixing bugs.
Using prompts, we have demonstrated that the usage of Large Language Models (LLMs) that aren’t running locally will reveal the internal structure of your database, and you need to decide whether or not this is acceptable to you.
In any case, we hope this article has shown how LLMs can be used to make interaction with databases easier and learning more accessible.
If you’re interested in how these cutting-edge technologies can drive your business forward with the appropriate security measures in place, don’t hesitate to contact us and one of our team of experts will get straight back to you!
