30 May 2016 Customizing ODI Knowledge Modules
Lately we have seen a growing interest in ODI (Oracle Data Integrator). We have been working with this tool here in ClearPeaks for a while now, on several projects for different verticals, but it is also true that with the appearance of the newer versions of Oracle Business Intelligence Applications (OBI Apps) 11.1.1.X, it’s a pretty hot topic, and that’s why we’ve decided it was time to publish a quick “tips and tricks” guide for ODI, hoping to save our customers a lot of effort, time, and money.
The first thing to bear in mind when you start working with ODI is that you really must follow best practices in order to take full advantage of two of the most powerful weapons in the ODI arsenal: the declarative design and the knowledge modules. For those of you that don’t have too much experience with ODI, let me run through these two outstanding features.
The declarative design basically allows you to create an abstraction layer between the developer and the actual code that is going to be performed by the DBMS. This means that in ODI you define “what you want to get”, and the way to do so is automatically implemented by the Knowledge Module.
However, you might ask yourself “Is this possible? Can we really rely on the default ODI KMs?” Well, the answer is very simple: for standard needs, where performance is not a problem, yes! But in most of our BI projects, remember that we have had to tune the KMs to adapt them to our customers’ needs and to obtain the maximum benefit from the tool.
But don’t think that this undermines what is a fantastic feature. ODI comes with a great set of KMs that give you the perfect starting point to create your own customized KM. And moreover, all the developers don’t need to go into the details of the KM implementation; in a typical ODI project, the architect will be responsible for setting up the ODI environment and will provide the whole team with the appropriate KMs that will satisfy the particular project needs.
So in principle, the developers don’t need to know all the implementation details (it is up to each user/developer to go beyond and analyze the code ODI is generating, if required). This abstraction significantly speeds up the process of developing an ETL, since once the logic is established, there is no need to redo it over and over again.
A typical example to consider is the logic necessary to load a Slowly Changing Dimension (SCD Type II). With other tools, each developer would need to fully understand the logic of the SCDs and the way the integration process is performed, since it has to be replicated for each table to be loaded.
With the ODI declarative design, you just establish what you want, and the KM will take care of the logic. So you simply need to indicate:
➜ I want to treat “Table X” as a Slowly Changing Dimension (we will mark it like this).
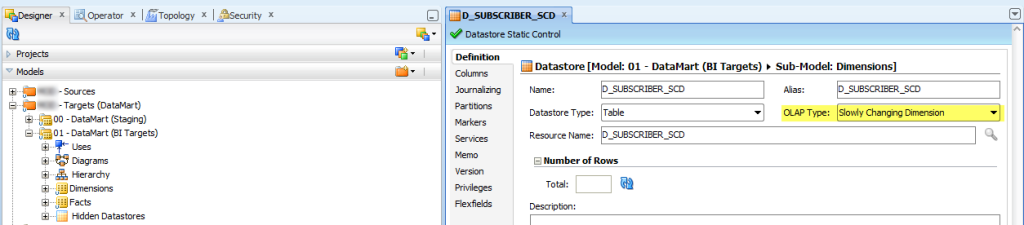
➜ I want to use “Column X” and “Column Y” to store the starting and ending date of the row, respectively.

➜ I want to use “Column Z” as the current row flag.

➜ I want “Column A” to be the Primary Key (Surrogate Key) of “Table X”.
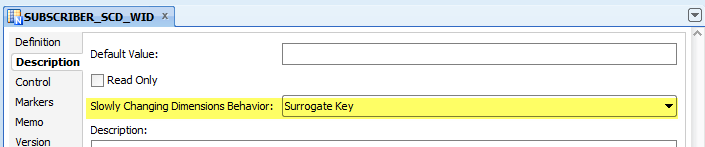
➜ And I want this column / set of columns (e.g. B and C) to be the Integration Key (Natural Key) of Table X (the column, or columns, that will be used to determine if the row is a new row, or if the row previously existed and has to be updated).

➜ Finally, we can indicate for each column if we want the ETL to add a new row when the value changes in the source system, or if we prefer to update the whole table.

✓ And that’s it! By then selecting the appropriate KM, tuned with the necessary logic by our architect, we can develop as many mappings as we want for Slowly Changing Dimensions. Just indicate the source for each column and run it. Quick and easy!
We have also mentioned the concept of Knowledge Modules. So, some of you may wonder, what is a “Knowledge Module”? This is simply a generic set of steps that will perform the needed logic for your ETL process. Each step can be written in different languages (SQL, Oracle-SQL, Jython, and many more) depending on the technology underneath, with placeholders for each column, table, and in general, “entity” that will take part in our ETL. At execution time, those placeholders are filled with the details of the mappings that have been developed, and this gives the project team the flexibility to reuse logic and speed up the delivery of the ETL process.
Well, that’s enough of an introduction to these two handy features in ODI. Now let’s see some usage examples of the things that can be done, and which can help our customers to reduce implementation time.
1. Automatizing Loads
Automatizing the Incremental / Full Load Strategy
There are several ways to automatize an Incremental / Full Load Strategy using KMs. If we think back to the previous version of OBI Apps, in Informatica we had to have two separate mappings for the Incremental and the Full version of the mapping. With ODI this can be automatized in several ways:
ⓐ Manually: Adding an option to the mapping
The simplest way is to add an option to the mapping so we manually specify if we want to execute a full load or not. This option will drive the execution of a new step in our KM. For example, this step may consist in truncating the table, and if we are populating a dimension, resetting the associated sequence.Here we see the importance of following best practices and naming conventions. If we follow a good methodology when naming our DWH objects, we can distinguish the table type by the name, and also the sequences can be easily related to the corresponding dimension.
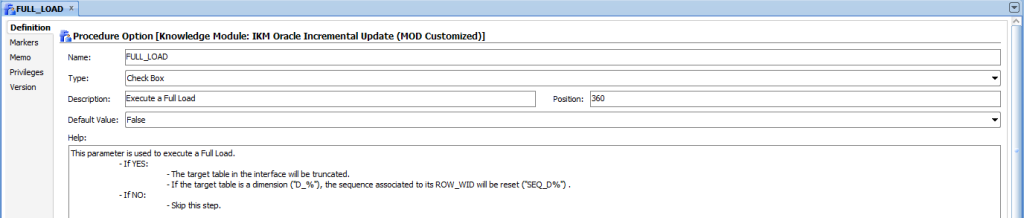
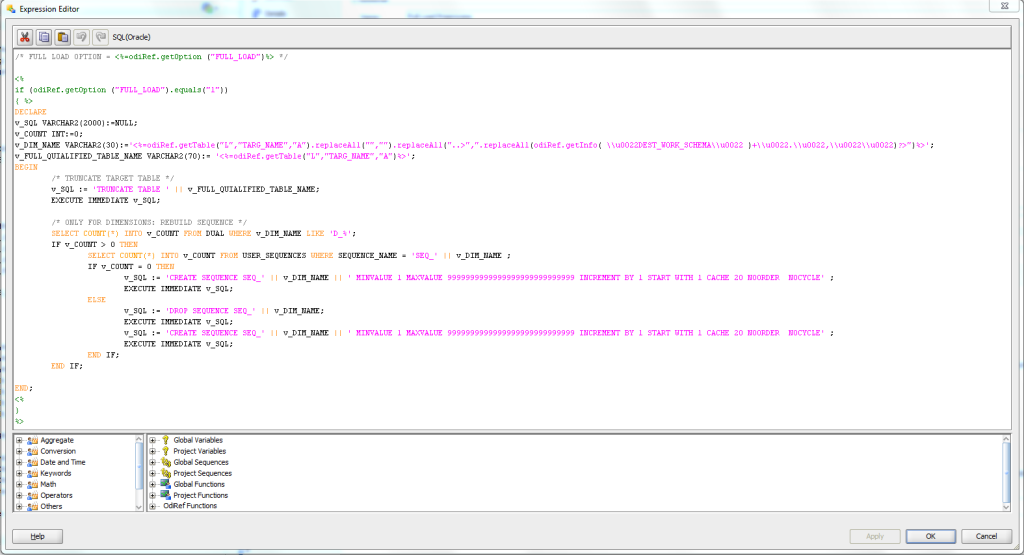
ⓑ Automatically: Adding an option to the mapping and using a control table
The second option is an extension of the previous one. By using a control table containing the table name and one column containing the “FULL_LOAD_FLAG”, we can invoke this process only if the DWH administrator has set the property in the table (FULL_LOAD_FLAG = 1). This way, there is no need to modify any ODI object to change the behavior of the interface.
Automatizing the population of the unspecified rows for dimensions
A typical need in any data warehousing project is to populate an “unspecified” row for each dimension. This will give us the capability of always making inner joins between the facts and dimensions, and thus improve performance in all our OLAP queries.
Once again, we could generate a separate interface for this, for each dimension, but will it be efficient? ODI gives us the possibility of defining a generic step in our KM to be executed for any dimension table to be loaded.
At execution time, ODI is aware of the data type of each column to be populated (remember that every object is stored in the model, and so we have an internal representation stored in the ODI repository). We can prepare a simple process that will basically assign a default value for each data type. For example:

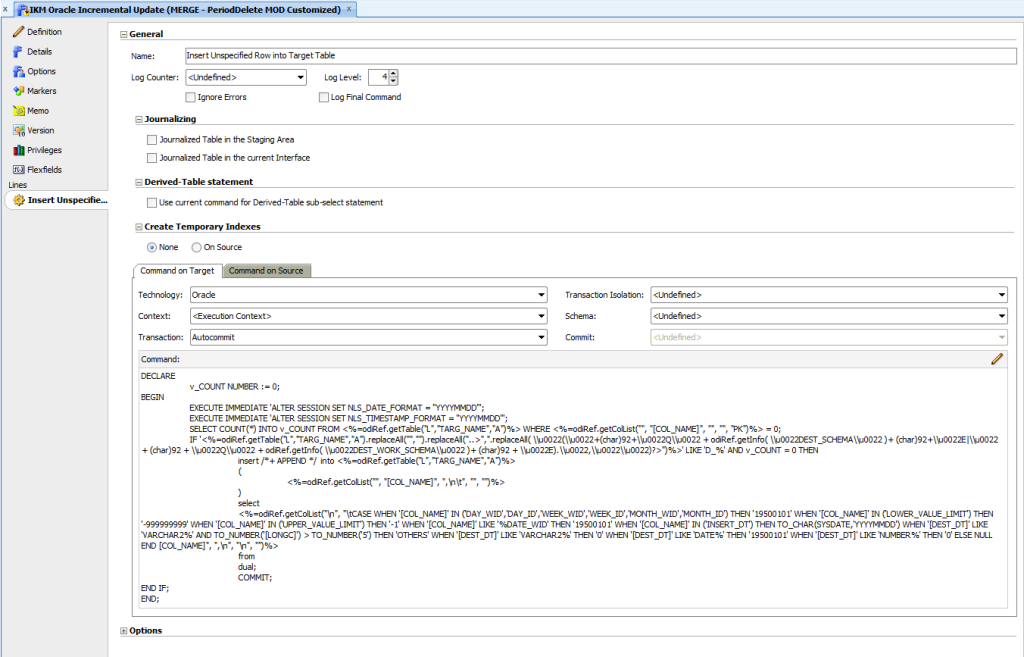
NOTE: See the ODI Substitution API Reference to learn more about the functions you can use to retrieve useful information from the ODI model, or contact us for further details!
Automatizing the population of Fact Modules by using a control table
Another interesting functionality we usually include in our projects is control of the periods to be loaded by a control table. As we mentioned before, with this table we can change the behaviour of our ETL process just by changing one row in one table. This speeds the process of programming and administering the loads up a lot.
By using this table, the ETL administrator is capable of specifying the starting date that we need to populate, and the number of periods to be loaded. More options can be useful in this table, like a flag (PREV_EXEC_CORRECT_FLG) indicating if the automated previous execution of the ETL was correct (if not the ETL should not continue in order to avoid inconsistencies, for example, in Slowly Changing Dimensions). Another flag might be used to indicate if the population of this table should be included in the automated process (IS_PART_OF_DAILY_LOAD), or the FULL_LOAD_FLAG that we already mentioned.
In the example below, the source system needed to be queried daily due to performance restrictions; by specifying a starting date and the number of periods to be loaded, the ETL automatically ran a loop for the number of days to be loaded by leveraging the ODI variables.

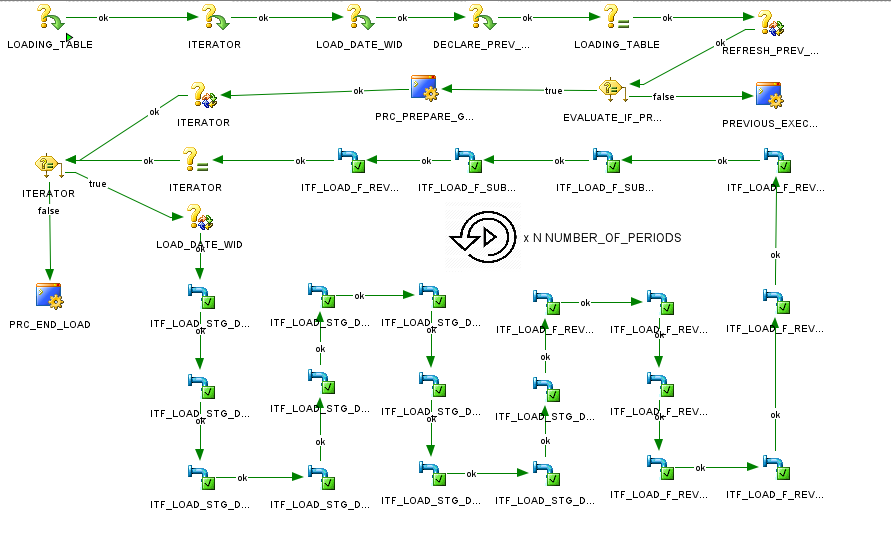
In this case, it is also important to highlight that the interfaces have to be filtered by a variable containing the value of the day to be populated:
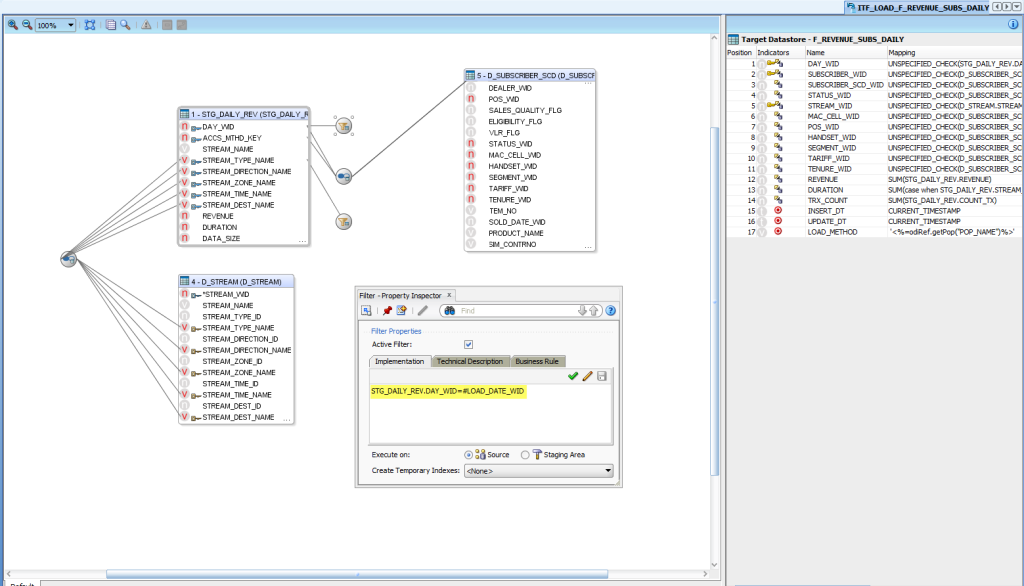
Another interesting modification done to the KMs involved in this case study is that of the corresponding CKM to add an option that will avoid deleting the previous errors, since the same session is going to be executed several times in a loop.

In some cases, it might even be interesting to remove the period from the target table before inserting, if we are performing a full period insertion (we don’t want to merge the data with the previously inserted data, but to directly reload a complete period).
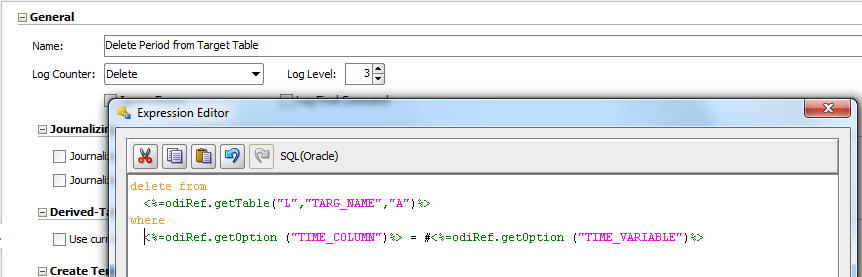
As you can see above, by using the ODI functions we can generate generic steps that will work for any object in our ODI model. For example, <%=odiRef.getTable(“L”,”TARG_NAME”,”A”)%> will retrieve the target table name.
See: http://docs.oracle.com/cd/E21764_01/integrate.1111/e12645/odiref_reference.htm#ODIKD1295
2. Boosting performance
Boosting performance for populating staging tables
Since ODI 11g does not have a multi-target capability, we sometimes need to reuse the same staging table to populate several final targets; we have to load these staging tables as fast as possible to speed up the performance of the whole ETL process. We can use the default KMs to load these staging tables, but for one staging table you may not need to apply integration processes, validations checks and other time-consuming logic; to get round this, a good practice is to generate your own staging KM, including only the necessary steps:
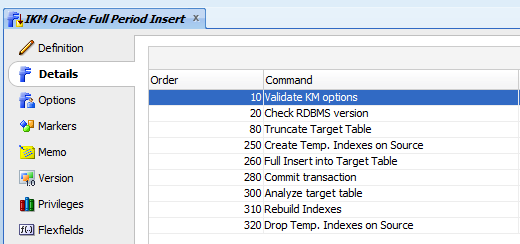
Then, in the “Insert” step, you can populate the target table directly, instead of the integration table:
<%=ODIREF.GETTABLE(“L”,”TARG_NAME”,”A”)%>
VS
<%=ODIREF.GETTABLE(“L”,”INT_NAME”,”W”)%>
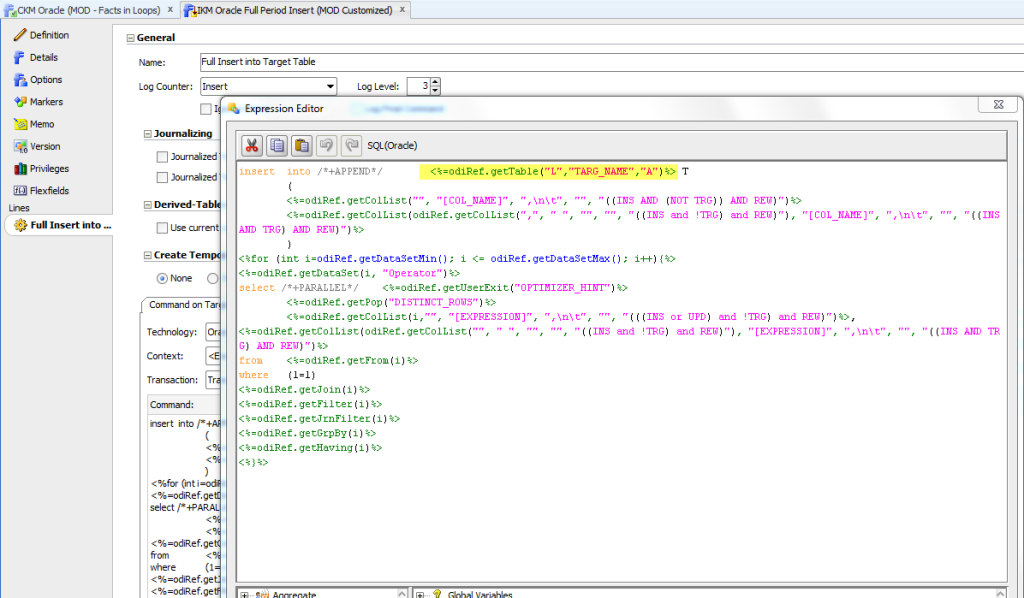
Boosting performance by using partition exchange
In order to boost performance of load processes and reporting as well, it is sometimes useful to apply partitioning to your DWH tables. This will give you two main advantages:
➀ At ETL time, the population of a big table (GBs of data) is much faster if the table is partitioned, since you can populate a temporary empty table, and then execute a partition exchange to swap the partitions between both tables. This way, all the population in your temporary table, the consistency checks, constraints and all the processes you may need to do can be done much faster.
It is important to emphasize that this is useful for snapshot tables, and in general for tables that do not need to cross data between partitions.
➁ At reporting time, if you just need to analyze one partition (one period) at a time, or maybe two to compare them, the response time in a partitioned table will be faster.
To accomplish the partition exchange in ODI, you can also use a knowledge module that can encapsulate the logic needed. The command below will execute the partition exchange between the temporary table and the target table, leveraging ODI functions.
ALTER TABLE
<%=ODIREF.GETTARGETTABLE( “SCHEMA” )%>.<%=ODIREF.GETTARGETTABLE(“RES_NAME”)%>
EXCHANGE PARTITION ‘ || V_PARTITION_NAME || ‘ WITH TABLE
<%=ODIREF.GETTABLE(“L”, “INT_NAME”,”W”)%>
<$=”<%=ODIREF.GETUSEREXIT(“PARTITION EXCHANGE OPTIONS”)%>”$>
Note that the variable V_PARTITION_NAME will need to contain the name of the partition to be exchanged. This can be retrieved by a simple query on the temporary table that your mapping has populated.
➀ Loading historical information into a Slowly Changing Dimension
The last interesting modification that we are going to show you is to the Oracle SCD KM. Imagine that you launch your system with a starting date (e.g. 30 Sept., 2014) and after some months running your ETL system in production, the source system is updated with historical information so that the business can analyze trends and customer behavior over several years. Obviously, we can’t load the latest information in the source system to our DWH because it will override the current information with this stale but still relevant information. We need to look for a way to include this information in our system, so if a user queries information about old periods, they can analyze and explore the attributes the customer had at that point in time.
Well, we can do the following:
➀ Duplicate the mapping you are using to load your SCD.
➁ Duplicate the Slowly Changing Dimension IKM you are using to populate your SCDs.
➂ Modify the copy of your IKM to set the “ACTIVE_TO_DATE” to the date when you launched your system.
This way you can run a separate load for older periods without impacting the daily load you are running on a daily basis with current data. Any row loaded by this second thread (older periods), will always finish by the date when you launched your system, so there won’t be duplicates in your SCD and you can explore both current and old information about the entities in your dimension (e.g. your customer profile, segment, location, etc.).
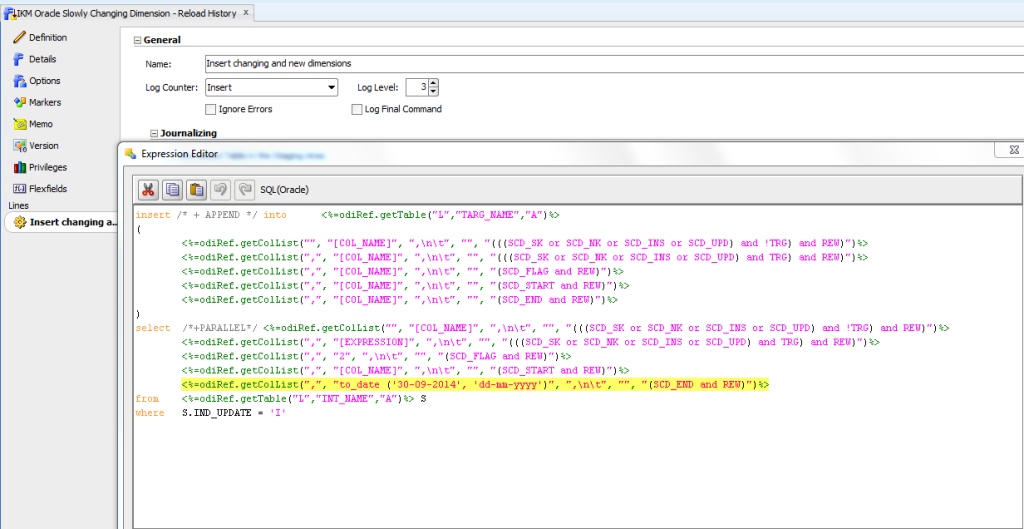
Just by modifying small pieces of the given KM code, you can achieve your particular needs. Just be careful that you modify the appropriate properties (in this case, SCD_END and also the SCD_FLAG have to have different values from those in your daily thread).
We hope that you’ve found these techniques that can be applied to ODI KMs to speed up the process of generating and manipulating your ETL interesting, and if you have further questions, do not hesitate to contact us.
Stay tuned for more interesting features to apply to your ETL processes with #ODI!!
Get in touch with us and see what we can do for you! ✉