11 Aug 2023 Different Use Cases to Copy Data in Azure Data Factory
Let´s kick off with that typical situation where we need to ingest data from a source database to a destination data lake.
Azure Data Factory is the flagship service when it comes to data integration. Out of all the available activities used in the development of our ETLs, Copy Activity is the most popular one, and recently Azure Data Factory released some new features to cover more complex scenarios.

So, what happens in those use cases that require the movement of a massive number of files, or when we are working with different load types like incremental or total data transfers? These are common considerations during the development of our ETLs, and the Copy Activity can either be limited or require the development of a lot of code that will later complicate maintenance.
Let´s take a look at the tools that are available to overcome the drawbacks mentioned above, and offer a brief overview of the features, strengths, and weaknesses of each of the options we examine.
We hope that this blog post will help you to choose the best solution for your own particular needs!
Scenario 1
Use cases: For those basic scenarios that require the mobilisation of a file, the copying of data from a table to a file or the loading of data from a file to a table, we can use the traditional Copy Activity. This is the simplest option, as you only have to provide the source data set and the destination data set, each linked to their respective data services, enabling seamless connectivity.
It is important to remember that using this solution offers the possibility of executing queries on our copied data. This setup enables incremental loads by storing the last entry copied in a variable.
Moreover, it offers the flexibility of using parameters in our variables, both at pipeline level and at activity level, which allows us, for example, to save a new field and specify the time of its execution or completion. There are endless possibilities in terms of programming these parameters, which is what makes this tool so useful.
Scenario 2
Use cases: For a scenario where the requirement is to move a considerable number of tables, we can implement the Copy Data using dynamic variables. This setup optimises the code and eliminates the need for numerous individual Copy Activity tasks, each tied to a specific data source. Instead, we can utilise a more generic dataset that points to the DB link, providing flexibility in handling multiple tables. Here, it is important to emphasise that the source must be unique.
On the other hand, to avoid hardcoding the names of tables or files directly into the pipeline, we can adopt a more flexible approach by creating a list of parameters. These parameters can be saved in a blob, which acts as a container to hold the names of the tables or files we want to move, and by doing so we ensure that future modifications to the pipeline can easily be accommodated without needing to alter the pipeline itself.
In order to implement this solution, we must first evolve the basic Copy Data activity.
- The first step is to retrieve the list of tables that need to be ingested, either by using a Lookup activity pointing to the file with the parameter list, or by attaching a variable with our tables as its value.
- Secondly, a ForEach activity will iterate over the Copy Data activity for each ingested table. This iterative process, driven by the received variables and dynamic parameters, will enable us to specify the destination for each individual file or table being moved.
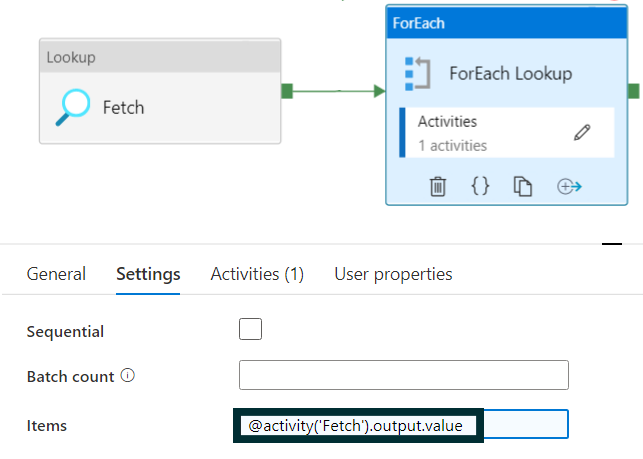
This solution is great as long as we do not need to make any distinction between the forms of data movement, since because it´s a single activity it does not allow us to individually configure a query for each of these origins and/or destinations.
Scenario 3
Use cases: A complex scenario in which it is necessary to copy multiple tables from a single source database to another database or a data lake, whilst being able to choose between a full or incremental load for each of those tables.
For this type of scenario we suggest using the Copy Metadata tool that allows the loading of several tables from the same database. For each of the tables, we can choose to follow an incremental or a total load approach. The tool relies on a watermark to keep track of the load state. Please note that the system from which data is ingested has to be a database.
For the tool to run successfully, a couple of elements have to be created: a stored procedure and a control table where the watermark is stored. These two elements can be created in any relational database available on your platform, and we suggest you store them in your data warehouse.
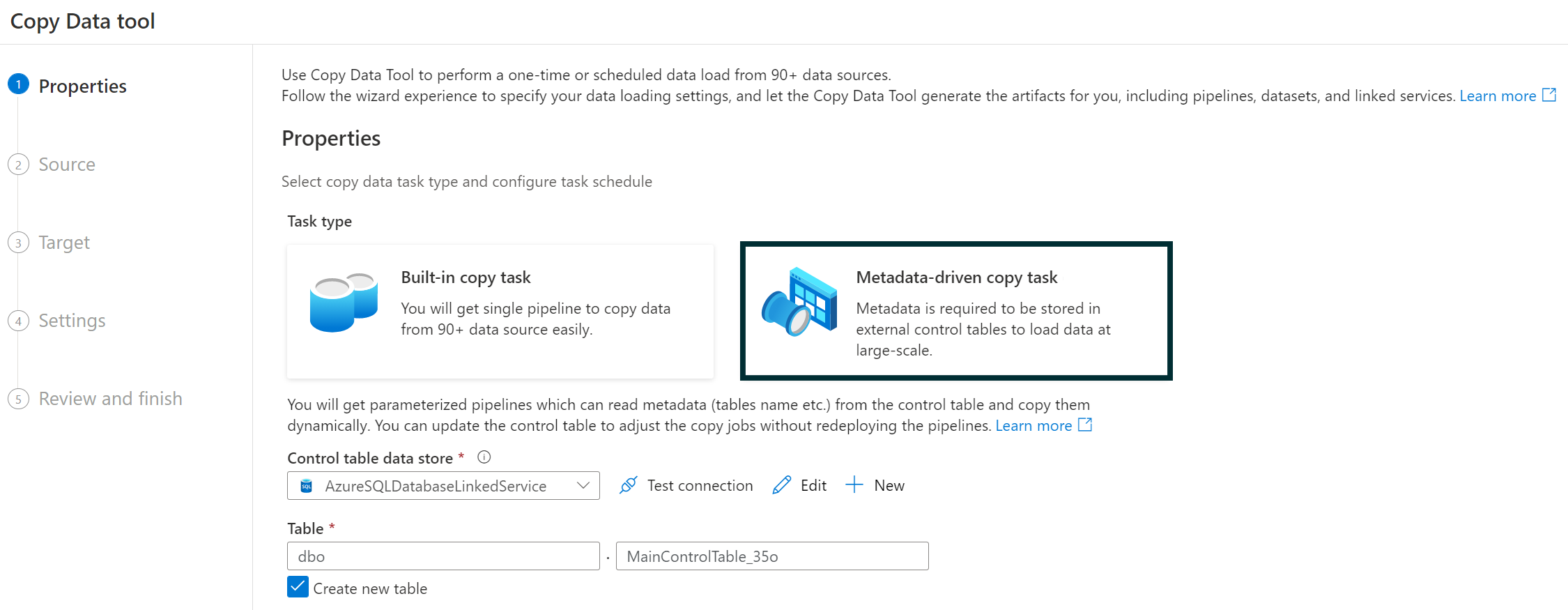
Azure provides a visual wizard that helps us to create and to set up the Copy Metadata activity. During the process we will have to indicate the source database, the destination of the data, and where the control table will be stored. The wizard will then generate two scripts, one that creates the control table and a second to create the store procedure. We have to execute these two scripts on the chosen database. Finally, the wizard lets us verify the success of the setup.
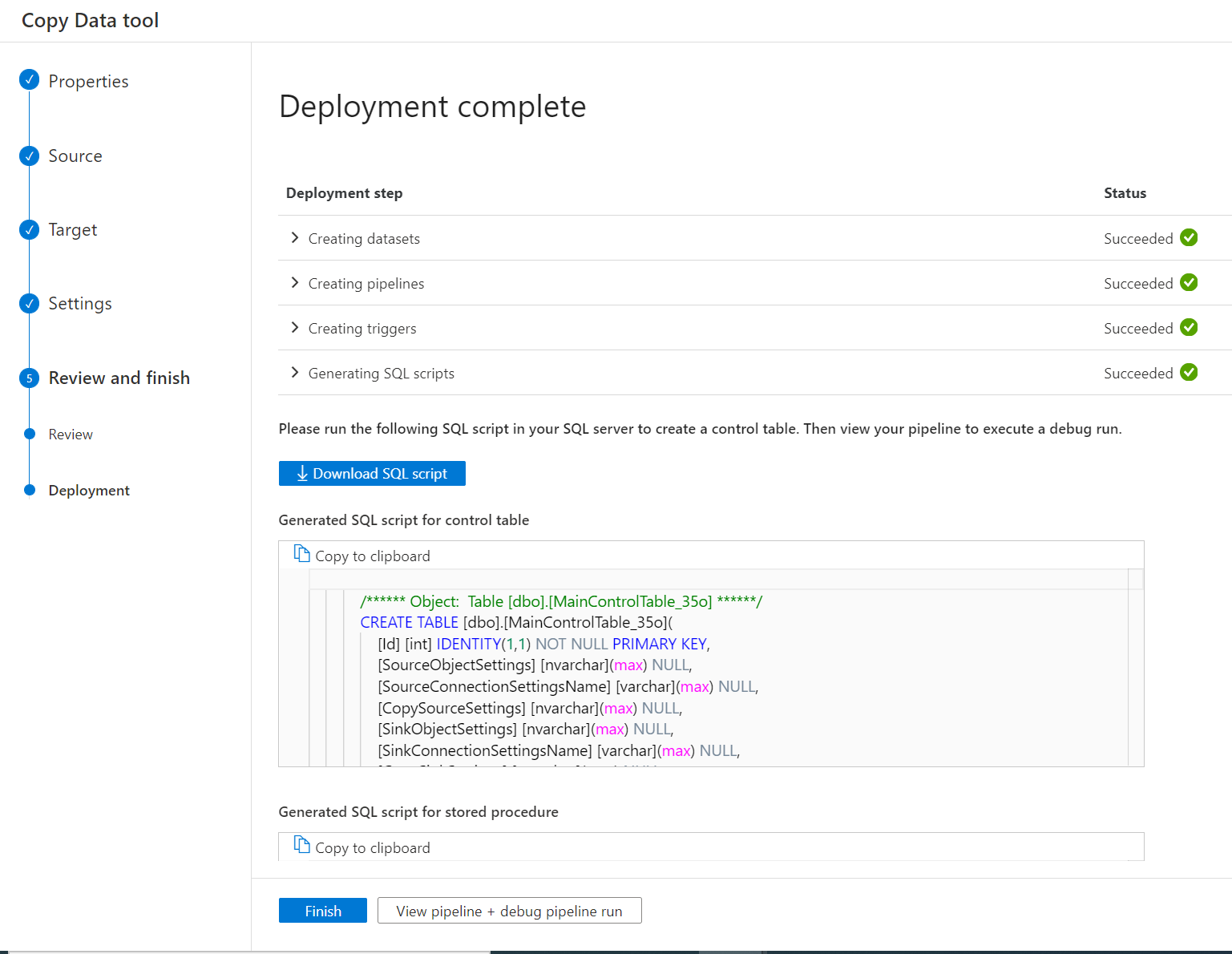
If your setup is more complex than the one generated by the wizard, you can manually tune the scripts to adapt them to your needs. You can find an example of how to do it in this blog post.
Wrapping Up
In this blog post, we have examined three options to ingest data using Azure’s flagship data integration service, Data Factory. Since Azure is always releasing new features and tools, stay tuned for new options that will allow us to optimise our pipelines!
We hope this article will help you to choose the best setup for your project. Don’t hesitate to contact us if you have any queries about Azure Data Factory, or if you want to start building your data platform with our team of experts. We will help you to set up your environment smoothly and in a cost-efficient manner!
