
06 Jul 2023 Exploring ChatGPT Alternatives for Organisations with Privacy Concerns
Large Language Models (LLMs), especially ChatGPT, are by far the hottest thing on today’s AI landscape, and here at ClearPeaks we have recently shown you a few examples of their potential applications in business organisations. In our first blog post on the topic, we used ChatGPT for topic modelling and customer feedback analysis, in the second we created a chatbot based on ChatGPT to interact with databases, and in the third we used ChatGPT to structure and index unstructured PDF files. However, many organisations don’t want to use LLMs to process and interact with their data due to their privacy concerns.
Sending potentially sensitive information to a third party is something that understandably unnerves a lot of people. The use of LLM prompts for re-training purposes has caused a lot of problems in the past, and even though OpenAI has promised not to store chats for future use if the user opts out, many companies like Apple, Amazon, and Verizon have still decided to heavily restrict LLM use, even after this announcement.
Our case is no exception: as a consulting company, we take the utmost care to protect our customers’ data, so using external APIs is a no-go (unless the customer understands and accepts the associated risks). This means that if we want to make use of LLMs we need to have them running on premise, so that the data never has to leave the site and is never at risk.
So, today we will evaluate how publicly available LLMs compare with commercial-grade solutions like those OpenAI provides, basing ourselves on the use cases we showcased in the previously mentioned articles.
We are going to use GPT4ALL, an open-source ChatGPT alternative that allows you to load and run different public models locally on modest servers or even PCs and laptops, and more importantly, to run them on the CPU. This is important because a GPU running a language model needs excessive amounts of VRAM, and provisioning a GPU machine with such specs on the cloud is still expensive and a lot of use cases do not need the latency provided.
We are going to use Vicuna-13B, the model that performed the best in our testing at the time of writing, without consuming too much memory.
(Please note that the licence on this particular model does not allow for commercial use, so we will just be using it for testing purposes. However, it is only a matter of time before similar models are released for commercial use – there’s a new model almost every week!).
Topic Modelling Use Case
The first article we published was about topic modelling on negative customer reviews, essentially summing up all the complaints into simple graphs that offer an instant overview of what the main problems with your product are.
One of the tasks we performed was topic extraction: we gave ChatGPT the reviews and asked it to extract the main complaints, 2 to 3 words for each, which we then aggregated into a graph (the article contains more details on how this works).
We tried using Vicuna-13B instead of ChatGPT for the topic extraction, and our first findings show that the local language model struggles a bit with sentiment analysis, sometimes categorising positive remarks as if they were negative:
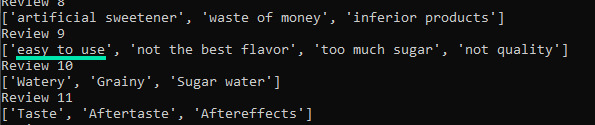
This led to some innocuous comments being labelled as complaints when they weren’t; however, this wasn’t a big problem and it didn’t affect the final result.
Here are the two graphs we generated from the same customer reviews of a hot chocolate product, using the two different language models:
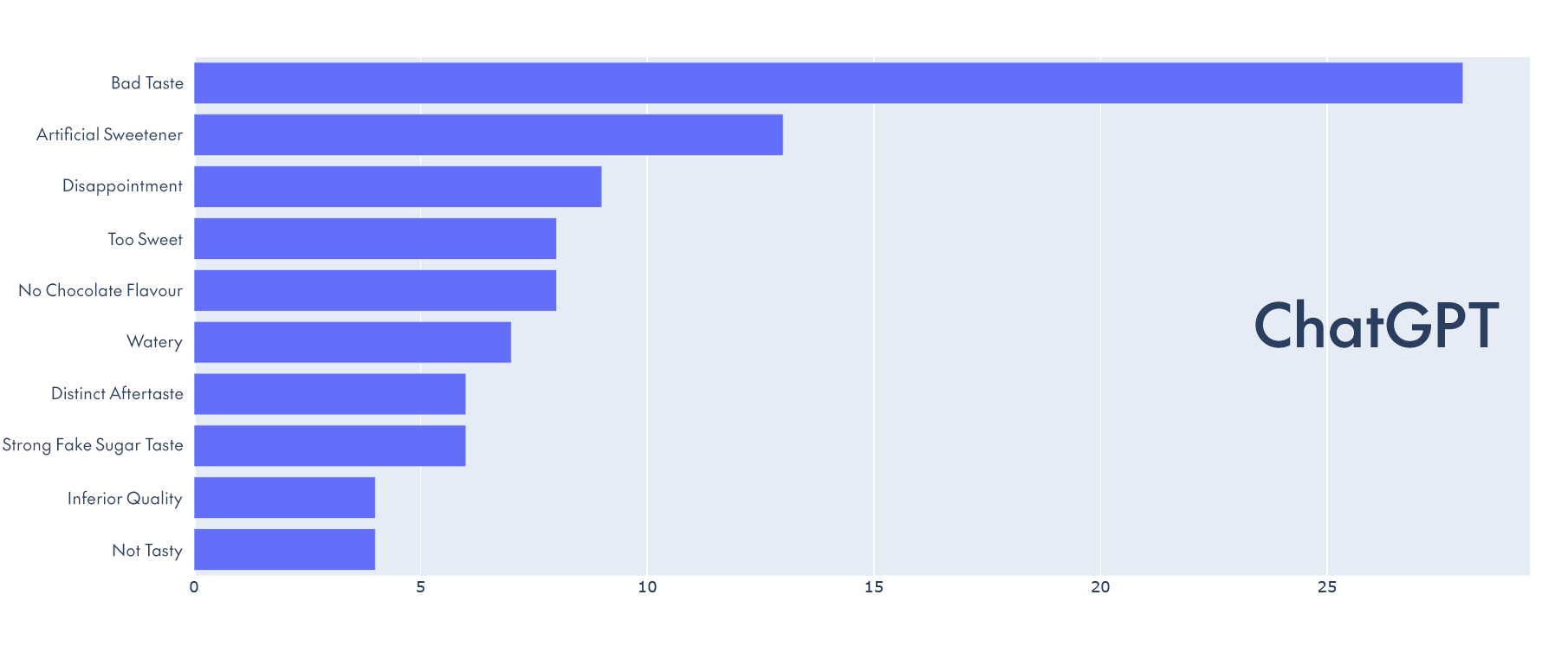
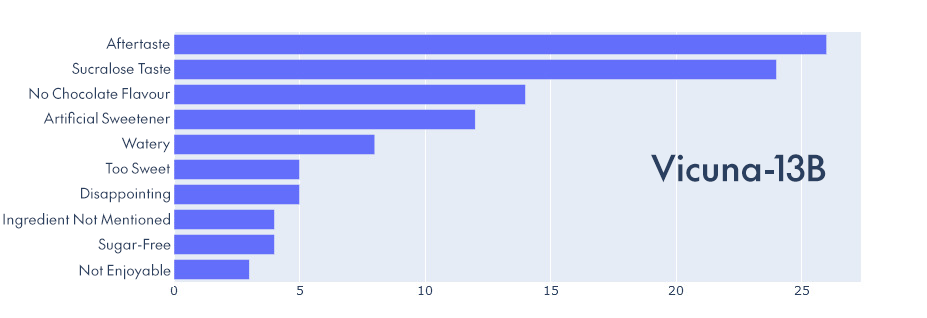
Although not identical, it’s clear that the results are very close and the differences do not impact negatively on the final outcome, so Vicuna-13B certainly works for this use case.
In the next use case, however, the model did not perform so well. We attempted a few-shot classification with the same customer reviews, but instead of having the model extract the complaints, we provided the complaints in advance as categories and tasked the model with selecting those contained in the reviews.
We saw that our local LLM was a lot more generous when it came to assigning the labels, claiming that almost all the complaints were always present in the reviews. This resulted in an astronomical number of false positives (∼160 false positives vs ∼60 true positives).
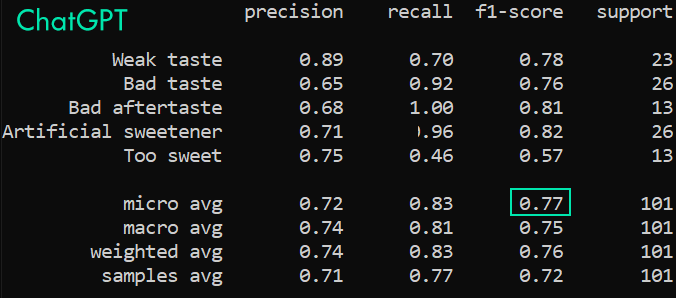
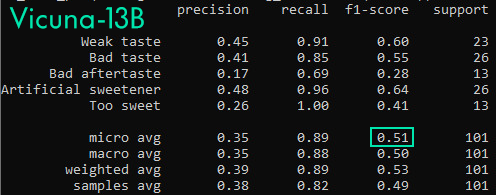
Vicuna-13B’s F1 score of 0.51 suggests that it is not overly proficient at this task (a good F-score typically exceeds 0.7, although this may vary depending on the task). ChatGPT performs significantly better in this regard, achieving an F1 score of 0.77.
Code Generation Use Cases
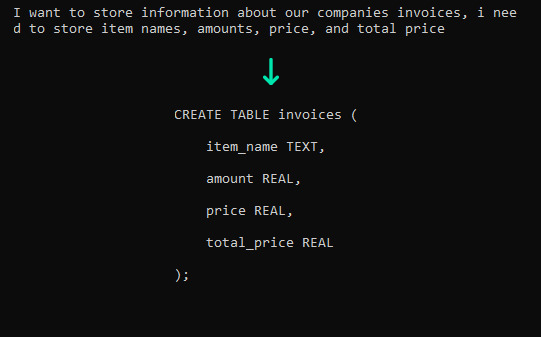
In the second and third blog posts, we performed various tasks involving code generation. In the second blog post we generated SQL statements to create tables and store information in them, so we decided to do the same with Vicuna-13B, and the results we got were satisfactory, although there were some minor syntax errors and occasionally a result was not exactly what we wanted. However, this was not so different from the ChatGPT results.
In those cases where something was wrong, we included the option to continue the conversation with the model, requesting corrections or adaptations to the code based on the user’s needs. This is where the local model failed. While ChatGPT was able to adjust the statements, Vicuna-13B was a lot more “forgetful”, and most of the time claimed it did not have enough information to perform the given task.
Generation of table statement:
The usual response when asked to adjust the table is like this:
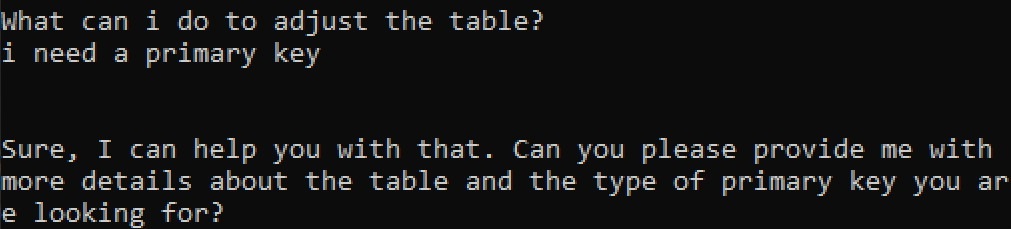
Given this, we concluded that although it was decent enough, it was not sufficiently reliable to be useful in real-life use cases.
In the same second blog post, the other code generation task involved creating graphs using GraphViz scripts, allowing us to visually represent different concepts that were set out in plain text. Vicuna-13B is able to generate these scripts, which is surprising considering it is a lesser-known scripting language. But problems almost always arose halfway through the generation, and more often than not it would get stuck in an infinite loop repeating the same lines over and over, probably because it was trying to follow the text pattern established in the already written text.
Here’s an example – we asked it to generate a flowchart explaining the Watergate scandal, like we did in the previous blog post, and this was the result:
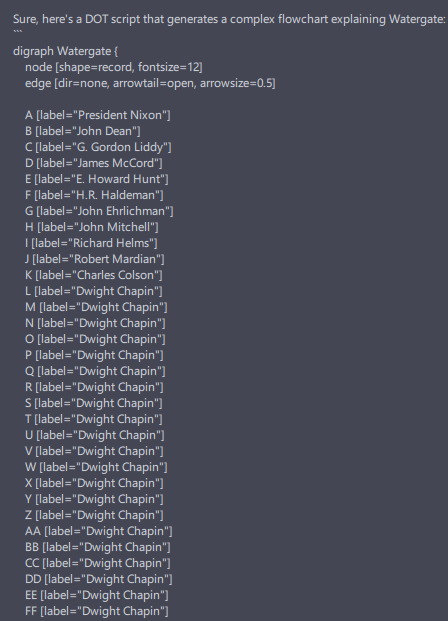
Admittedly, these code generation tasks are a bit of a niche use case so it is not surprising that they don’t perform too well. Nevertheless, for the last task we will test something that is very common, Q&A over a body of text.
Q&A Over Text Use Case
In our third blog post we did what is called a semantic search, which in simple terms takes a user’s question, looks up the most relevant source of information, and then generates an answer by providing the question and the information obtained to an LLM like ChatGPT.
We tried to cover a variety of domains in the questions in order to check how well Vicuna-13B handles complex topics, using the same prompts as those used with ChatGPT. We also checked if it can determine whether the information source is good enough to answer the question, giving an error message if not.
This is the prompt we used:

We found that Vicuna-13B performs very well at these kinds of tasks, managing to generate answers to complex questions and to correctly identify when the information provided is not enough.
We tested this with text extracts from some scientific papers, Wikipedia articles and news stories, all with varying levels of complexity, and without exception it managed to answer the questions, even when they contained dense and highly complex scientific terminology.
Take a look at this example response:

And below, the response when incorrect context is provided:

Conclusions
Small local LLMs perform well with natural language tasks (with the exception of zero-shot classification), but do not do a particularly good job with more complex tasks like code generation.

We can safely say that even now, when small local LLMs are still a relatively new thing, they are a good alternative to commercial services like ChatGPT for specific tasks, and the fact that they guarantee the privacy of the user and their data has made them increasingly popular in open-source solutions (take privateGPT for example).
And remember that new fine-tuning techniques have made training your LLM to perform a specific task a lot easier and more cost-efficient, so if your specific use case does not work, you can re-train the model in less than a day, using a larger, commercial model to generate the training datasets you need.
We hope you have enjoyed this article and learnt how you can still leverage LLMs for certain tasks whilst maintaining your privacy. If you are interested in using LLMs, commercial or open-source, in your own organisation, and think you could benefit from some expert assistance, don’t hesitate to contact us – we will be happy to help!
