22 Jul 2020 Hybrid ETL with Talend and Databricks
As companies migrate more and more of their data to Cloud and use Big Data tools such as Hadoop and Spark for processing, they come up against the problem of finding the right ETL tool for integration and workflow orchestration, the tool that best fits the requirements of a hybrid approach, i.e. that combines data and resources from both on-premise and Cloud. Talend has been positioned as a leader in Gartner’s data integration magic quadrant for the last few years and offers great solutions for ETL orchestration and data governance, both open source and licensed. In this blog article we are going to look into how Talend Open Studio for Big Data can be used to combine traditional ETL capabilities with the possibility to leverage Cloud storage and compute resources to orchestrate Big Data jobs that run on Databricks.
Here at ClearPeaks, as experts in Business Intelligence, Big Data and Advanced Analytics, we have used many tools designed to make Big Data and ETL orchestration easier. We invite you to read through some of our latest blog articles on the topic here.
Please note that the solution presented in this article is not intended to be a complex, optimized solution, but a simple one to give our readers an idea of the tool’s possibilities.
Before you continue reading, and if you are new to Talend, we recommend you read the following blog article, where we go through all the capabilities this software offers: Talend Overview: Collect, Govern, Transform and Share your data with Talend.
1. Test case overview
A standard ETL in Cloud usually has the following steps: first, it ingests data from different sources into Cloud storage (Data Lake). Second, a Cloud data processing engine reads the data from the Cloud storage and does the needed processing to clean, merge and transform the data; finally, the ready-to-use data is loaded into a single point of truth, usually a data warehouse, for further analysis using BI tools or Machine Learning pipelines. However, we usually find use cases where a hybrid approach is required by the customer – part of the processing happens on-premise and another part happens in Cloud. For example, a customer may want to do some light processing before loading the data to Cloud (for example, masking sensitive fields); and then once the data is in Cloud, they will run “Big Data” processing, thus taking advantage of all the benefits Cloud offers when processing large amounts of data.
In this blog article we aim to simulate a hybrid use case, in which part of the processing is done on-premise and part of it in Cloud. We will use Talend Open Studio for Big Data to extract data from different data sources and do an initial cleaning and transformation of the data using Talend components. Then we will load the data to Azure Blob Storage and trigger a Databricks job to outsource the Big Data processing; everything will be orchestrated from the Talend interface. For the purpose of this blog article we have used a dataset available in Kaggle from Flight Delays and Cancellations of the year 2015 in the USA (https://www.kaggle.com/usdot/flight-delays). We have simulated a process in which new flight data is added every month into an FTP server; and the Talend pipeline reads it from there. In our sample case we have also used other sources of data, in this case CSV files stored locally on the machine where Talend is running.
Once the data has been processed with our entire pipeline, it is loaded into a data warehouse to further analyse the delays suffered by each airline and their root causes. However, such analysis is outside the scope of this blog article
2. ETL process with Talend Open Studio for Big Data
Talend allows the user to simplify the ETL process for Big Data. Talend makes the ETL process easier and clearer, and it can connect to several types of data sources, such as HDFS, Hive, Impala, Cloud services, NoSQL, RDBMS, web services, and some SaaS services.
The ETL process we developed for the test case first extracts the data from three data sources, joins them and finally uploads the resulting data into Azure. The image below shows an overview of the whole pipeline in Talend. In t he subsections below we will explore the different parts of this solution.
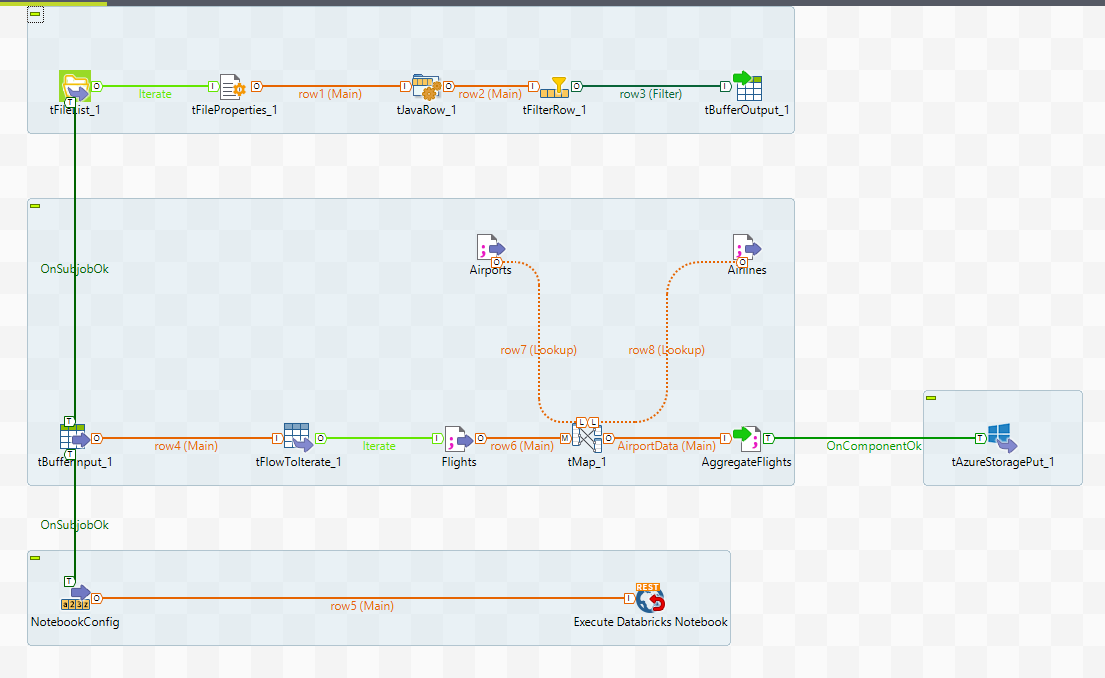
Figure 1: : Pipeline overview in Talend
2.1. Extraction
The first step of the pipeline is to extract the files that contain new data. In this case, we have implemented an approach to look through the properties of the files and compare the last modified date of the file with the current date. Every day, when the pipeline executes, it only uploads the files that have been modified the day before.
In order to implement this logic in Talend, we first loop though the list of files in the FTP Server and look into the properties of each file using the built-in components: tFileList and tFileProperties.

Figure 2: Workflow to extract the new data
Once we have this data, we use the tJavaRow to transform the format of the date and the tFilterRow to keep only the metadata of the files that have been modified the day before. This data is saved in memory using the tBufferOutput, which allows you to store temporal data without saving it to disk.
2.2. Transformation
The second step is to process the flights and enrich the dataset with other data sources such as datasets with details on airlines and airports. In this test case both datasets are local CSV files, but you can leverage the large number of connectors Talend offers and ingest data from other database systems, APIs, web services, FTP servers, etc.
In order to read the data that has been stored in memory previously, we use the tBufferInput component, which now contains a table with the metadata (file path, filename, modified date, etc) of the files we are interested in.
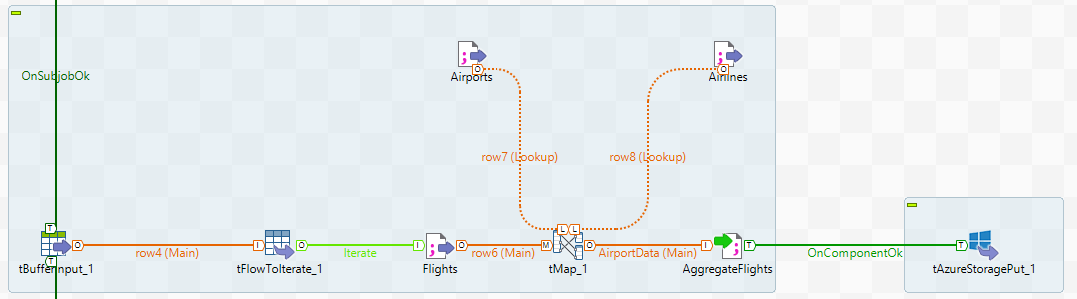
Figure 3: Workflow to merge and load the data to Azure.
Then the tFlowToIterate component allows us to iterate through a list, in this case, the list of files that we have to process. To merge the three different datasets into one final file, we use the tMap component, which allows you to join different datasets, apply filters and choose which is your output:
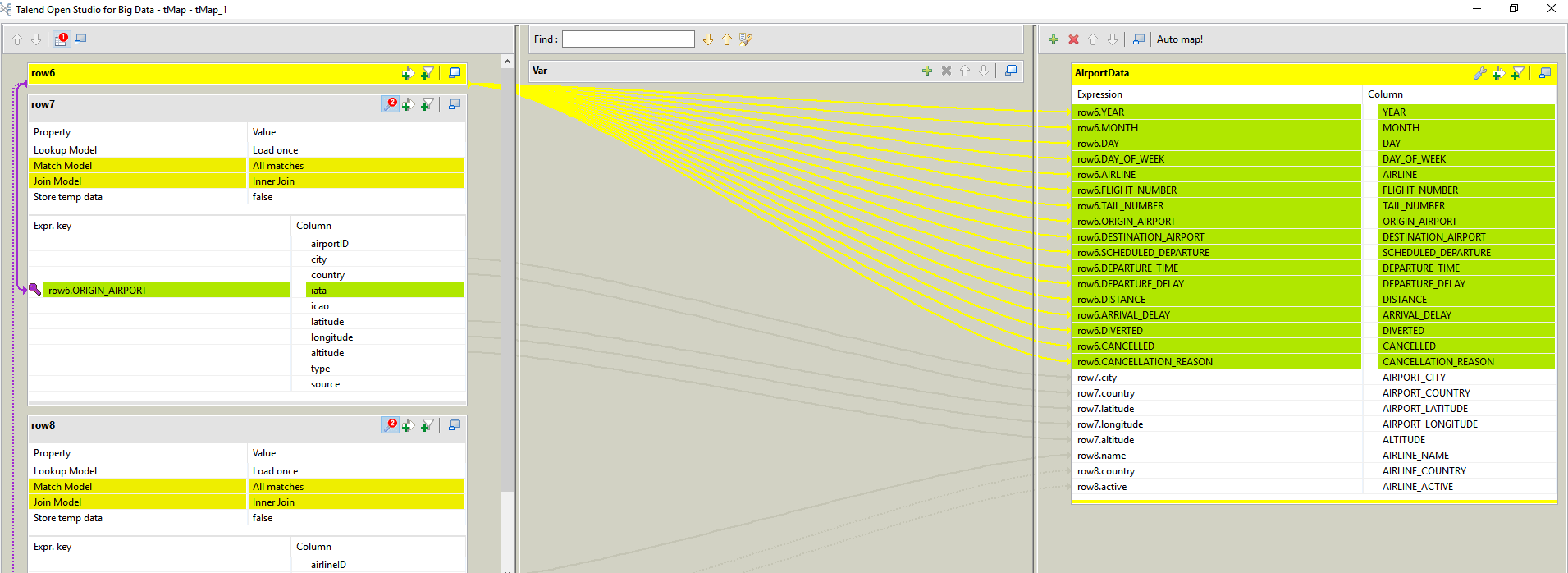
Figure 4: Detail view of the tMap component.
This image is a screenshot of the options available in the tMap component: on the left side we have the three different datasets and we can define the join key; then we can define as many outputs as we want, choosing the required columns of each dataset and applying any Java expression to create new columns too.
Finally, we make use of the tAzureStoragePut connector to upload the dataset to a specific container in Azure Blob Storage, for further processing of the data in the cloud.
2.3. Databricks trigger
The final step in our pipeline is to execute the Databricks notebook which will process the data and load it to the final data warehouse. To do this in Talend we need to make use of the Databricks REST API to make a post request that will run a defined job ID.

Figure 5: Workflow to trigger the Databricks job execution
The first component in the image will define the payload of the request with the information of the job we want to run. You can also define other parameters here:
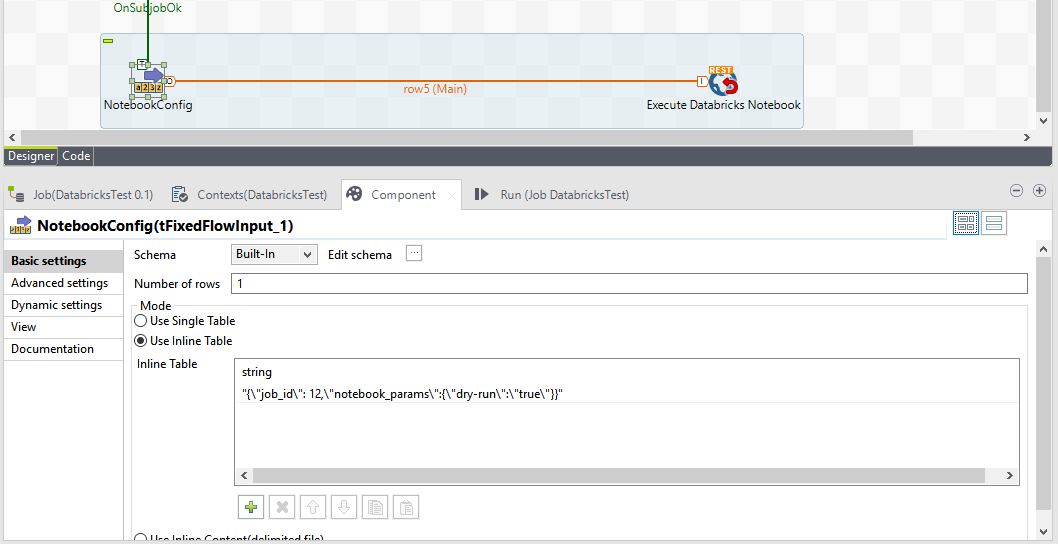
Figure 6: Detail view of the configuration of the request
Using the REST API component in Talend we make the post request to our Databricks account to run the required job. You also have to define the authentication in this step:
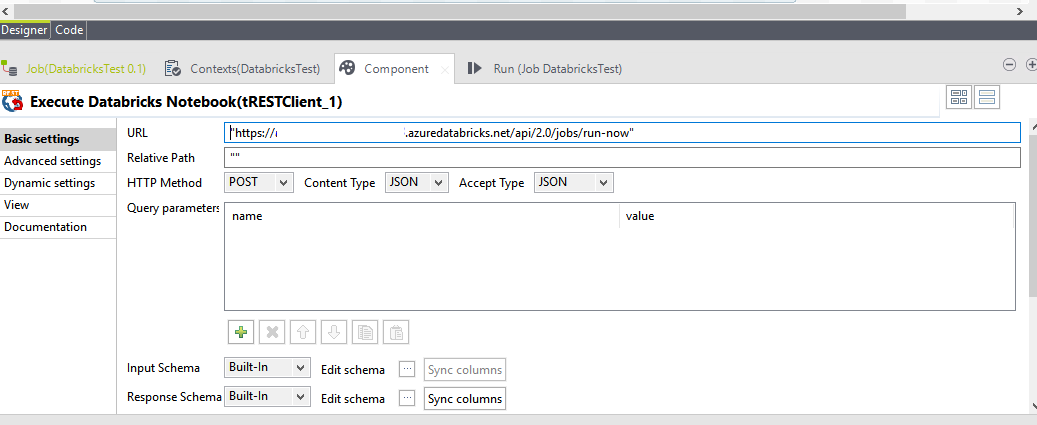
Figure 7: Detail view of the configuration of the REST client component.
Finally, we can now access the data from Databricks and continue our transformations using the capabilities of Spark for Big Data processing:
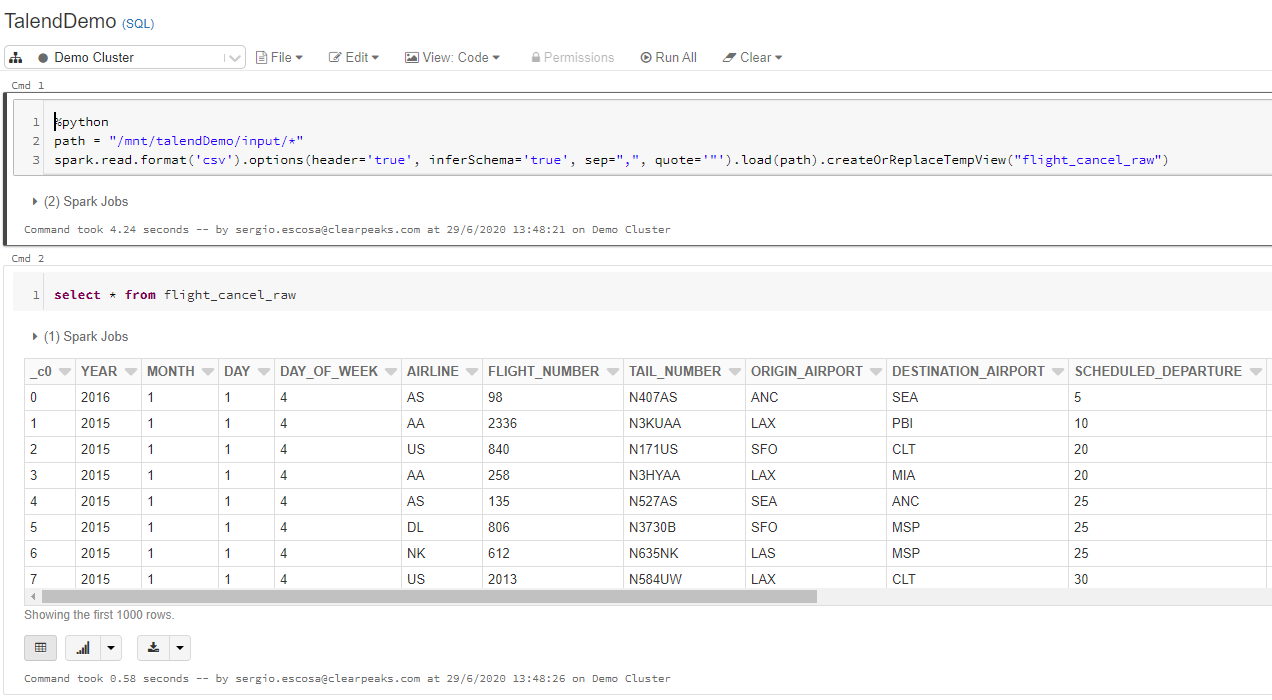
Figure 8: Data is available in Databricks for further processing.
Conclusions
In this blog article we have explained how Talend Open Studio for Big Data can help you to orchestrate and run hybrid workflows between on-premise systems and Cloud.
While working with Talend we have experienced its great system integration capabilities, being able to extract data from different sources including most of the Big Data connections one may require; it also has pre-coded components that you can drag and drop to make your data transformations. Moreover, it’s very flexible, and you can add Java code for more customized data transformations. When running your jobs, you can see real-time statistics on the job status. Finally, let’s not forget that it is an open-source tool! The licensed product, called Talend Data Fabric, includes other features such as Talend Data Quality, Data Catalog or Data Stewardship that allow you to manage and govern your data.
Finally, we would like to mention that this blog article is an example to illustrate the capabilities of Talend on hybrid scenarios. Alternatively, we could have uploaded the 3 data sources directly to Databricks and merged them there (which would be recommendable if the datasets were big). With Talend, we can achieve hybrid ETL, where part of the processing is done by Talend and part can be offloaded to a powerful engine like Databricks via API.
For more information on how to deal with and get the most from Talend, and thus obtain deeper insights into your business, don’t hesitate to contact us! We will be happy to discuss your situation and orient you towards the best approach for your specific case.
