03 Sep 2018 Oracle Exchange Partition strategy applied to ODI
It is possible to save time and resources during an ETL execution by using a loading strategy based on Oracle Exchange Partition; we’re going to show you an Oracle IKM that allows us to load or swap a table on a partition of a partitioned table and also gives us the opportunity to save time and resources when loading large datasets during the ETL.
1. Oracle Partitions – brief explanation: their advantages and disadvantages
First of all, let’s look at partitions: partitions in Oracle are subdivisions of a table, creating smaller pieces that make up different objects in the database with a finer granularity. We can access, edit and process these partitions independently from each other without having to process the entire table, thus making it easier to manage our data. For example, you can subdivide a table by different years so that you can access the data for a particular year independently. Every table can be partitioned, you just need a Partition Key, but this is only recommendable for big datasets.
Making these partitions offers many benefits in terms of performance and manageability. We can handle these smaller pieces more easily and independently from the others, and downtime due to corrupted data is reduced, since if there is a problem with one of the partitions the others are still available, allowing us to solve the problem while the rest remain accessible to the user. Likewise, data backup and recovery can be done independently and storage usage can be reduced too as we’re dealing with smaller pieces. Using these smaller pieces makes it easier to read and load data because we don’t need to process it all, so we need less execution resources. It is a very good option to optimize ETL executions and keep things organized.
Despite these obvious pros, there are some cons. Performing these partitions adds complexity: more elements require additional administrative tasks to handle the partitions. As we said before, this technique is only recommendable for large tables.
There are three types of partition (or three ways to divide a table). We can divide a table by Range, where we define, for example, the range of dates that we want to have in our partitions; by List, where we define which values from a list belong to each partition, for example, to define a division by region; or by Hash, where we can divide the table in equal parts. We can also subdivide a partition using any of these three techniques in order to obtain smaller parts that can be processed simultaneously.
2. Oracle EXCHANGE PARTITION strategy: explanation of how Oracle allows directly exchanging a partition with a table when partition_name = table_name
We can use these partitions to upload tables in an easier way and improve ETL performance in ODI. Oracle has a KM (knowledge Module) that uses Oracle Partition Exchange technology to upload data by partitions. This KM is known as IKW PEL (Integration Knowledge Module Partition Exchange Load) and allows us to exchange a single partition of a partitioned table for new data, without using the data from the other partitions. We can upload an entire table as a partition to a partitioned table, defining a partition with the same name as the table that we want to upload.
There are 7 steps in ODI to complete the process and exchange partitions:
- Drop the temporary table to ensure it’s empty; if it fails it’s ignored.
- Create the temporary table that will be used to insert the desired data.
- Insert the data generated by the interface into the temporary table.
- Create the indexes for the temporary table.
- Calculate statistics for the temporary table.
- Execute the exchange partition between the selected partition and the temporary table.
- Drop the temporary table.
These are the basic steps to complete an exchange, but remember that ODI allows us to set different options. For example, we can define if the exchange is with a partition or a subpartition, we can set Incremental Statistics or disable the Constrains before the exchange, amongst other options.
3.Parallelizing executions in ODI using exchange partition Integration Knowledge Module (PEL IKM): load performance improvement benefits
Using Oracle Partition Exchange offers a lot of benefits, improving ETL performance. With this module we can upload our data faster than the classic SQL upload operations as the partition exchange operation is instantaneous. Additionally, we can improve the loading time by uploading different tables at the same time as we can exchange different partitions of the same table in parallel orchestration.
We can improve our resources too: Oracle Partition Exchange doesn’t need to create or duplicate additional datasets as it only exchanges data segments, creating a temporary table to exchange with the partition. Reducing this need to duplicate datasets for integration tasks means we need less database storage and resources.
4. Use Case: developing a simple example
The IKM Partition Exchange Load can be used in conjunction with ODI packages and ODI load plans to orchestrate the entire data upload operation of a partitioned table. For instance, an ODI package can be designed to upload multiple partitions of the same partitioned table in parallel.
In the following example, a loading strategy partitioned by weeks has been built, the main goal being to reduce load times using ODI executions. In this case, the purpose is to load several different time periods using different temporary tables for each one.
Once the different temporary tables have been loaded, each one is exchanged with a specific final table partition for the target required. This approach could be used for any partitioned table and time frequency, like monthly or annually, with the same structure model.
Weekly Partitions Case Example
A master scenario orchestrates the parallelization, calling a slave scenario each time a new process can be executed. This package invokes two ODI scenarios: Load Next Partition and Load Last Partition. Both ODI scenarios have been generated from the same mapping, using the appropriate deployment specification each time.
The package counts the total number of partitions found in the partitioned table, and for each partition found, the package refreshes an ODI variable and proceeds to upload the partition.
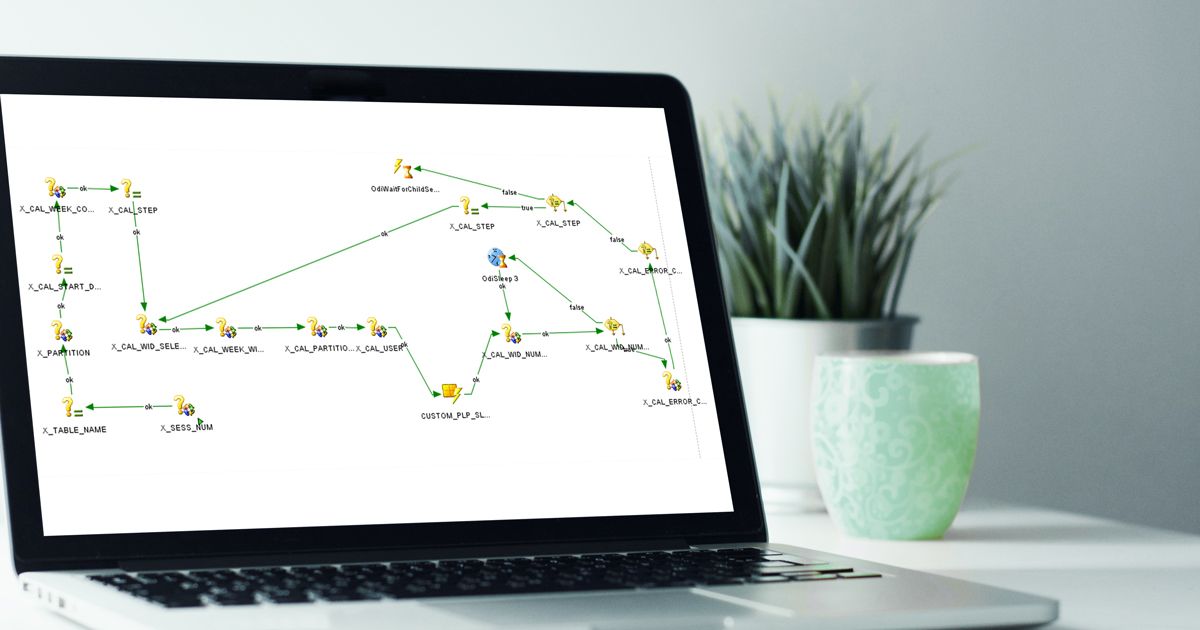
Below can you see the steps and variables used for the procedure:
X_SESS_NUM: Gets ODI Session.
select <%=odiRef.getSession(“SESS_NO”)%> from Dual
X_TABLE_NAME: Static, we introduce the target table name, in this case:
X_PARTITION: For the given target table, check the partition naming pattern.
select substr(partition_name,1,instr(partition_name,’_’,-1)) from user_tab_partitions where table_name = #X_TABLE_NAME||’_T’
and rownum=1
X_CAL_START_DATE: Static, mark the initial partition range to load. For example, the first week to load (i.e. ‘20180101’).
X_CAL_WEEK_COUNT: Counter, will indicate the number of loops to perform.
WITH
dept_count AS
( SELECT
TO_CHAR(TO_DATE(‘#X_CAL_START_DATE’,’YYYYMMDD’) + ((level – 1) * 7),’YYYYWW’) as week, level
as Step
FROM
dual
CONNECT BY rownum <= 1000 )
SELECT count(*) FROM dept_count WHERE week <= (select max(cal_week_wid) from wc_assignment_weekly_T)
X_CAL_STEP: Step to load and assign step 1.
X_CAL_WID_SELECTED: Week corresponding to the step to load.
WITH
dept_count AS
( SELECT TO_CHAR(TO_DATE(‘#X_CAL_START_DATE’,’YYYYMMDD’) + ((level – 1) * 7),’YYYYWW’) as week,
level as Step FROM dual
CONNECT BY rownum <= 1000 )
SELECT Week FROM dept_count WHERE Step = ‘#X_CAL_STEP’
X_CAL_WEEK_WID_TABLE: The full name of the temporary table we want to load.
SELECT #X_TABLE_NAME||’#X_CAL_STEP’ FROM DUAL
X_CAL_PARTITION_NAME: The full name of the partition in the target table.
SELECT ‘#X_PARTITION’||#X_CAL_WID_SELECTED FROM DUAL
X_CAL_USER: ODI user loading executing the process.
SELECT USER FROM dual
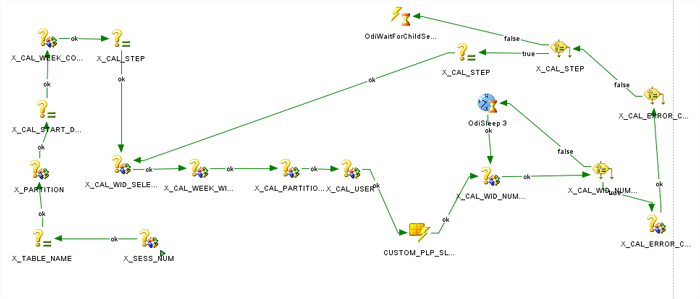
CUSTOM_PLP_SLAVE_WC_ASG_DEV_GOAL_WEEK_PE_LOAD version001: Corresponding to the custom flow to load each table. It is important that the parameter is set on asynchronous mode, which allows running more processes in parallel.
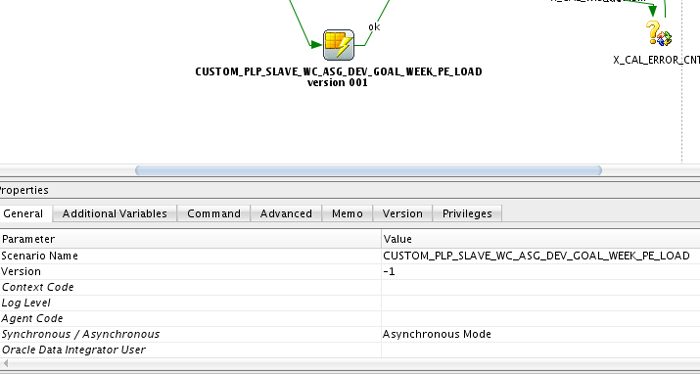
X_CAL_WID_NUMBER_OF_EXECUTIONS: Number of executions already running.
select count(*) from snp_session where Parent_sess_no=#X_SESS_NUM and sess_status=’R’
X_CAL_ERROR_CNT: Count of errors in the slave execution.
select count(*) from snp_session where Parent_sess_no=#X_SESS_NUM and sess_status=’E
OdiSleep Object: Introduce a pause when we reach a max number of sessions running.
OdiWaitForChildSession: For the last execution running, master scenario must wait for last slave to finish.
CUSTOM_PLP_SLAVE_WC_ASG_DEV_GOAL_WEEK_PE_LOAD version001
This flow corresponds to the individual control of every partition and load temporary and end tables. The main function is to ensure that the table is prepared for the load, the partition is created and then loaded successfully.
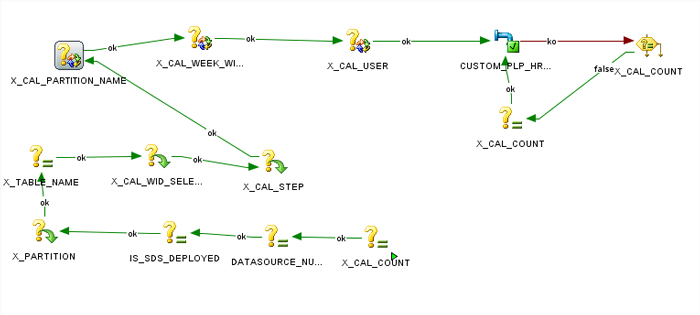
X_CAL_COUNT: Counter to control number of attempts by the slave.
X_PARTITION: Inherited from MASTER.
X_TABLE_NAME: Inherited from MASTER.
X_CAL_WID_SELECTED: Inherited from MASTER.
X_CAL_STEP: Inherited from MASTER.
X_CAL_PARTITION_NAME: Inherited from MASTER.
X_CAL_WEEK_WID_TABLE: Inherited from MASTER.
X_CAL_USER: Inherited from MASTER.
5. Limitations: explore the strategy’s limitations and define its suitable scenario
The major limitation of this strategy is the complexity of the procedure to load a table and the need to plan the partitions of the table carefully in order to make sense of your data. Another limitation is managing the global indexes used; as commented, the partitions are handled like a simple table but are a part of a system of tables. This complexity complicates index management.
Conclusion
The Partition Exchange Load is a good strategy to implement in specific cases, allowing better performance as the partition exchange operation is instantaneous. It also reduces the load time, since multiple partitions of the same table can be uploaded and exchanged simultaneously. It is an excellent tool to perform initial and incremental upload operations of large data warehouses, as it cuts the load time, the cost and the storage resources used. Nevertheless, it adds complexity and demands specialist technical knowledge of ETL tools and database structure.