
07 Jun 2023 Using ChatGPT to Structure and Index Unstructured PDF Files
Extracting usable information from semi-structured or completely unstructured data is a must for companies with large amounts of data, and here at ClearPeaks we often come across organisations that have stored thousands of PDFs filled with valuable information. In most cases, as time passes, these archives grow to an unusable size, making it impossible to search for information in a reasonable amount of time, meaning the implementation of domain-specific parsers for querying.
However, one of the biggest barriers to implementing something like this was the fact that, until very recently, processing plain text expressed in natural language was a very laborious and expensive task, offering extremely limited results.
Nowadays, Large Language Models (LLMs) have not only made this task a lot cheaper, but they have also made it much more accessible and easier to do. If, for example, you want to carry out a sentiment analysis on a lot of text, instead of having to clean the data and set up traditional natural language processing techniques, you can just write a prompt and your preferred LLM will happily do the job for you! You can see an example of this in one of our previous blog posts.
Today, we’ll explore two ways of structuring and processing an organisation’s internal documents, and then compare these two methods to similar techniques to get an overview of the current state of the art. We’ll also provide Python code examples to make it easier to understand.
First, let’s see how to convert information contained in PDFs into queryable SQL tables, extracting only the information we want and ignoring the rest. Secondly, we’ll see how to index a large set of documents to create a chatbot that can answer any question about the content of those documents, whilst referencing which document and page the answers came from.
Ingesting Documents into SQL Databases
For the first use case, our objective is to turn all those PDF files into a structured SQL database, without having to insert all the information manually, one document at a time.
The first step is to ask the user what information they want to save. We could ask them to provide a table schema and a description of what information they want to store in it, but why not ask ChatGPT to do it for us?
We can do so using the following prompt template:
Given the following request: “REQUEST” Give me an SQLite create table statement that stores the information the user requests. Use clear labelling, do not add unnecessary information.
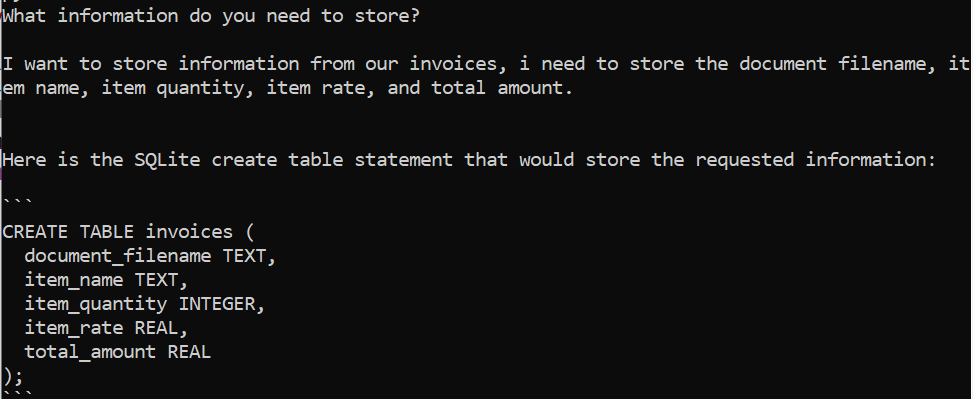
We can then ask the user if they’re happy with the table or if they need to adjust anything.
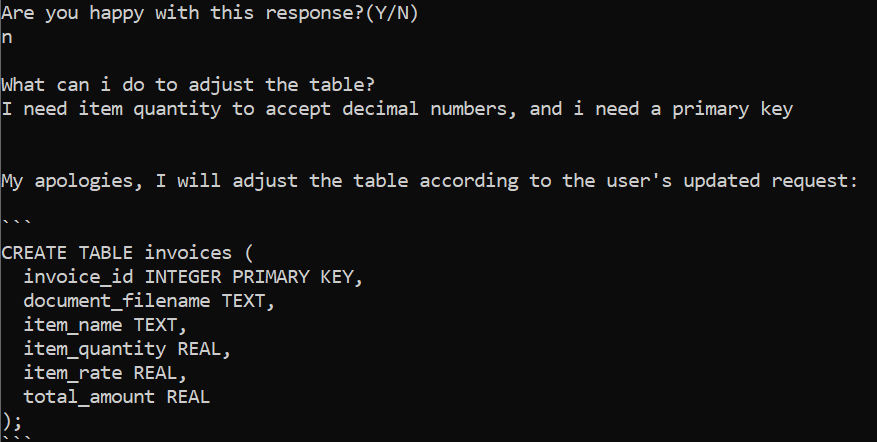
Once the user is satisfied, we can run the statement and move on to processing all the documents to fill the table.
We transform each PDF into plain text, and feed it into ChatGPT using the following prompt:
Given the following table schema: Schema: “SCHEMA" And the following PDF document named “FILENAME”, which has been passed through a PDF to plain text function: Document: “DOCUMENT” Create an insert statement for the table, that fills it out with relevant data contained in the PDF file. Give no explanation, only the SQL statement inside of a markdown code block.
We tested this with documents containing information in plain text and on tables. We had to ignore the images contained in them, but given that GPT-4 can accept images as input, we might be able to change this in the future when its API is open to the public.
The following piece of text (ignore the nonsensical pricing):
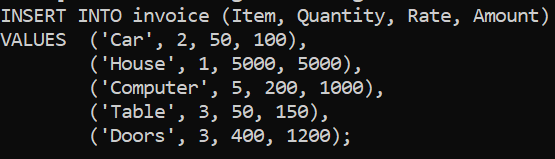
- The company made several purchases, including two cars that cost $50 each, resulting in a total expenditure of $100. The cars were green in colour. The company also purchased one house, which cost $5000. The house was blue in colour, and the total amount spent on it was also $5000.In addition to the cars and house, the company bought five computers, each costing $200, for a total of $1000. As well as three doors for the price of 400$ each. Finally, the company purchased three tables, which cost $50 each, resulting in a total expenditure of $150. The tables were black in colour.
gets converted to:
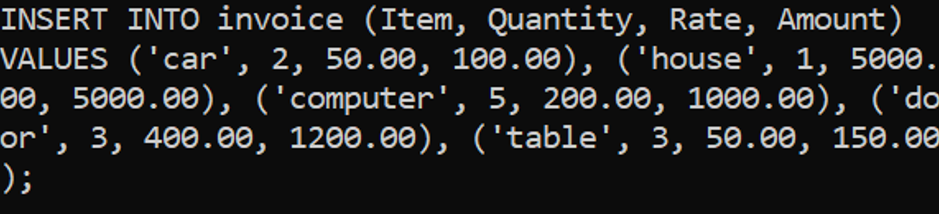
(This screenshot was taken with a table schema slightly different from the one before).
Note that at no point did we specify the total cost for the 3 doors, so it’s able to infer that 3 doors for 400$ each is 1200$, and fills out the missing total amount field.
Putting the same information in table form gives us the same result. We also added some irrelevant columns and extra tables that have nothing to do with invoices to see if it got confused, but it got it right.
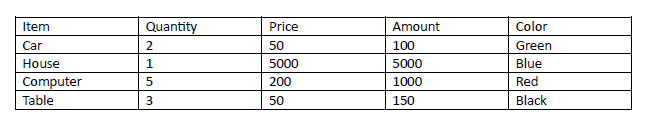
Aside from this, there was also a purchase of three doors at the price of 400$ each.
Other information:

And it gets turned into:
One of the challenges we encountered involved the conversion of PDFs to plain text, as the resulting text sometimes appeared in the wrong order, specifically when it had been contained in tables; ChatGPT had generated incorrect insert statements. Fortunately, we were able to fix this by explicitly stating in the prompt that the text was obtained through a PDF to plain text function.
A persistent issue was duplicate information: when both table-formatted and text-formatted data were included, the information was inserted twice into the table. While adjusting the prompt can solve this to some extent, it requires a case-by-case adjustment depending on how the PDF is formatted, so to address this properly the insert statements would need to undergo a filtering process to eliminate duplicates effectively.
This works fairly well when run on a lot of documents at once. However, time and cost are a problem here if we’re talking about thousands of documents, as the processing could take hours or even days to complete, and API usage would be expensive.
One solution that was showcased in arXiv:2304.09433 consists in taking a small sample of the documents, getting the LLM to figure out the pattern in which the documents store the information we’re after, and then to generate a Python code to extract this information from the entire batch, which is much faster and totally cost-free once the code has been generated.
This method relies heavily on all the documents sharing the same format, but if your organisation uses standardised document templates, this shouldn’t be a problem.
Document Chatbot
Next up, we’ll create a chatbot that can answer questions about a set of documents, first searching for the most appropriate documents to answer a question, and then generating the answer with ChatGPT.
Index Generation:
We’ll search for information by using word embeddings, with OpenAI’s embedding API, and generate three embeddings for each page, split into three segments of text. This approach is similar to the one that tools like LangChain or LlamaIndex use, and we want to show you how things work under the hood.
(Note: There are free alternatives to OpenAI’s embedding service that can be run locally, like Facebook’s LASER embedding tool; an exploration analysis should tell you which is right for your project).

We then create an index that contains all the embeddings for each document, with the document name and a page number for each embedding included. This index is then saved for future use. The process needs to be done only once per document; if we insert new documents the embeddings generated are added to the index.
We reused the chat interface from our last article, which was about interacting with SQL databases via a chatbot.
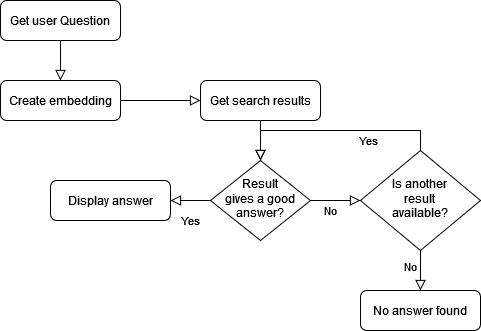
Now that we have an interface for user input, we take the questions, get their embeddings, and compare them to the document’s embeddings using cosine similarity. In other words, we will look at how similar they are in order to rank how good a match they are. We decided to keep the top five results and discard the rest.
The following piece of code is repeated for each segment of text we indexed:

The reason we save the top five results instead of just the best is because cosine similarity sometimes gets it wrong: when it comes to indexing papers and scientific studies, the reference-heavy pages at the end often have a very high cosine similarity with user questions, even though those pages contain no valuable information.
So now we have five possible search results. We will construct a prompt for each so that the ChatGPT API creates a reply, or informs us if there is not enough information to answer the question. This is the prompt:
You are an isolated machine that has no knowledge of the outside world, everything you know comes from the context we provide you in this prompt. Given the user question and the context we will provide, I ask you to do the following: If there’s enough information in the context to answer the question, answer it using only information contained in the context, nothing else. If there's not enough information to answer it, respond with the following sequence of characters: "%$%$" User question: “QUESTION” Context: “CONTEXT”
The context field corresponds to the piece of text where the result was found, with a bit from before and after appended to provide some more information.
We have to specify that all knowledge must come from the context because sometimes, when there isn’t enough information to answer a question, ChatGPT will make up an answer based on the knowledge it already has. It often confuses topics from different fields with similar names, and if you want to obtain information strictly from your own documents, this can be a problem.
So, if the string “%$%$” is in the response, we discard the answer and move on to the next result, repeating the process until we get a good answer or until all five results have been checked.
The following message is displayed if no valid result is found:

When a valid result is found, we send a response to the user and attach a reference at the end to show which document the information came from.
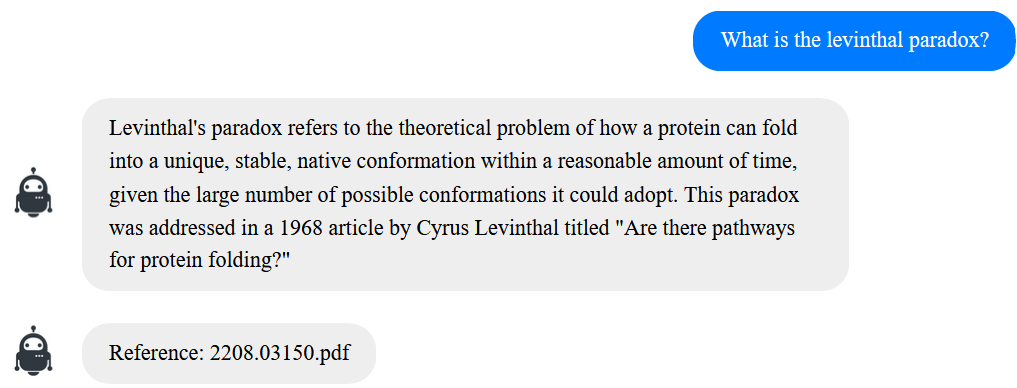
Examples
Here are a few examples to show how the program performs on our test document set, composed of scientific papers:


Conclusions
A potential drawback of this approach is that if finding a suitable match for a document search requires multiple attempts, it can be time-consuming because the ChatGPT API can sometimes take a few seconds to give a response. In order to improve this, we would likely have to combine embeddings with other search engine techniques so the best search results would be nearer the top, as well as parallelising a lot of these processes, especially the API calls.
However, as a proof of concept this works well enough. In our next article we’ll see how locally run LLMs compare to commercial-grade language models like ChatGPT, to see if the use cases we’ve been exploring are feasible without depending on third-party processing.
We hope this article has given you some insights into how LLMs are currently being used to turn heterogeneous data into more user-friendly, accessible information. If you are interested in harnessing this technology to your advantage, get in touch with our dedicated team and we’ll be happy to help.
