
06 Mar 2024 Using Snowpark and Model Registry for Machine Learning – Part 2
After preparing our data in the first part of this mini-series, we can now turn our attention to the training of machine learning (ML) models and how to manage the different models and versions, as well as how to use them for inference.
Snowflake continues to innovate with features tailored for data scientists and engineers. Among its many tools, the Model Registry feature stands out as a game-changer in simplifying model management and collaboration. In this second part of our mini-series, we’ll delve into the feature’s details, exploring how it streamlines the lifecycle management of machine learning models within a single, unified schema-type object. By providing a centralised repository for storing, versioning, and deploying models, Model Registry facilitates efficient management of models, the flexibility to use different machine learning packages, and to use them to make predictions.
We’ll walk you through its core functionalities and benefits by continuing with our real-world use case scenario, as presented in the previous blog post. Whether you’re a data scientist, engineer, or business stakeholder, understanding how to leverage this feature will unlock new possibilities for driving innovation and competitivity within your organisation.
Training Machine Learning Models in Snowpark
With our data prepared and in place, we can start the training of three distinct models leveraging the snowflake.ml.modeling package: ‘LogisticRegression’, ‘XGBClassifier’, and ‘GradientBoostingRegressor’ from the scikit-learn package. After training, we’ll use the Model Registry feature to securely store these trained models in our Snowflake Database.
It’s important to note that, during this phase of the blog post, we won’t be looking at model tuning or validation techniques. Our primary objective is to explore the possibilities that Model Registry offers, emphasising its role in efficiently managing and organising machine learning models within the Snowflake ecosystem.
We will start by creating our train and test data:
# We prepare the train data so 80% of Rating values being 1 and 0 are inside the training data. train_sdf = snowpark_df.sample_by("RATING", {"1": 0.8, "0": 0.8}) train_sdf = train_sdf.cache_result() # Test data will be the values from the table thar are not in train_sdf test_sdf = snowpark_df. minus(train_sdf)
As previously observed, the distribution of our target variable within our dataset is somewhat imbalanced: 68.6% (BAD) – 31.4% (GOOD). To enhance the quality of our training data, we’ll use the SMOTE package, an oversampling technique designed to balance class distribution in a dataset:
# Loading data into pandas dataframe train_pdf = train_sdf.to_pandas() # Define features and label feature_cols = train_sdf.columns feature_cols.remove('RATING') target_col = 'RATING' X = train_pdf[feature_cols] y = train_pdf[target_col] # Oversample minority class via SMOTE from imblearn.over_sampling import SMOTE X_balance, y_balance = SMOTE().fit_resample(X,y) # Combine return values into single pandas dataframe X_balance[target_col] = y_balance # Persist dataframe in Snowflake table session.sql('DROP TABLE IF EXISTS DATA_TRAIN') session.write_pandas(X_balance, table_name="DATA_TRAIN", auto_create_table=True) test_sdf.write.save_as_table(table_name='DATA_TEST', mode='overwrite')
Now our training data is balanced:
train_sdf = session.table("DATA_TRAIN") tot = train_sdf.count() train_sdf.group_by('RATING').count().sort('RATING')\ .with_column('PER',F.col('COUNT')/tot*100)\ .show()

MODEL 1: LogisticRegression
Let’s train our first model using the ‘LogisticRegression’ function inside the Snowflake ML modelling package. For more information about how to train ML models with Snowpark, check out the Snowflake documentation:
from snowflake.snowpark.session import Session import snowflake.snowpark.functions as F from snowflake.ml.modeling.linear_model import LogisticRegression from snowflake.ml.modeling.metrics import * import json import pandas as pd import seaborn as sns feature_cols = train_sdf.columns feature_cols.remove('RATING') target_col = 'RATING' lr = LogisticRegression( C=0.8, solver='lbfgs', random_state=0, input_cols=feature_cols, label_cols=target_col, output_cols=['PREDICTION'] ) lr.fit(train_sdf)
A big advantage of snowflake.ml.modeling is its effortless integration with scikit-learn. Models trained within the Snowflake environment can be easily converted to the scikit-learn format. This flexibility highlights the adaptability of Snowflake’s ML functionalities, providing a bridge between different frameworks, and guaranteeing a versatile approach to model deployment:
lr_local = lr.to_sklearn() lr_local
Now we can check our model’s metrics:
from snowflake.snowpark.functions import udf session.custom_package_usage_config = {"enabled": True} #Prediction values using test data scored_snowml_sdf = lr.predict(test_sdf) #Let's create a confussion matrix to see our results: cf_matrix = confusion_matrix(df=scored_snowml_sdf, y_true_col_name='RATING', y_pred_col_name='PREDICTION') sns.heatmap(cf_matrix, annot=True, fmt='.0f', cmap='Blues')
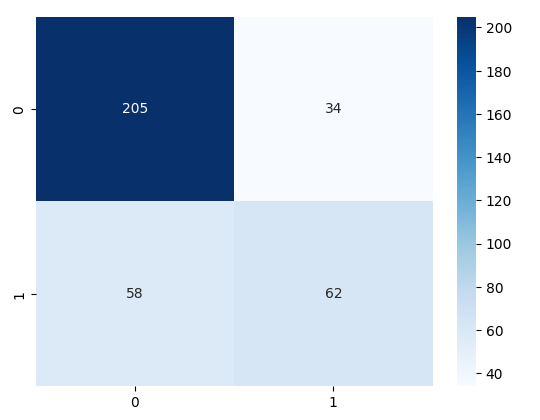
And some of the model’s metrics values:
print('Acccuracy:', accuracy_score(df=scored_snowml_sdf, y_true_col_names='RATING', y_pred_col_names='PREDICTION')) print('Precision:', precision_score(df=scored_snowml_sdf, y_true_col_names='RATING', y_pred_col_names='PREDICTION')) print('Recall:', recall_score(df=scored_snowml_sdf, y_true_col_names='RATING', y_pred_col_names='PREDICTION')) print('F1:', f1_score(df=scored_snowml_sdf, y_true_col_names='RATING', y_pred_col_names='PREDICTION'))

Model 2: XGBClassifier
We’ll follow the same steps as before but now with the ‘XGBClassifier’ model:
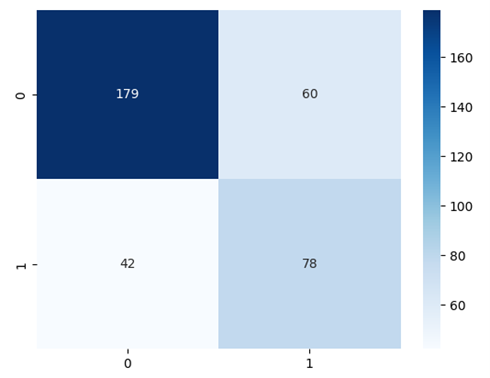
from snowflake.ml.modeling.xgboost import XGBClassifier from snowflake.ml.modeling.metrics import * feature_cols = train_sdf.columns feature_cols.remove('RATING') target_col = 'RATING' xgbmodel = XGBClassifier( random_state=0, input_cols=feature_cols, label_cols=target_col, output_cols=['PREDICTION'] ) xgbmodel.fit(train_sdf) # Obtaining and plotting a simple confusion matrix from snowflake.snowpark.functions import udf session.custom_package_usage_config = {"enabled": True} scored_snowml_sdf_xgboost = xgbmodel.predict(test_sdf) cf_matrix_xgboost = confusion_matrix(df=scored_snowml_sdf_xgboost, y_true_col_name='RATING', y_pred_col_name='PREDICTION') sns.heatmap(cf_matrix_xgboost, annot=True, fmt='.0f', cmap='Blues') # Printing the metrics print('Acccuracy:', accuracy_score(df=scored_snowml_sdf_xgboost, y_true_col_names='RATING', y_pred_col_names='PREDICTION')) print('Precision:', precision_score(df=scored_snowml_sdf_xgboost, y_true_col_names='RATING', y_pred_col_names='PREDICTION')) print('Recall:', recall_score(df=scored_snowml_sdf_xgboost, y_true_col_names='RATING', y_pred_col_names='PREDICTION')) print('F1:', f1_score(df=scored_snowml_sdf_xgboost, y_true_col_names='RATING', y_pred_col_names='PREDICTION'))
Displayed below are the confusion matrix and the metrics results:

Model 3: GradientBoostingRegressor
For our final training, we will use the scikit-learn GradientBoostingRegressor package. To integrate this package, we have to transform our train and test data into pandas format:
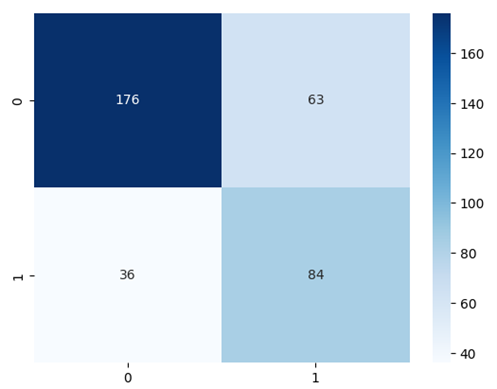
from sklearn.ensemble import GradientBoostingRegressor train_pd = train_sdf.to_pandas() y_train = train_pd.loc[:,'RATING'] x_train = train_pd.loc[:,train_pd.columns != 'RATING'] gbm_model = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=1, random_state=0, loss='squared_error') gbm_model.fit(x_train, y_train) # Obtaining and plotting a simple confusion matrix from snowflake.snowpark.functions import udf from sklearn.metrics import confusion_matrix session.custom_package_usage_config = {"enabled": True} predict_values = test_sdf.to_pandas().loc[:,test_sdf.to_pandas().columns != 'RATING'] y_test =test_sdf.to_pandas().loc[:,'RATING'] y_predict = abs(np.around(gbm_model.predict(predict_values),0)) cf_matrix_gbm = confusion_matrix(y_test,y_predict) sns.heatmap(cf_matrix_gbm, annot=True, fmt='.0f', cmap='Blues') from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score print('Acccuracy:', accuracy_score(y_test,y_predict)) print('Precision:', precision_score(y_test,y_predict)) print('Recall:', recall_score(y_test,y_predict)) print('F1:', f1_score(y_test,y_predict))
Here are the confusion matrix and the metrics results:

Using Model Registry to Deploy ML Models
Now that our machine learning models have been trained, we will use the new Model Registry feature. As an integral component of Snowpark ML Operations (MLOps), this feature acts as a secure hub for managing models and their associated metadata within Snowflake, irrespective of their origin. This cutting-edge feature elevates machine learning models to the status of first-class schema-level objects in Snowflake, facilitating easy discovery and utilisation across your organisation. With Snowpark Model Registry, you can establish registries and seamlessly store models, harnessing the ML capabilities of the platform.
The models stored within the registry can have multiple versions, and you can designate a specific version as the default. Another advantage is that it supports different types of models (besides Snowpark ML), like scikit-learn, PyTorch or TensorFlow, so you can create different models and use different packages, but keep them together in the same object.
Let’s get back to our demo and register the three trained models using Model Registry. We will start by creating our registry object:
from snowflake.ml.registry import Registry session = snp.Session.builder.configs(state_dict["connection_parameters"]).create() reg = Registry(session=session, database_name=state_dict['connection_parameters']['database'], schema_name=state_dict['connection_parameters']['schema'])
Using this code, we created a model object inside our schema where we will register our machine learning models.
It is important to note than even though the model object is created, it will not be shown as a schema object in Snowflake (as, for example, Tables, Stages or Procedures are):
Now we can register our first model ‘LogisticRegression’:
model_ref = reg.log_model( lr, model_name="LogisticRegression", version_name="v1", comment = "First version of LogisticRegression for JUICES_RATINGS", #optional metrics = {"Accuracy": 0.74} #optional )
When registering a model, only ‘model’, ‘model_name’ and ‘version’ are required arguments. However, we can also add a comment for the model and some specific metrics (in dictionary format). To get more information about model registry arguments, check the Snowflake documentation.
Now that we’ve registered the model, we can open an SQL sheet in Snowflake and use the following SQL code to check our registered models:

Now we’ll add the other two models we trained:
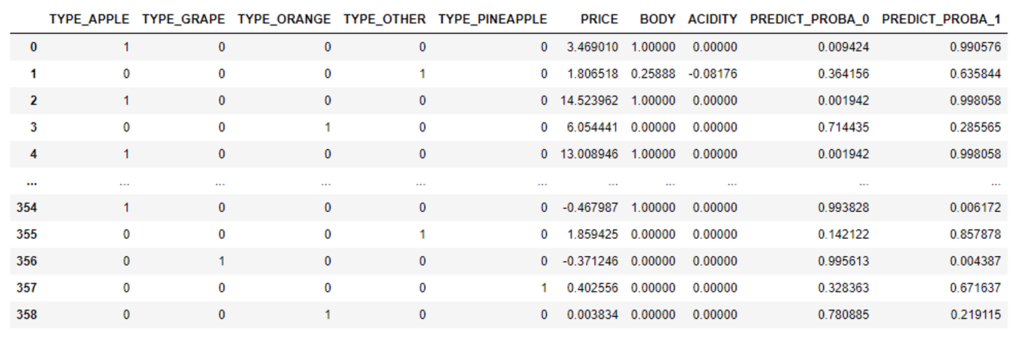
# Registering XGBMODEL model_ref = reg.log_model( xgbmodel, model_name="XGBClassifier", version_name="v1", comment = "First version of XGBClassifier for JUICE_RATINGS", #optional metrics = {"Accuracy": 0.71} #optional ) # Regsitering GBM model: For sklearn model it is needed to add the sample_input_data argument sample_values = test_sdf.to_pandas().loc[:,test_sdf.to_pandas().columns != 'RATING'] model_ref = reg.log_model( gbm_model, model_name="GBM", version_name="v1", sample_input_data=sample_values, comment = "First version of GradientBoostingRegressor for JUICE_RATINGS", #optional metrics = {"Accuracy": 0.72} #optional )
For all models other than Snowpark ML and MLFlow, the ‘sample_input_data’ or ‘signatures’ arguments must be added. These arguments are to extract the feature names and types used in the model.
Now let’s check that our models are registered in our schema:
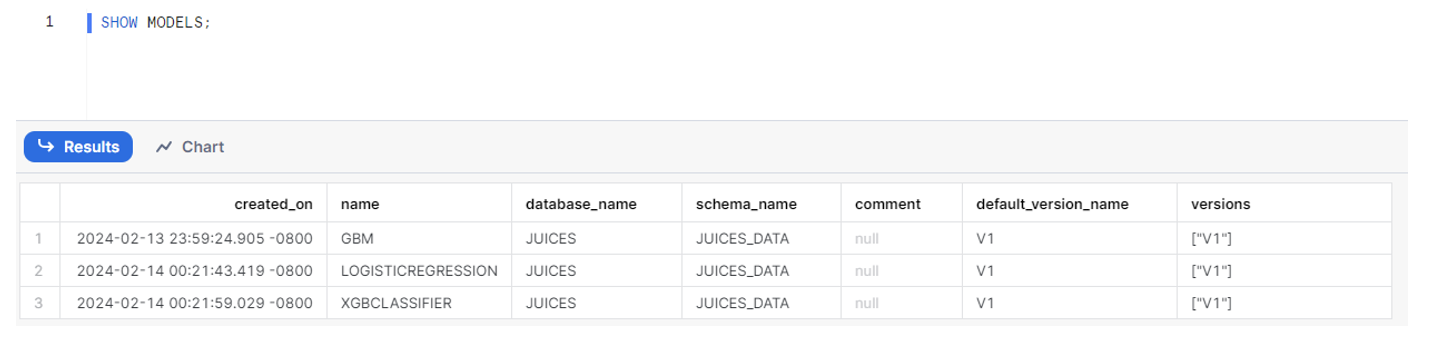
Since models are first-class, schema-level objects within Snowflake, SQL commands like DROP MODEL, SHOW MODELS, and ALTER MODEL are available for managing them.
Another important aspect when registering models is the requirement for each model to have a unique combination of name and version, distinct from those already registered. An error will occur if this condition is not met:

Using Model Registry for Inference
With our models now successfully registered, we are ready to utilise these model objects for predictive tasks. A notable advantage offered by Model Registry is its inherent flexibility, enabling users to easily select the desired model for use. To illustrate this, let’s start making predictions using our registered models, beginning with the creation of our model object in Jupyter:
from snowflake.ml.registry import Registry model = Registry(session=session, database_name=state_dict['connection_parameters']['database'], schema_name=state_dict['connection_parameters']['schema'])
Initiating a method from a specific model version is done via the ‘.run()’ method. This involves specifying the name of the function to be called and providing a DataFrame containing the inference data. This method is executed within a Snowflake warehouse. Let’s look at an example of this process by applying it to the ‘LogisticRegression’ model:
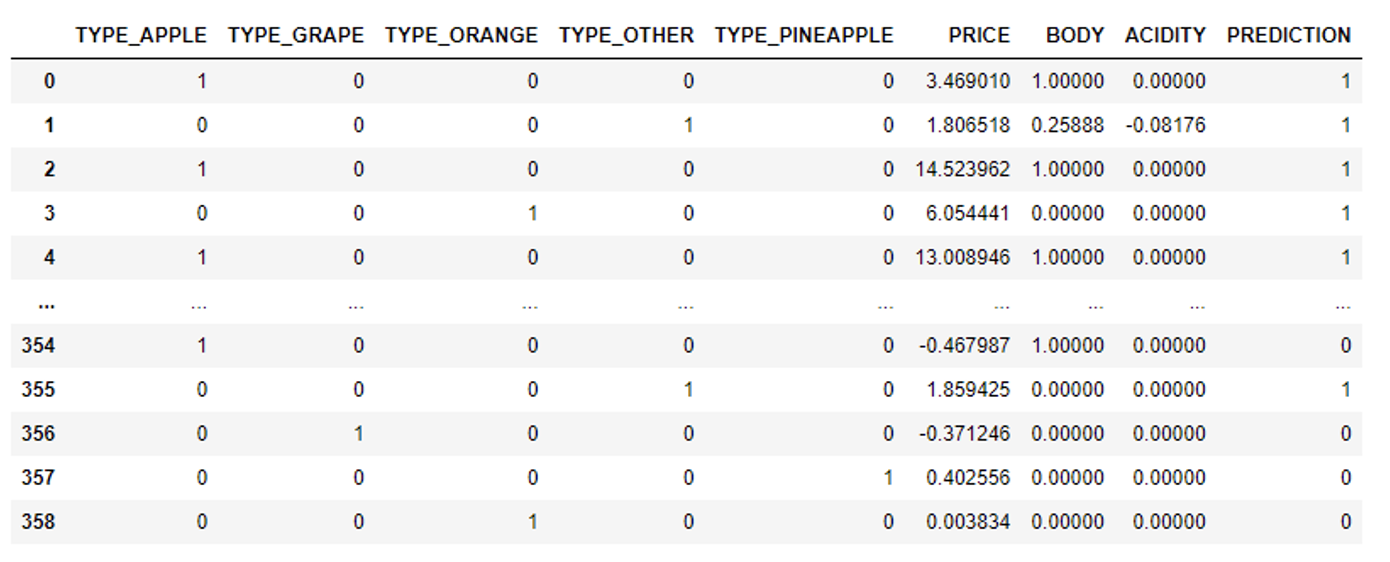
#Using LogisticRegression Model LogReg = model.get_model("LogisticRegression").version("v1") test_values = test_sdf #test values must be in snowflake table format #We run the predict function LogReg.run(predict_values,function_name='predict')
We obtain this DataFrame containing the prediction as a result:
Now, if we want to select the ‘XGBClassifier’ model, we only have to change the desired model in our object, given that the test data is already in Snowpark table format:
#Using XGBClassifier Model XGBClass = model.get_model("XGBClassifier").version("v1") #We run the predict function XGBClass.run(predict_values,function_name=)
Finally, we will use the ‘GBM’ function. As this model was created using sklearn, it’s necessary to use a pandas DataFrame for the test data. The ‘predict’ function employed here is from sklearn, not Snowpark, which is why the output DataFrame differs from the previous ones:
#Using GBM Model gbm = model.get_model("GBM").version("v1") #Test values must be in pandas dataframe test_values = test_sdf.to_pandas().loc[:,test_sdf.to_pandas().columns != 'RATING'] gbm.run(predict_values,function_name='predict')
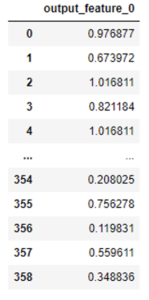
Another exceptional feature of Model Registry is its wide range of prediction functions, extending beyond the conventional ‘predict’ method. For instance, the ‘XGBClassifier’ model can seamlessly substitute ‘predict’ with the ‘predict_proba’ function. This introduces an additional layer of flexibility for data scientists, empowering them to customise predictions to meet specific needs:
#We run the predict_proba function XGBClass.run(predict_values,function_name='predict_proba')
From this registry we can get other information, like metrics, comments, or other registered model metadata.

Creating A Function to Register Our Models
Having explored some of the key functionalities of Model Registry, it’s not difficult to get an idea of its immense capabilities, and the toolkit for creating functions to train, fine-tune, store, and manage various ML models is extensive. Imagine crafting a function capable of training an ‘XGBoost’ model with any given dataset, a function that not only calculates metrics but also facilitates the storage of the model, metrics, and associated metadata within our designated schema object in the Snowflake database. The code snippet below is a good example of this comprehensive functionality, highlighting the versatility and efficiency of Model Registry’s offerings:
# Arguments definition session = snp.Session.builder.configs(state_dict["connection_parameters"]).create() feature_cols = train_sdf.columns.remove('RATING') target_col = 'RATING' output_cols = ['PREDICTION'] train_data = "DATA_TRAIN" test_data = "DATA_TEST" random_state = 0 database_name = state_dict['connection_parameters']['database'] schema_name = state_dict['connection_parameters']['schema'] model_name = "XGB_CLASSIFER_FROM_FUNCTION" version_name = "V4" commentary = "model de prueba para la funcion xgboost_model_registry" # Creation of the function def xgboost_model_registry(session: snp.Session, feature_cols: list, target_col: str, output_cols: list, train_data: str, test_data: str, random_state: int, database_name: str, schema_name: str, model_name: str, version_name: str, comment: str = "" )-> T.Variant: import snowflake.snowpark as snp from snowflake.ml.modeling.xgboost import XGBClassifier from snowflake.ml.modeling.metrics import accuracy_score, precision_score, recall_score, f1_score data_train = session.table(train_data) data_test = session.table(test_data) # We create the XGBClassifier Model xgbmodel = XGBClassifier( random_state=random_state, input_cols=feature_cols, label_cols=target_col, output_cols=output_cols ) xgbmodel.fit(data_train) #Predicted values using test_data predicted_test = xgbmodel.predict(data_test) # Metrics of the trained XGBClassifier model acc = accuracy_score(df=predicted_test, y_true_col_names=target_col, y_pred_col_names=output_cols[0]) precision = precision_score(df=predicted_test, y_true_col_names=target_col, y_pred_col_names=output_cols[0]) recall = recall_score(df=predicted_test, y_true_col_names=target_col, y_pred_col_names=output_cols[0]) F1 = f1_score(df=predicted_test, y_true_col_names=target_col, y_pred_col_names=output_cols[0]) print('Acccuracy:', acc) print('Precision:', precision) print('Recall:', recall) print('F1:', F1) #Model Registry from snowflake.ml.registry import Registry reg = Registry(session=session, database_name=database_name, schema_name=schema_name) model_ref = reg.log_model( xgbmodel, model_name=model_name, version_name=version_name, metrics={"Accuracy": acc, "Precision":precision, "Recall":recall, "F1":F1}, comment=comment ) return "Model successfully registered" # Now we call our function xgboost_model_registry(session,feature_cols, target_col, output_cols, train_data, test_data, random_state, database_name, schema_name, model_name, version_name, commentary)
As we can see in our Snowflake schema, the new model has successfully been trained and registered in Snowflake, along with the metrics and the comment:
The possibilities are immense. We could introduce new commands to choose between various ML models, incorporate diverse cross-validation methods, and add arguments for hyperparameter tuning, while keeping all that information inside the same object in our Snowflake database. What’s more, once these configurations have been set up, they can be incorporated into standard procedures, allowing seamless invocation within Snowflake and also facilitating integration into broader workflows. Model Registry’s functionality provides a robust framework for tailoring and orchestrating sophisticated ML processes.
Calling Model Methods in SQL
In earlier sections, we demonstrated how to use a registered model for inference with Python. However, Model Registry offers another remarkable capability: it can be leveraged not only in Jupyter notebooks but also within SQL environments. To call a model, employ the following code:

To invoke a specific version, you’d need to use an alias, like this:

Let’s look at some examples using our registered models. Imagine we need to use our ‘XGBClassifier’ model to get predictions using our ‘data_test’ table saved in Snowflake. We can use the following code:
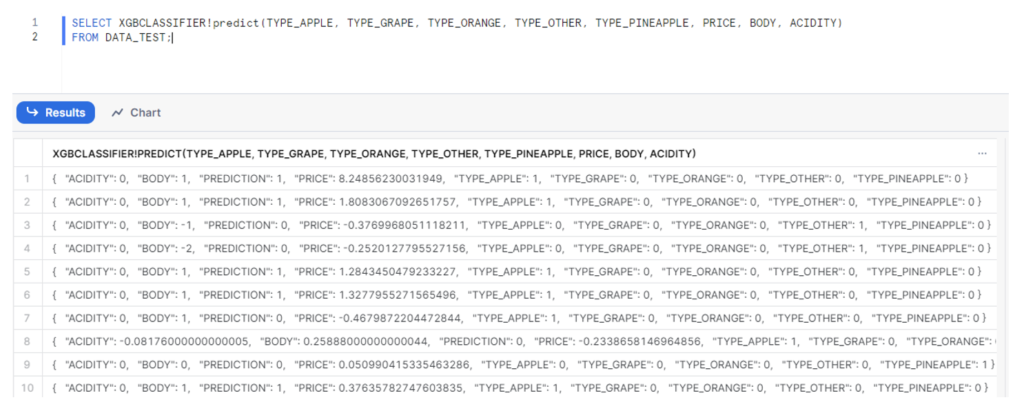
As you can see, we have to specify the names of our input variables within the method, such as ‘predict()’. This method generates a JSON output, where predictions for each row are sorted alphabetically. However, if we’d prefer to retrieve only the prediction value instead of the entire JSON response, we can simply select ‘:PREDICTION’ in our statement:
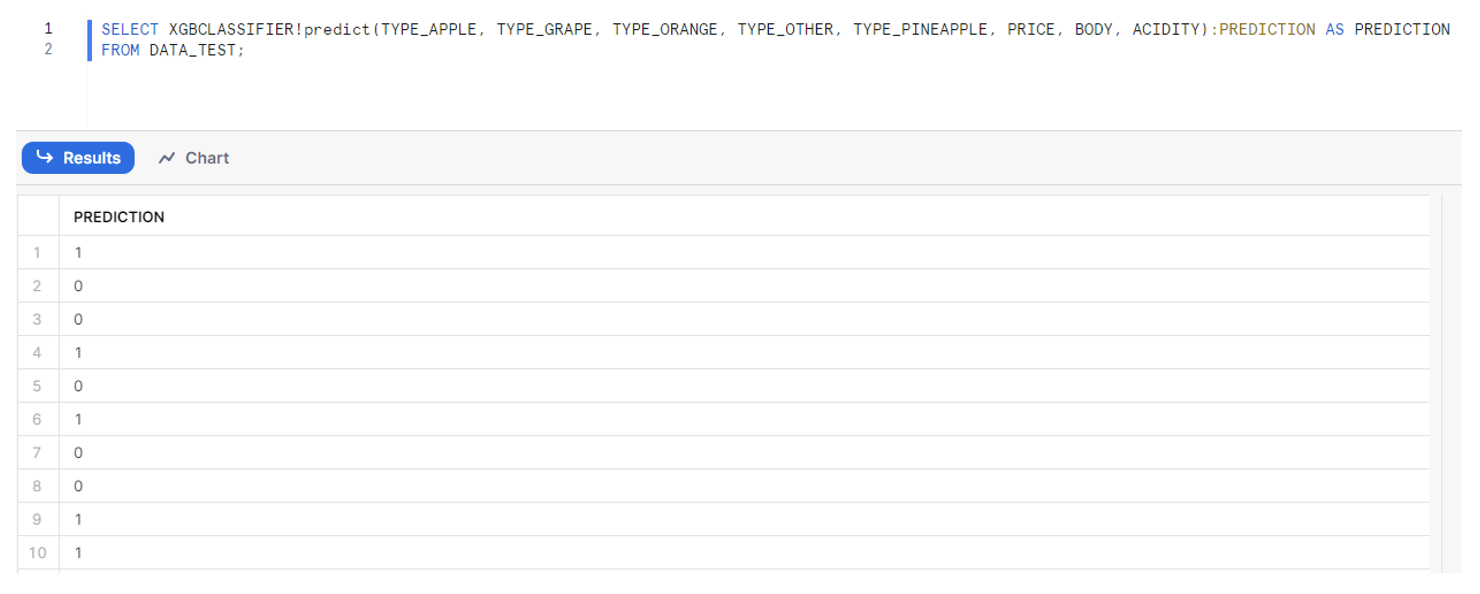
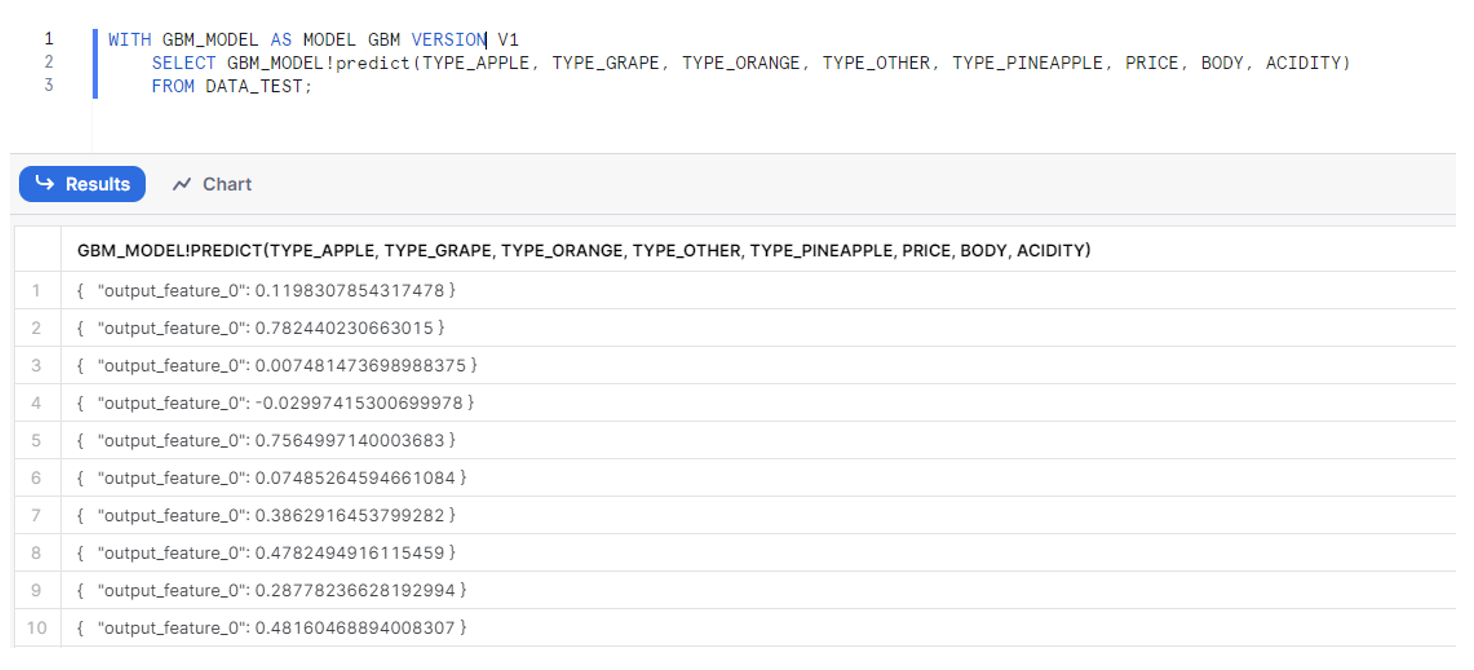
Now, we will employ the ‘GBM’ model using the ‘with model’ code structure, enabling the selection of any version of the specified model. It’s important to note that this ‘GBM’ model was generated from the sklearn library, so the table result produced by the ‘predict()’ function will differ from the one before, which was created using Snowflake ML.
Conclusions
In addition to its rich array of functions tailored for data transformation, Snowpark offers a wide range of capabilities for training machine learning models, going far beyond its native ML package. Able to integrate seamlessly with well-known libraries like scikit-learn, Snowpark lets data scientists leverage their preferred tools and methodologies, ensuring compatibility and interoperability with existing workflows. This versatility not only enhances the platform’s appeal but also reinforces its position as a comprehensive solution for ML model development within the Snowflake environment.
The introduction of the Model Registry object within Snowflake is a paradigm shift in model management. This feature not only modernises the registration, organisation, and versioning of ML models but also facilitates the incorporation of diverse packages outside Snowpark’s native offerings. It is important to highlight Model Registry’s integration with the inference process, facilitating swift model swaps for predictive tasks while also significantly enhancing agility and efficiency in model deployment. Moreover, the schema-object nature of Model Registry opens the door to seamless integration within SQL queries, adding another layer of flexibility and ease of use to the model management workflow.
In conclusion, the combination of Snowpark and the Model Registry object presents a compelling solution for end-to-end machine learning model development and deployment within the Snowflake ecosystem, positioning organisations for even greater success in their data-driven initiatives. Reach out to our team of dedicated experts, ready to harness Snowflake’s powerful ecosystem to drive innovation and transform data strategies into actionable success stories for you!
